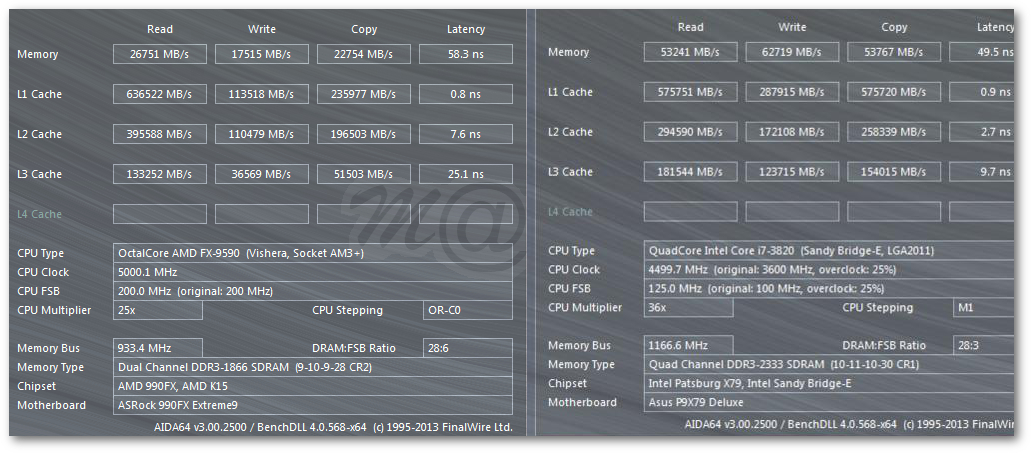
I think you're mistaken somewhat here. The 4 IPC is a best case, 'up-to', with low IPC workloads.
Of course it is an 'up-to' - the same applies to Intel's Skylake, except it can, at times, do up-to five instructions thanks to macro-op fusion. However, Intel sometimes creates four uops from one x86 instruction, so that should effectively level the playing field in that regard.
Fetch/Decode are both shared between 2 cores in a module.
Correct, which only matters when both cores are active. One active core can use all of the front-end resources. Skylake can have two threads running on the same front-end resources as well... the fact that it is just one core means only very little.
The instruction fetch unit handles the task of interpreting a couple of idle and power state features and loads the pick buffer accordingly. If an instruction exists for both threads/cores, they will end up in different lines (adjacent, alternating) of the pick buffer which results in the decoders working on a different thread's instructions every other cycle when both cores are fully loaded with non-idle instructions.
L1I line is 64B so a single fetch takes 2 cycles because it's 32B a time into IBB.
Still 32B/cycle... also, the L1 code cache (L1I) comes before the instruction fetch, so irrelevant (unless it was unable to sustain the 32B/cycle the decoders can chew through).
An IBB per core but that dispatch window of 16B to the decode is shared.
There is a 32B bus to the decoders, not 16B. There are many issues with alignment, though, and Bulldozer actually has what - I can only assume - is an implementation bug that results in linear code on one thread maxing out at 21B/clock. That was fixed in Piledriver... and you see the impact that made
🙄
With multi-core execution, more often than not, you'll find only 1 of the fetches being decoded per module.
No, not at all. The 32B pick buffer lines/entries are filled with alternating instructions when both cores are active.
The effect is that each core has all four decoders every other cycle, and averages to 16B/cycle when both cores are fully loaded.
Pick Buffer lines
[0] CORE 0 - 32B
[1] CORE 1 - 32B
[2] CORE 0 - 32B
[3] CORE 1 - 32B
However, this is a common scenario:
[0] CORE 0 - 32B
[1] CORE 0 - 32B
[2] CORE 1 - 32B (idle set, power state set)
[3] CORE 0 - 32B
And any combination thereof...
BD isn't a true 4-wide design due to the heavy sharing. Hence, increase the threads executing and decode bandwidth drops. It's not 4 per thread anymore but 4 per 2 cores.
Each core is 4-wide, and the pathways are all 4-wide. You just share the front-end between two cores every other cycle. The impact of this is well studied - about 15% performance cost per core when both cores are fully loaded.
And, Zen will not have any of these issues. It has the full capabilities, and more, for every core.
And we know that Bulldozer's front-end can do better with Sandy Bridge's even with those issues, it just requires both cores to be running as Bulldozer is ALU starved.
If you take a good close look at how Bulldozer was designed, it appears that AMD intended to be able to issue integer instructions from one thread onto both cores. This would have been a nice boost to single threaded performance, and CMT would bring a 50% gain, instead of an ~85% gain. It seems they abandoned that effort at some point during the design.