
looncraz
Senior member
- Sep 12, 2011
- 722
- 1,651
- 136
Decent, but not good enough compared to Intels. Run some branchy bench you know of and use CodeAnalyst to check the misprediction rates. I'll run the same with Intel Skylake.
You make the project, I'll run it on three different systems (Excavator, Sandy Bridge, Deneb).
Excavator's branch prediction rates seem like they should be better than Sandy Bridge, judging by Agner's comments.
http://www.agner.org/optimize/microarchitecture.pdf
Pages 28 & 33
I disagree that it's just cache and the rest was equally matched to Intel.
Not what I'm saying at all, I'm just comparing Zen to the Construction cores. AMD does have areas where it has been stronger than Intel - and Zen looks to attempt to exploit that. Zen+ looks to double down on that strategy (if the 15% boost is to be believed).
Slow cache is also a major oversimplification - it's ways, it's how many accesses per line can be made simultaneously, it's the latency and bandwidth with cache contention.
I wouldn't call it an oversimplification - all the things you said make a cache slow. Slow != bandwidth alone. Slow comes in terms of latency, throughput, and any combination thereof... and nearly everything is tied to the performance of the caches one way or another.
If Excavator had even Sandy Bridge level caches, things would be a lot different.
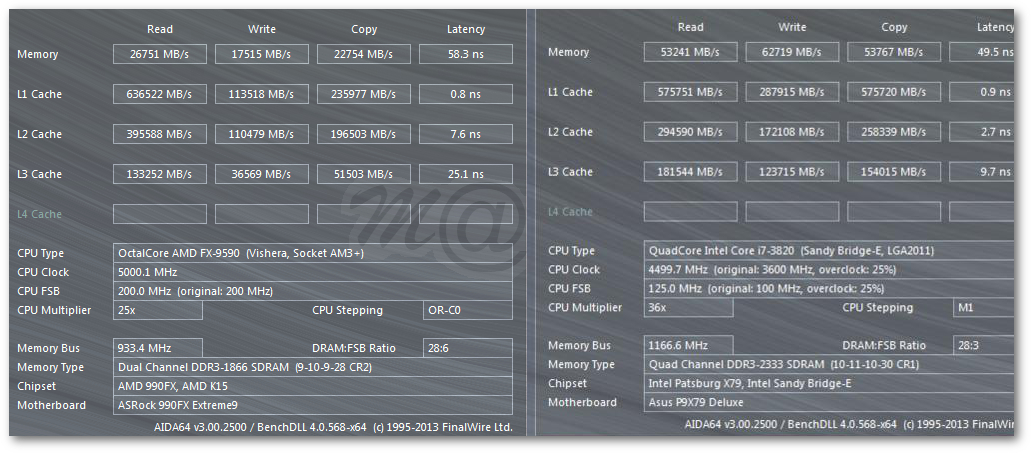
Oh, and that's 5Ghz Bulldozer vs 4.5Ghz Sandy Bridge.
Last edited:

