- Oct 22, 2004
- 805
- 1,394
- 136
Hi all, it has been some exciting months in the CPU space since the Ryzen launch, with more to come before year end. However, I am already very curious about how AMD will evolve the Zen core with the upcoming 7nm Zen 2 next year — in particular how the CCX will be configured.
There is a similar topic and poll over at SemiAccurate, in which there are more votes for 6 cores per CCX. However, here I will argue for staying with 4 cores per CCX, on the grounds of interconnect topology.
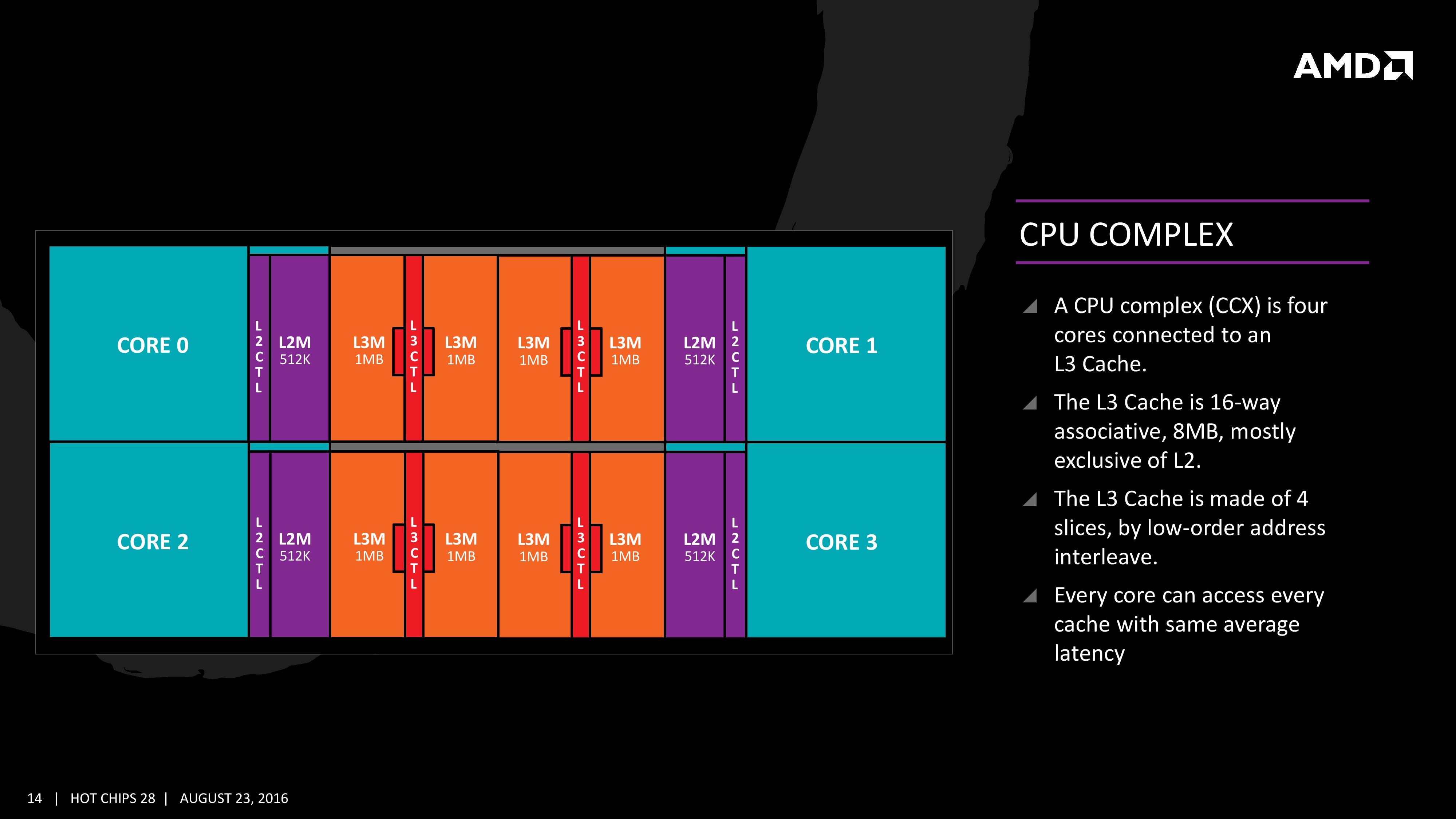
First, 6 cores per CCX seems so un-zen-like. In the current generation Zen, the 4 cores in the CCX are directly connected (c = 6). Directly connecting 6 cores seems infeasible, as the number of links grows quadratically (c = n*(n-1)/2), thus requiring a suboptimal topology (e.g. ring or mesh). Also, 4 cores per CCX is a nice partition size (e.g. for virtualization), with one memory controller per CCX.
Currently, using the new Infinity Fabric, AMD arranges the Zen cores in direct-connected clusters (CCX) on direct-connected dies within the CPU package. The CPUs on a 2-socket PCB are also direct-connected. Notably, the die-to-die connection across CPUs is not done using switching. Instead, a die in CPU 0 is direct-connected to the corresponding die in CPU 1, forming a sparsely connected hyper-cube (see "The Heart Of AMD’s EPYC Comeback Is Infinity Fabric").
Taking this hierarchical direct-connect approach to the extreme, it leads to the following "quad-tree" topology with room for up to 4 CCXs per die (drawn here for two sockets — although it can naturally scale to 4 direct-connected sockets).
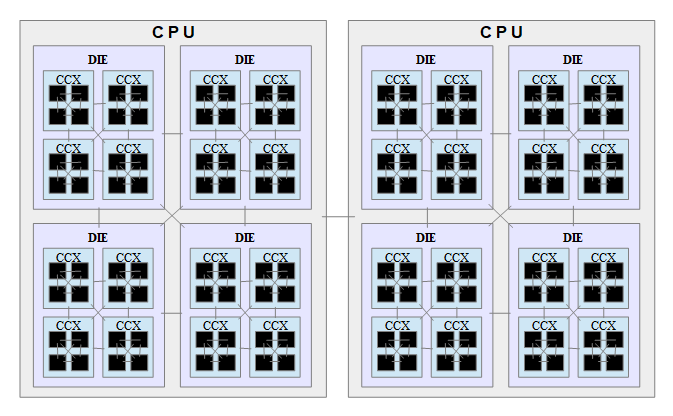
Note that the links between clusters are fat links, i.e. consist of a set of links between corresponding cores in each cluster. No switches are involved. E.g. between CCXs, core 0 in CCX 0 is direct-connected to core 0 in CCX 1. Similarly, the link between CPUs consists of the set of links between corresponding cores in each CPU. This arrangement means that there is max log4(n) number of hops between any core in a n-core system. For example, to go from core 0-0-0-0 (core 0 in CCX 0 in die 0 in CPU 0) to core 1-2-3-1, you first make a hop within the CCX to core 1-0-0-0, then cross-CCX to core 1-2-0-0, then cross-die to core 1-2-3-0, and finally, cross-socket to core 1-2-3-1.
The following table shows the required number of links (point-to-point connections).

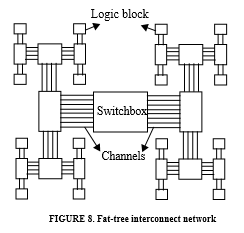
For this 2-socket configuration, note that 10 ports are needed per core (a 4-socket configuration would require 12 ports per core). Is this feasible? If not, a lower number of ports and wires can be achieved by introducing switches at each hierarchical level (i.e. multiplex the logical point-to-point connections over fewer wires). This then becomes a fat tree topology (e.g. used in supercomputers).
I am, by no means, an expert on interconnects, so if any of you have any background, I would love to hear your views on this, and how Infinity Fabric is likely to be used in the future to scale up systems.
PS. But three CCXs for a 12 core die make an awkward die layout, right? Well, GlobalFoundries' 7nm process (7LP) has "more than twice" the density at "30% lower die cost". Why not go for 3+1 — three CCXs and one GCX (GPU Complex), all fully connected. Then, as with the current approach for EPYC, put 4 of these dies together on an MCM, also fully connected, and you have the rumoured 48 CPU cores for EPYC 2, plus 4 times whatever number of graphics compute cores in a GCX. This configuration also chimes with the "HSA Performance Delivered" point on AMD's old roadmap (under "High-Performance Server APU").
There is a similar topic and poll over at SemiAccurate, in which there are more votes for 6 cores per CCX. However, here I will argue for staying with 4 cores per CCX, on the grounds of interconnect topology.
First, 6 cores per CCX seems so un-zen-like. In the current generation Zen, the 4 cores in the CCX are directly connected (c = 6). Directly connecting 6 cores seems infeasible, as the number of links grows quadratically (c = n*(n-1)/2), thus requiring a suboptimal topology (e.g. ring or mesh). Also, 4 cores per CCX is a nice partition size (e.g. for virtualization), with one memory controller per CCX.
Currently, using the new Infinity Fabric, AMD arranges the Zen cores in direct-connected clusters (CCX) on direct-connected dies within the CPU package. The CPUs on a 2-socket PCB are also direct-connected. Notably, the die-to-die connection across CPUs is not done using switching. Instead, a die in CPU 0 is direct-connected to the corresponding die in CPU 1, forming a sparsely connected hyper-cube (see "The Heart Of AMD’s EPYC Comeback Is Infinity Fabric").
Taking this hierarchical direct-connect approach to the extreme, it leads to the following "quad-tree" topology with room for up to 4 CCXs per die (drawn here for two sockets — although it can naturally scale to 4 direct-connected sockets).
Note that the links between clusters are fat links, i.e. consist of a set of links between corresponding cores in each cluster. No switches are involved. E.g. between CCXs, core 0 in CCX 0 is direct-connected to core 0 in CCX 1. Similarly, the link between CPUs consists of the set of links between corresponding cores in each CPU. This arrangement means that there is max log4(n) number of hops between any core in a n-core system. For example, to go from core 0-0-0-0 (core 0 in CCX 0 in die 0 in CPU 0) to core 1-2-3-1, you first make a hop within the CCX to core 1-0-0-0, then cross-CCX to core 1-2-0-0, then cross-die to core 1-2-3-0, and finally, cross-socket to core 1-2-3-1.
The following table shows the required number of links (point-to-point connections).
For this 2-socket configuration, note that 10 ports are needed per core (a 4-socket configuration would require 12 ports per core). Is this feasible? If not, a lower number of ports and wires can be achieved by introducing switches at each hierarchical level (i.e. multiplex the logical point-to-point connections over fewer wires). This then becomes a fat tree topology (e.g. used in supercomputers).
I am, by no means, an expert on interconnects, so if any of you have any background, I would love to hear your views on this, and how Infinity Fabric is likely to be used in the future to scale up systems.
PS. But three CCXs for a 12 core die make an awkward die layout, right? Well, GlobalFoundries' 7nm process (7LP) has "more than twice" the density at "30% lower die cost". Why not go for 3+1 — three CCXs and one GCX (GPU Complex), all fully connected. Then, as with the current approach for EPYC, put 4 of these dies together on an MCM, also fully connected, and you have the rumoured 48 CPU cores for EPYC 2, plus 4 times whatever number of graphics compute cores in a GCX. This configuration also chimes with the "HSA Performance Delivered" point on AMD's old roadmap (under "High-Performance Server APU").
Last edited: