The answer to this question was revealed some time ago in a SemiAccurate article.
LOLZ, care too share?

The answer to this question was revealed some time ago in a SemiAccurate article.
The cores in a single CCX is not connected using IF, IF is used to connect multiple CCXs
The most likely option is 6 core CCX. The primary advantage would be that a Ryzen APU could incorporate a single 6 core CCX and avoid the cross CCX communication penalty.
If they use 4 core CCX like now, what are they going to do with all that extra space?
[6 dies per socket] is simply unworkable and would also be incompatible with Epyc's dual sockets systems that currently link the four dies between each chip.
6 core CCX would make more sense for the desktop CPUs higher than R3
For 48 cores on epyc they need to upgrade within the ccx for that to work right?
I still don't understand, why can't they just put 3 CXX'is on a chip. Mapping them to memory should be way easier than interconnecting 6 cores within a CXX
Inserting 2 more cores into the middle of the current floorplan would seem to be the best choice for reorganizing the L3$ interconnects within a CCX.
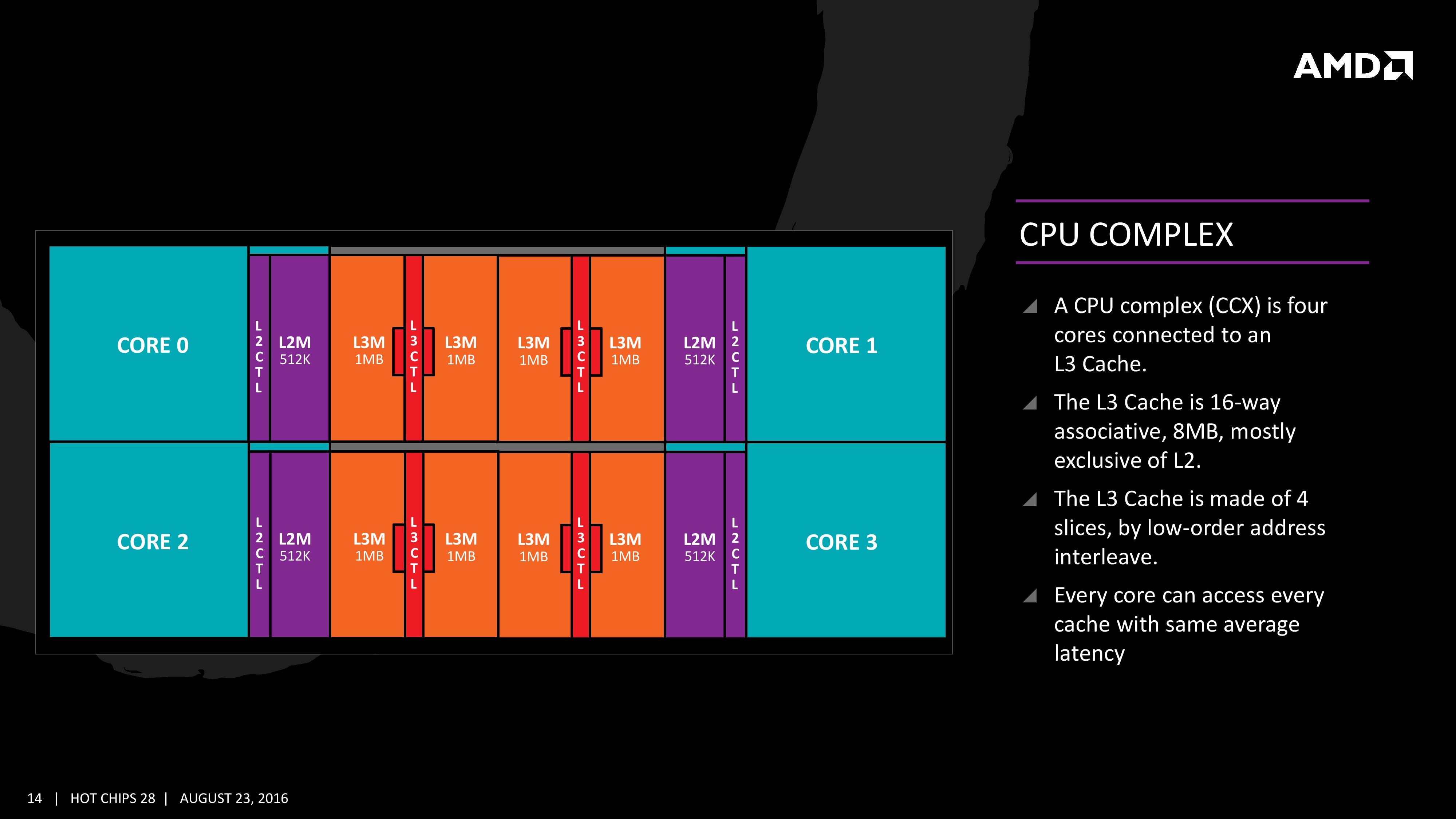
all 4 cores have their own link to each 4 L3 slices, all intercore communication goes through the L3. This means that there are currently 16 links.
I predict that the professional high end server versions (and some HEDT) will be 8 core CCX in the upcoming years to come.
I think that they'll stick with a 4-core CCX and make improvements to the core itself,
I suspect that when AMD does change the CCX, they go to an 8-core design but won't have direct connections between all cores.
Plenty for them to do already. Refining and cleaning up their uarch. Pick the low hanging fruit. Pick up some IPC.
My bad, totally forget about Starship. The 6 core CCX makes sense now.
But they can keep basically the same performance by doing a triangle three CCX's. [...] Whereas if they do 4 or more CCX's they would either have increased latency like the ring bus, or dramatically increase IF connections.
Thanks for the replies!
My poll started off great with a majority in my direction (4 cores per CCX). However, it now has flipped with a majority for 6 cores per CCX. The answer is of course known to some (by insiders and those with information from pay-walled reports). However, I'd still like to see better argumentation for going with 6-cores per CCX.
In benchmarks, we see that the cross-CCX latency does not matter much for most parallel workloads. And for those workloads where latency matters, most seem to run well on 4 cores (e.g. traditional single-threaded workloads, games). Workloads that need low latency over many cores are rare, I guess, and often a sign of poor programming that does not scale well (many threads contending for shared memory/locks).
So why prioritise low cross-CCX latency to the detriment of cross-core latency within a CCX?
Why is that the best choice? It is sub-optimal. By increasing the core count per CCX, you can no longer feasibly direct-connect the cores (6*5/2 = 15 links!). Why take the penalty when they can do 3 x 4-core CCX instead?
Agree. There are many things that can be done to improve the 4-core CCX. For example, widen the core, thereby increasing the IPC, then add 4-thread SMT to exploit it through parallelism (16 threads per CCX). This would add threads without complicating the core interconnect.
Again, why complicate the interconnect within a CCX when you can double the number of CCXs instead?
Agree. Probably there are lots of low hanging fruit. Then, for the future, like I mentioned above, e.g. go for a wider core with 4-thread SMT, but keep the CCX simple.
Four CCXs can easily be direct-connected (4*3/2 = 6 links), but beyond that you are right. For more than 4 CCXs on a die, you would need to group by (max) 4 again, e.g. clusters of 4, assuming we are adhering to the hierarchical direct-connect topology I outlined.
Again, that would require a sub-optimal interconnect topology. Why not double the number of CCXs instead? Why complicate the CCX? Do you think cross-CCX latency is such a problem that increasing complexity and cross-core latency within the CCX is worth it?
A server cpu can be much more expensive and as such a more complex layout can be accounted for.
in time, Intel is going to have enough experience with their new mesh design to be even further ahead than they are now
That picture of spacebeer is very interesting. But i have always understood that the [Infinity Fabric] links are used between CCX themselves and not in the interCCX core communication.
I have always understood that the inter core communication happens through the L3 cache directly.
From your first link.A server cpu can be much more expensive and as such a more complex layout can be accounted for.
I agree that server or datacenter software is more likely to be optimized for the NUMA model from AMD.
But in time, Intel is going to have enough experience with their new mesh design to be even further ahead than they are now (Which is not that far, but they do have the financial situation advantage.)
And i think AMD will go to 8 CCX for server cpu because of the competitive pressure from Intel that will come.
That picture of spacebeer is very interesting. But i have always understood that the DF links are used between CCX themselves and not in the interCCX core communication.
I have always understood that the inter core communication happens through the L3 cache directly.
AMD has mentioned that infinity fabric in general can be used on chip as well from die to die. But that is more from gpu to cpu like on an APU.
The picture of space beer has a direct connection Between the cores but it is mentioned in the Anandtech article that the L3 cache latency on average is the same.
This gives to suspect that the cores in a CCX are connected as hops and not directly through a cross connection in the center.
"
Each core will have direct access to its private L2 cache, and the 8 MB of L3 cache is, despite being split into blocks per core, accessible by every core on the CCX with ‘an average latency’ also L3 hits nearer to the core will have a lower latency due to the low-order address interleave method of address generation.
"
But i am not up to date to be honest. Because i am still trying to understand with what this exactly means.
As a sidenote:
I am still wondering why a 3 core like the 1600X has much lower cache latency while the 1600, also a 3 core has not.
It must be a fluke that has been copied from site to site.
And why the 1500x , also with 8MB cache per CCX but only 2 functional cores has not.
I am confused.
I have been reading through this material from AMD themselves to educate myself, but have not found anything conclusive.
http://www.anandtech.com/show/11170...-review-a-deep-dive-on-1800x-1700x-and-1700/9
http://support.amd.com/TechDocs/54945_PPR_Family_17h_Models_00h-0Fh.pdf
http://support.amd.com/TechDocs/55723_SOG_Fam_17h_Processors_3.00.pdf

Still, that is not the issue. Direct connections are optimal. And currently the cores in a 4-core CCX are directly connected. No other topology can beat direct-connections. So to argue for a 6-core CCX you'll have to argue why increasing core-to-core latency is a good thing, since a 6-core CCX will presumably need a sub-optimal topology (e.g. mesh or ring). Also note that, in a chip with more than one CCX, you'll always have cross-CCX latency, even with a 6-core CCX. So to argue for a 6-core CCX on grounds of latency, you'll have to show that it lowers latency for the system overall.
Direct-connections are optimal. There is no way to beat it. Perhaps a 8-core Intel mesh has lower average latency than a 2 x 4-core CCX. However, if a workload fits in a CCX, it will always have lower core-to-core latency due to direct-connections. So it will be a trade-off. Again, to argue for a 6-core CCX (or a 8-core CCX) you'll have to argue that it lowers latency overall for the workloads that matter.

Of course infinity fabric is a protocol but it is also a physical implementation.The kind of link is not material (Infinity Fabric is just a protocol). The point is, as shown by Spacebeer's drawing, that the cores are directly connected. The drawing shows the topology and the numbers of links required to directly connect cores.
[/QUOTE]Like I wrote in my last post, the L3 controller of one core is directly connected to the L3 controllers of the other cores. This is illustrated in the AMD slide I posted earlier. According to that slide, the total shared L3 cache is accessed with interleaved addressing on the low-order bits, so that binary address "...00" goes to the local cache controller, while addresses "...01", "...10" and "...11" will go to the cache controllers of the other cores, respectively. That gives a consistent average access latency. That's how I understand it.
Edit: Note that this address interleaving scheme will not work for 6 cores.
From your first link.
I have seen that, but there is no proper explanation.
Can be marketing talk.
I have seen that, but there is no proper explanation.From your first link.
Pc Perspective latency test show identical latency between the cores on a single CCX.Forum software is acting up. I cannot edit my post.
I have seen that, but there is no proper explanation.
Can be marketing talk.
Why is that the best choice? It is sub-optimal. By increasing the core count per CCX, you can no longer feasibly direct-connect the cores (6*5/2 = 15 links!). Why take the penalty when they can do 3 x 4-core CCX instead?
Pc Perspective latency test show identical latency between the cores on a single CCX.
This means that there is an equal travel time between all four L3 caches. There is no 1 hop and 2 hops, so the cross linkage is correct. Each L3 is directly linked to other L3 caches in a CCX.

L2$ tags are pushed up to L3$There is still something i do not understand. From the reviews it is mentioned that data goes directly to L2 from main memory and that the L3 is only used as victim cache for expelled data from L2.
Then why, is the core to core connection from L3 to L3 ?
It should be from L2 to L2. What am i missing ?
Then that picture with the links between L3 is kind of wrong.
L2$ tags are pushed up to L3$
AFAIK the L3 cache is really seen as one 8MB unit made up of 4 pieces. Why segmented? I don't know and maybe someone with the knowledge can explain. Power usage? The intra L3 links allow each core equal access to the whole L3.There is still something i do not understand. From the reviews it is mentioned that data goes directly to L2 from main memory and that the L3 is only used as victim cache for expelled data from L2.
Then why, is the core to core connection from L3 to L3 ?
It should be from L2 to L2. What am i missing ?
Then that picture with the links between L3 is kind of wrong.
AFAIK the L3 cache is really seen as one 8MB unit made up of 4 pieces. Why segmented? I don't know and maybe someone with the knowledge can explain. Power usage? The intra L3 links allow each core equal access to the whole L3.
A single thread can use the full 8MB even if the other 3 cores are idle.
Yeah, that's pretty much it. It's a cloudy Saturday afternoon and I'm to lazy to look up the exact cache tag schema for Zeppelin.

