DrMrLordX
Lifer
Does anyone have a good suggestion for where to learn about Windows 10 core parking?
https://bitsum.com/parkcontrol/
That might help. Or:
http://www.tomshardware.com/forum/id-2750183/unable-disable-core-parking-windows.html
Does anyone have a good suggestion for where to learn about Windows 10 core parking?
The voltages could be flatish as the clocks are bellow the range shown in the first graph.
You do seem to be confusing the cores and the SoC while also assuming that CB scales perfectly with clocks.
As for Computerbase and 76W delta at the main, the review here does a bit better than that. "All of the power consumption measurements have been made with DCR method. The figures represent the total combined power consumed by the CPU cores (VDDCR_CPU, Plane 1) and the data fabric / the peripherals (VDDCR_SOC, Plane 2). These figures do not include switching or conduction losses."
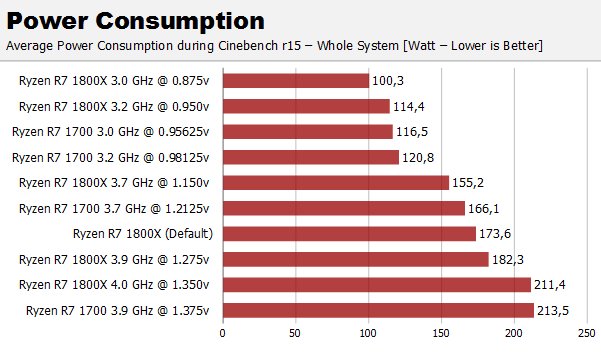
Measurements made by BC confirm my sayings :
Idle power is 44.2W, so including the CPU idle power this latter use at most 55W@3GHz@0.875V, the CB score is 1338pts.
Now keep this voltage as it is but reduce frequency to 1.9GHz, the score will be 850pts and power will be 55 x 19/30 = 34.8W...
So power at 850pts/1.9GHz has been artificialy inflated for some reason.
You can compare two measurements above and deduce the rate of power increasement vs frequency if you want, FI the two lower numbers displayed yield a theorical ratio delta of :
(3/3.2)(0.875/0.95)^2 = 0.795
Taking the higher value wich is 78W delta this yield 62W while the actual measurement is 64W, so theory and practice agree here..
What are you smoking? You completely ignore my answer and come up with more non evidence.
The Stilt's graphs clearly indicate that the range of CB multi-threaded scores are obtained when the CPU is operating below the first critical point, where voltage is proportional to Fmax.What i came with are elements that show that your objections are not justified and that the factors you are talking about have no great influence, the CPU behave like a capacitor that would have a constant value, meaning that the power it dissipate is mainly a function of frequency and voltage, linearly in respect of frequency and as a square re to voltage, FTR the total capacitance of the CPU (in Cinebench..) can be estimated to 2.8 nanofarad...
What i came with are elements that show that your objections are not justified and that the factors you are talking about have no great influence, the CPU behave like a capacitor that would have a constant value, meaning that the power it dissipate is mainly a function of frequency and voltage, linearly in respect of frequency and as a square re to voltage, FTR the total capacitance of the CPU (in Cinebench..) can be estimated to 2.8 nanofarad...
What i came with are elements that show that your objections are not justified and that the factors you are talking about have no great influence, the CPU behave like a capacitor that would have a constant value, meaning that the power it dissipate is mainly a function of frequency and voltage, linearly in respect of frequency and as a square re to voltage, FTR the total capacitance of the CPU (in Cinebench..) can be estimated to 2.8 nanofarad...
So I've read a good deal about possible problems with Windows 10 scheduler and how it may not be properly handling the two CCX design. Despite AMD already releasing a statement claiming there is no problem with scheduling under Windows, I decided to do a little experiment of my own and write a small benchmark in C++.
Also, why do you use polynomial fitting for data that is perfectly linear, as you state in your previous post? Open up your favorite curve-fitting tool and put some real data in it and see for yourself "better fits" with higher degree polynomials. Of course any conclusion you draw from that fit without knowing the expected behavior of the data is going to be wrong.
Plot y=x and y=x^n and see for yourself which is ahead for different x.

@ ryzenmaster
At what DRAM clocks and have you tried testing at any other clocks?
Physics and maths do not lie when they are understood correctly, and since the chip is at 65W at 3.2 then it means that it s at 20W at 1.9GHZ, and that the score is 850 at this power, and not at 35W.
I understand it alright - when 60% of a graph is linear, you would not want to use polynomial fitting and get incorrect extrapolated results.
More testing. This time I had all 4 threads referencing the same tree instance, which lead to some interesting results:
I tried to force less than optimal scenario by setting affinity to 0,2,8,10 and referencing same instance on all threads. Having one copy means that it can only reside in cache of one CCX at a time so with affinity set to run threads on both CCX we are bound to see increased latencies. Indeed quite frequently all threads have their latencies at around ~600-700ns. There is much more variation between runs compared to optimal scenario with two copies and affinity, where the latencies sit at around ~350ns on all threads. Though there is more variation with single copy, there is also consistency between the threads and their latencies tend to be within 20ns from one another.
So what about all 4 referencing same instance without affinity? Interesting enough results here are much the same as with 0,2,8,10 affinity. Similar latencies between ~600-700ns and similar consistency between threads.
Ok what about all 4 referencing same instance using one CCX with 0,2,4,6 affinity? Well just like you might expect, results are back to ~350ns on all threads given that again we have an optimal scenario with data residing in cache of same CCX as thread execution.
Last one I tested this time around was affinity of 0,1,2,3 meaning we stick to one CCX but only two physical cores. Once again consistent results with all threads at around ~450ns latency. Only some 100ns more than with 4 physical cores. SMT seems to be doing what it was built for here; context switching at blazing speeds 🙂

Those two curves are contradictory, or at least they highlight the methodology used to draw the second one...
For the power increasing linearly with frequency like in the second curve between 600pts-840pts voltage should be kept constant....
This means that at 600pts the voltage is the same as at 840pts and power is hence overestimated.
Also there s no review that show 70W at 1400pts, FTR computerbase measure 76W delta at the main for CB R15 MT...
So I've read a good deal about possible problems with Windows 10 scheduler and how it may not be properly handling the two CCX design. Despite AMD already releasing a statement claiming there is no problem with scheduling under Windows, I decided to do a little experiment of my own and write a small benchmark in C++.
So this is what I did:
I have a hash table / tree structure which I populate with dictionary roughly the size of 3MB. I then create a copy of it and spawn 4 threads, each with reference to either of the copies. First two threads get reference to first one, and following two threads a reference to the copy. The threads will then proceed to fetch values by string keys. They each do this for 50k iterations and then report average time it took them to do it. For consistency they fetch by same hard coded keys, which are existing entries in the tree.
So in the end we have something like this:
.
That doesn't mean that you can explain away the graph of a straight line by fitting a polynomial.Actually it should be interpreted otherwise, 60% of the graph display a quasi linear rate of change of voltage vs frequency but power is the combination of those two factors, ie frequency x voltage^2, and the end result is non linear...
To get the power curve out of this one you should multiply the curve values by the voltages at each point, the result will be frequency x voltage x voltage, the Y axys will be referenced as the power in a relative scale unless you know an actual value to set an absolute scale..
Plot this curve and tell us what is the rate of power vs frequency/voltage displayed here and how much more power is required at 3.2GHz in respect of 1.9GHz...
You will conclude that the rate of change is a polynomial of degree 2.56 in respect of frequency between 2.1 and 3.27GHz, and that the power at 3.2GHz is 3.33x the power at 1.9GHz, if the chip did actually require 35W at 1.9 then it would be over 110W at 3.2, and we know that it s within 65W at this frequency...
Physics and maths do not lie when they are understood correctly, and since the chip is at 65W at 3.2 then it means that it s at 20W at 1.9GHZ, and that the score is 850 at this power, and not at 35W.
That doesn't mean that you can explain away the graph of a straight line by fitting a polynomial.
Given the range of CB scores for the graph, comparing the score vs voltage and score vs frequency are equivalent, provided of course the scores scale linearly with frequency.
Edit: Also see the post above. Those are cTDP, not power consumed. Therefore multiplying that voltage-frequency curve with voltages at each point would lead to a completely different graph that makes the comparison with CB vs cTDP even more erroneous.
In the Vmin-Fmax curve the voltage was manually set to the bare minimum value, which maintained the stability at the given frequency.
Because of that the voltages for the Cinebench-cTDP chart were basically factory calibrated and because of that they weren't optimal , efficiency wise.
Since cTDP relies on the power limiters which are only active in "Normal Mode", using "OC-Mode" and configuring the voltages manually is not an option. It is naturally possible to add a negative voltage offset at the VRM controller, however it wouldn't improve the performance (clocks) despite it would result in lower voltage. The SMU calculates the power consumption based on the commanded voltage and external voltage offsets obviously cannot be seen by the SMU.
With few changes the performance would be significantly better, at the same power.