Heat is going to be a problem, indeed.
Perhaps I missed it, but has anyone done an analysis of how a "40% performance boost OR 60% total power reduction" is going to yield 16 cores at 5Ghz? I've seen a lot of speculation about higher boost speeds and higher core counts, but I have a hard time seeing 12 cores at (or around) 5Ghz, nevermind 16.... Oh yes, and more bandwidth, lower latency, and wider vector ops too.
Engineering is about tradeoffs. What are we going to get, and what is AMD going to leave on the table? And having left whatever those items are on that proverbial table, which markets are AMD ceding?
I'd start with what's possible. Let's say, despite all previous history with Glofo numbers, that these percentages are actually accurate. Let's also assume that they ship on time, and on budget. And then let's let everything scale linearly. (optimism is my drug of choice) The R1700 is 65W @ 3Ghz. So, without changing anything, that would be 65W @ 4.2Ghz, or 26W @ 3Ghz. Immediately I see huge upsides for my server parts. 32 cores at 3Ghz is going to be wildly easy. 104W. 64 cores is right around 210W. Or take the 7601's 2.7Ghz / 180W specs ( * .4 / 2) and wind up with a tdp of 145W for 64 cores. Easy server wins. But the desktop?
The desktop parts need to get faster. Boost clocks need to aim to rise something like 25% over the 1800X. That leaves us with 11 cores at 5Ghz and a tdp of 95W. 105W for 12 cores. 140W for 16 cores. Would AMD really ship a 140W 16 core processor? For AM4?
256b-width vectors are probably easy on the floorplan, but likely difficult to survive thermals. IF speeds are also considerations. Can AMD find enough power savings to pay for all those expenses, or will one of these be sacrificed? If you want high core counts, you need to spend budget on the interconnects. As these past few pages attest to, this is not a simple problem.
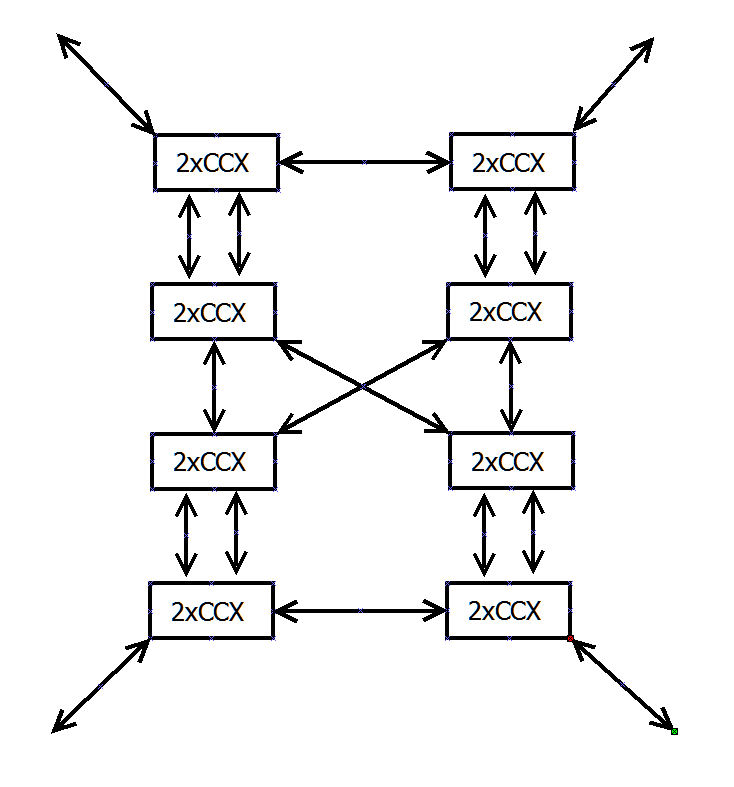
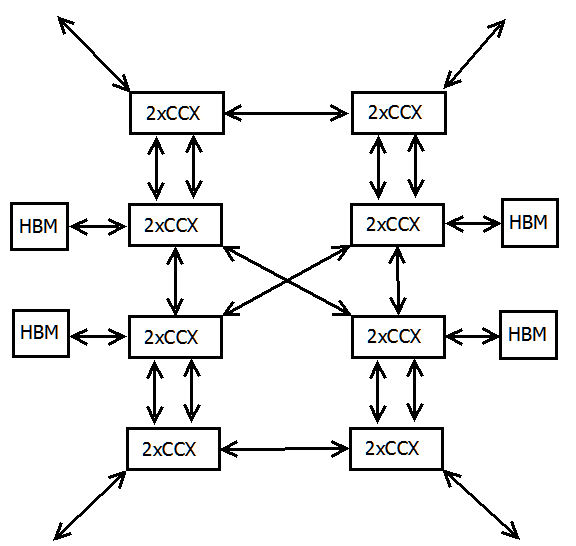
Given the opportunity, I expect that the server parts drive core design, and that the desktop parts have to live with the tradeoffs. What do server parts need? More L3, a little more relaxed on the latency. Do server parts care about the latency in a hierarchy of 4 cores x 4 CCX x 4 dies? Probably not -- NUMA is fine. How would desktop respond? Lose the core-based marketing strategy on desktop, and cut those wide vector units if they have to. Desktop might have a 16 core chip, but not at high speeds. Plus, without high speed DDR5 they're likely to starve anyway. Low speed 16 core maybe. 12 core high speed w/o the gfx, 8 cores with a builtin gpu, 8 core non-gfx very high speed for the dedicated gamer. Meanwhile, split my Threadripper market in two. In fact, might as well introduce the idea of cores vs speed now -- witness WX vs X. I expect WX market gets the low-speed 16 core setups, while the X series gets two 12 cores.
I don't expect buttered, fried dough on my Zen2 IF design. :shrug: Hey, if they manage it, great, but being in the front of the 7nm launch gate seems risky enough.