One doesn't have to do anything with the other.
We may be in violent agreement with each other.
The process node characteristics ... are usually based on the most efficient range ... which ... stops at around 3.3GHz.
Indeed. I prefer to start based on what we know, or at least what we assume we know from what we're told, which is why I started by talking about the R1700's 8 core, 3Ghz base. For a desktop chip, a 40% improvement means we're looking at ~65W tdp 4.2Ghz base clock, all other things being equal (which they won't be, but that's a starting point). 12 core would be ~100W, which matches nicely to the current 2700X tdp. A 16-core requires another 30W. There's only two ways to ship a 16 core to the desktop, one is to lower the base clocks, like TR2 is doing, the other is to ship a hair dryer. I'm not sure I'd want 130W base-clock chip on AM4. Are there desktop users that would put up with <4Ghz base clocks in exchange for 16 cores? That conclusion is entirely before we get to 1) turbo and 2) overclocking.
If we're lucky, the wall moves up a matching/linear 40%, and we've got headroom to 5.5ish. Aside from assumptions made due to IBM's involvement, we have no evidence that it will, and also precious little evidence that GloFo is even going to be able to deliver 7nm. Which is why I don't understand:
12 cores, and 48 threads at 5.5 Ghz in a shipping product...
Actually, there are a number of things I don't understand in that quote, one of which is 12 cores at 5.5Ghz. If you've got plenty of power delivery, and the wall has moved, you might be able to OC to 5.5Ghz on 12 cores. Maybe. Barely. Like my 1800X does to 4Ghz. (which it doesn't -- not Prime95 stable) I wouldn't bet the farm on it.
The other thing I don't understand -- 48 threads? SMT4? What good is SMT4 on the desktop? It'll only serve to increase average latency and power use (and a headache wrt cache utilization) in the hope of improving throughput on a processor that isn't being tasked that way. In order to have the computational units to adequately use SMT4, you won't be seeing 4.2base / 5.5 turbo. If Zen2 comes with SMT4 (which would make sense for Epyc), it would be the first thing to disable when gaming. If you expect 48 threads to operate similarly to the existing 16 threads on your 8 core processors, you need three times the active units. I would expect a lot closer to R1700 clocks on such a processor as 3x power requirements entirely absorbs the benefits of 7nm. There's no additional clocking room. I don't see that happening on desktop. Sure, it's lovely to play a numbers/quantity game, but it makes very little sense. Unless AMD really isn't going to pursue frequency on the desktop. I would be disappointed by that outcome.
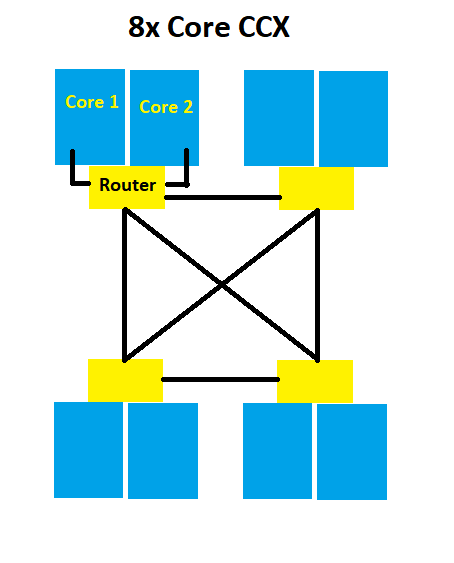
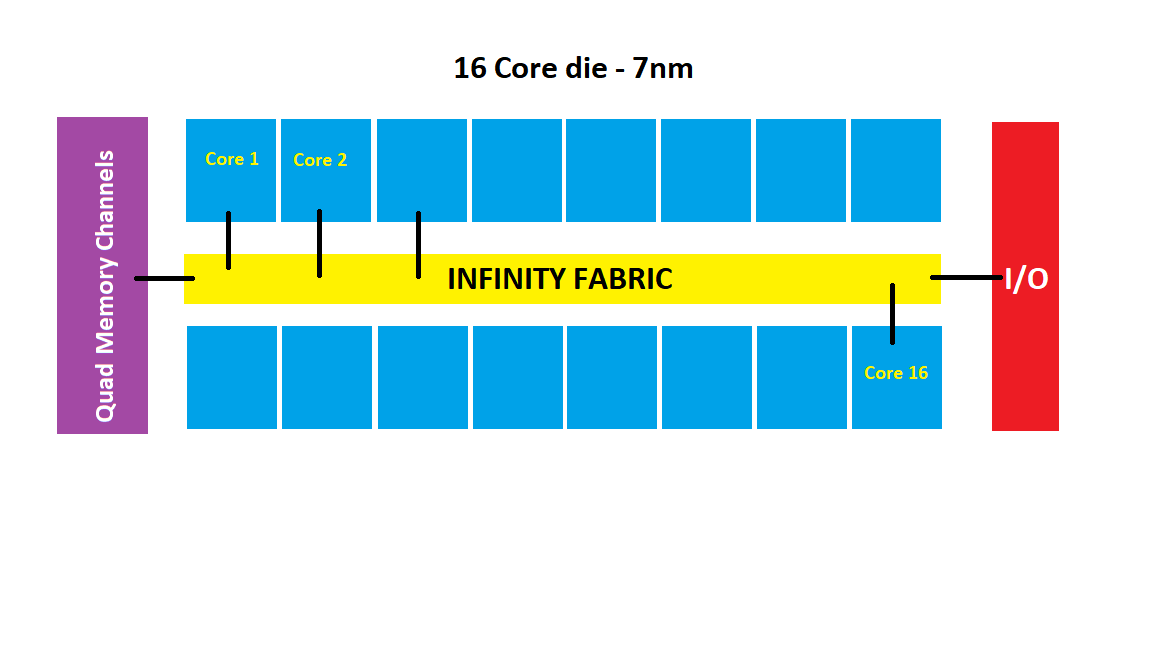
I haven't read the semiaccurate post which likely gives some insight into the coming Epyc chips, but one way to account for the hype of what is public is to postulate a 6 core base CCX with SMT4 (or a triple quad-core-CCX die). 192 threads would be monstrous on a server. The thing is, I'm not sure that would carry over to the desktop. Whether you spin it as "desktop-oriented CCX", or you just leave the extra units unpowered, I expect that any throughput-oriented optimizations for Epyc won't be carried over to the desktop. One of the more persuasive arguments for keeping the 4-core CCX and delivering a quad-CCX die for Epyc and a triple-CCX die for desktop is specifically because of the different scaling you get from tdp and frequency scaling. It allows you to have a basic core which you lay out in two different manners for server and desktop. SMT4 is a good counter-argument for leaving the die of both at 12 cores (while disabling it on desktop). I'm sure we'll know in 6 months. I'm happy to be wrong about any and all of this :shrug: