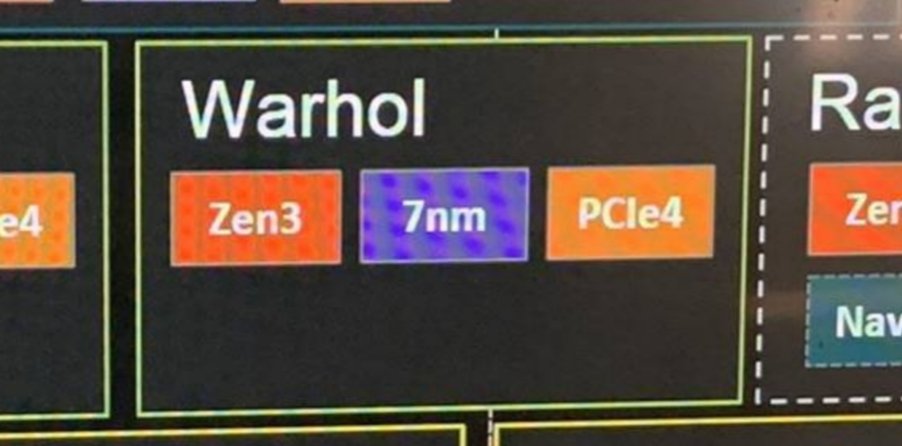
I really can't see Zen4 being able to be pulled in so quickly, whereas migrating Zen3 from 7EUV to 5Euv should be a lot easier and quicker. As I posted earlier, there's no rule preventing Zen3 on both 7nm and 5nm. One for server (7nm) and the other for desktop (5nm). I know everyone thinks that it must be the other way, but I see a good reason for it this way. The I/O die design is common to all in any case. Isn't this one of the benefits of a chiplet design. Should AMD religiously follow the stated roadmap, even in the face of quicker advancement?That's where I stand as well. No way AMD is moving an N7+ design to N5P (which don't use the same design rules) on such a short notice, with the former already being used for sampling in datacenters. TSMC is accelerating mass production N5P, so may have asked AMD to do the same for its silicon design already in the work for N5P which would be Zen 4, not 3. Though AMD's first N5P design actually realistically would be a GPU pipecleaner. This report doesn't amount to much imo.
Anyone can estimate the time needed to migrate a synthesizable design to a different node using the same RTL file? Isn't this exactly what AMD has worked so hard to exploit in order to be agile?