What are you talking about? I don't think you follow the development of h264 encoders as well as you think you do. x264 already has been utilizing avx2 and x264's ability to use more threads has been improved some few times in the last couple or few years.
x264 is one of, if not the most, worked on video encoder and it's staying power is pretty immense. 265 has a long way to go to improve on everything x264 already has BEEN doing. There's not a lot of advantage in even using 265, yet, and 265 is SLOW.
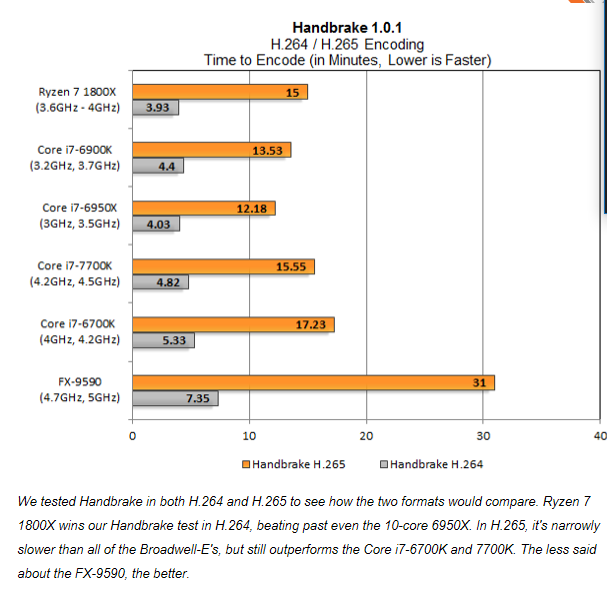
Well I'm far from an expert on this subject, but I do read the doom9 forums and that's where I got it from. That said, I NEVER said at any point that x264 didn't utilize AVX2, or couldn't use multithreading. I just said that its ability to utilize them was limited, especially compared to X265. But you don't have to take my word for it, just look at the benchmarks that I've posted which demonstrate it perfectly:
The largest performance increase stems from AVX2 implementation and efficiency. I mean, just look at the FX-9590. It's obliterated under H265, because it lacks AVX2. Under H264 though, it's still competitive more or less.
The Ryzen which has half the AVX2 throughput of the Intel CPUs goes from winning in H264, to being behind the 6900K and 6950X with H265. And a longer test would magnify these margins even more.
Fact is, H265 even at this stage has a much heavier integration of AVX2 than H264, and slightly better multithreading support. This will continue to improve though as time goes by. Relatively speaking, it's still in the early stages of optimization.