
Wildcat Lake (WCL) Specs
Intel Wildcat Lake (WCL) is upcoming mobile SoC replacing Raptor Lake-U. WCL consists of 2 tiles: compute tile and PCD tile. It is true single die consists of CPU, GPU and NPU that is fabbed by 18-A process. Last time I checked, PCD tile is fabbed by TSMC N6 process. They are connected through UCIe, not D2D; a first from Intel. Expecting launching in Q1 2026.



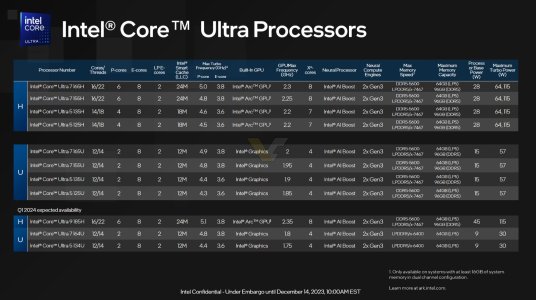
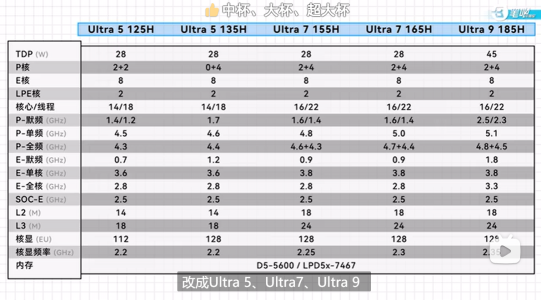
As Hot Chips 34 starting this week, Intel will unveil technical information of upcoming Meteor Lake (MTL) and Arrow Lake (ARL), new generation platform after Raptor Lake. Both MTL and ARL represent new direction which Intel will move to multiple chiplets and combine as one SoC platform.
MTL also represents new compute tile that based on Intel 4 process which is based on EUV lithography, a first from Intel. Intel expects to ship MTL mobile SoC in 2023.
ARL will come after MTL so Intel should be shipping it in 2024, that is what Intel roadmap is telling us. ARL compute tile will be manufactured by Intel 20A process, a first from Intel to use GAA transistors called RibbonFET.

Intel Wildcat Lake (WCL) is upcoming mobile SoC replacing Raptor Lake-U. WCL consists of 2 tiles: compute tile and PCD tile. It is true single die consists of CPU, GPU and NPU that is fabbed by 18-A process. Last time I checked, PCD tile is fabbed by TSMC N6 process. They are connected through UCIe, not D2D; a first from Intel. Expecting launching in Q1 2026.
| Intel Raptor Lake U | Intel Wildcat Lake 15W? | Intel Lunar Lake | Intel Panther Lake 4+4+4 | |||
|---|---|---|---|---|---|---|
| Launch Date | Q1-2024 | Q2-2026 | Q3-2024 | Q1-2026 | ||
| Model | Intel 150U | Intel Core 7 | Core Ultra 7 268V | Core Ultra 7 365 | ||
| Dies | 2 | 2 | 2 | 3 | ||
| Node | Intel 7 + ? | Intel 18-A + TSMC N6 | TSMC N3B + N6 | Intel 18-A + Intel 3 + TSMC N6 | ||
| CPU | 2 P-core + 8 E-cores | 2 P-core + 4 LP E-cores | 4 P-core + 4 LP E-cores | 4 P-core + 4 LP E-cores | ||
| Threads | 12 | 6 | 8 | 8 | ||
| Max Clock | 5.4 GHz | ? | 5 GHz | 4.8 GHz | ||
| L3 Cache | 12 MB | 12 MB | 12 MB | |||
| TDP | 15 - 55 W | 15 W ? | 17 - 37 W | 25 - 55 W | ||
| Memory | 128-bit LPDDR5-5200 | 64-bit LPDDR5 | 128-bit LPDDR5x-8533 | 128-bit LPDDR5x-7467 | ||
| Size | 96 GB | 32 GB | 128 GB | |||
| Bandwidth | 136 GB/s | |||||
| GPU | Intel Graphics | Intel Graphics | Arc 140V | Intel Graphics | ||
| RT | No | No | YES | YES | ||
| EU / Xe | 96 EU | 2 Xe | 8 Xe | 4 Xe | ||
| Max Clock | 1.3 GHz | ? | 2 GHz | 2.5 GHz | ||
| NPU | GNA 3.0 | 18 TOPS | 48 TOPS | 49 TOPS |
As Hot Chips 34 starting this week, Intel will unveil technical information of upcoming Meteor Lake (MTL) and Arrow Lake (ARL), new generation platform after Raptor Lake. Both MTL and ARL represent new direction which Intel will move to multiple chiplets and combine as one SoC platform.
MTL also represents new compute tile that based on Intel 4 process which is based on EUV lithography, a first from Intel. Intel expects to ship MTL mobile SoC in 2023.
ARL will come after MTL so Intel should be shipping it in 2024, that is what Intel roadmap is telling us. ARL compute tile will be manufactured by Intel 20A process, a first from Intel to use GAA transistors called RibbonFET.
Attachments


Last edited:






