-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Discussion Intel current and future Lakes & Rapids thread
Page 681 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
nicalandia
Diamond Member
If it's truly about security(might not take Intel at their word) it could be a bad/botched CXL implementation at the silicon level. That could explain as to why the Super Computer that was supposed to have been released months ago is not ready yet. Also a combination of Faulty UPI and CXL would prevent the Super Computer to glue all of the computer blade on a Coherent Single System Image.I suppose it's possible that the UPI bug is some sort of data leakage.
Last edited:
IIRC, Ponte Vecchio dropped CXL support a while back, so that can't be the issue. And Intel's not even supporting CXL.mem period. AMD might well beat Intel in both timing and scope of CXL support, which is particularly pathetic given Intel invented it.If it's truly about security(might not take Intel at their word) it could be a bad/botched CXL implementation at the silicon level. That could explain as to why the Super Computer that was supposed to have been released months ago is not ready yet. Also a combination of Faulty UPI and CXL would prevent the Super Computer to glue all of the computer blade on a Coherent Single System Image.
nicalandia
Diamond Member
When did they drop Support for CXL? As far as I am aware they still Support CXLIIRC, Ponte Vecchio dropped CXL support a while back, so that can't be the issue. And Intel's not even supporting CXL.mem period. AMD might well beat Intel in both timing and scope of CXL support, which is particularly pathetic given Intel invented it.
AnandTech Forums: Technology, Hardware, Software, and Deals
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
www.anandtech.com

Intel Sapphire Rapids CXL with Emmitsburg PCH Shown at SC21
In the most important demo at SC21, we saw the Intel Eagle Stream dev platform for Sapphire Rapids with an Emmitsburg PCH and CXL running
Genoa will have full support for CXL as well.
Last edited:
You asking about PVC or SPR?When did they drop Support for CXL? As far as I am aware they still Support CXL
nicalandia
Diamond Member
Sapphire Rapids, I was mentioning that if there was an issue/bug in silicon that was a security risk, it's likely CXL or a combination of CXL and UPI. CXL could be a security risk if not implemented properlyYou asking about PVC or SPR?
Sapphire Rapids, I was mentioning that if there was an issue/bug in silicon that was a security risk, it's likely CXL or a combination of CXL and UPI. CXL could be a security risk if not implemented properly at silicon level.
Naturally it was our expectation that all CXL 1.1 devices would support all three of these standards. It wasn’t until Hot Chips, several days later, that we learned Sapphire Rapids is only supporting part of the CXL standard, specifically CXL.io and CXL.cache, but CXL.memory would not be part of SPR. We're not sure to what extent this means SPR isn't CXL 1.1 compliant, or what it means for CXL 1.1 devices - without CXL.mem, as per the diagram above, all Intel loses is Type-2 support. Perhaps this is more of an indication that the market around CXL is better served by CXL 2.0, which will no doubt come in a later product.
AnandTech Forums: Technology, Hardware, Software, and Deals
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
www.anandtech.com
nicalandia
Diamond Member
With help from Cadence a few FPGs and simulation environment, Intel was able to confirm that CXL 2.0 will have no issue working with their current implementation.AnandTech Forums: Technology, Hardware, Software, and Deals
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.www.anandtech.com
Through simulation, Intel could ensure backward compatibility against its existing CXL 1.1 solutions,” Krishnamurthy said.
Last edited:
DrMrLordX
Lifer
The pun was intended, if that's what you meant.
lol okay. Thought so.
That's just it, in the Q&A Intel admitted the bulk of SPR contribution will be in 2023.
So it'll be like IceLake-SP all over again. It's probably that UPI bug killing performance in a lot of applications. Those E3-stepping QS leaks are probably true. Sapphire Rapids is dead, market-wise. Too little too late.
nicalandia
Diamond Member
AMD ironed out many of the issues with ccx and numa domains way back on Zen1 and Zen1+ and is just sailing away now with Zen3 and Zen4... But Intel is in the worst possible time to do that for a MCM that needs to look like Monolithic Die.So it'll be like IceLake-SP all over again. It's probably that UPI bug killing performance in a lot of applications. Those E3-stepping QS leaks are probably true. Sapphire Rapids is dead, market-wise. Too little too late.
Shouldn't be a huge issue. They've had SNC for years, and die-to-die latency should be much shorter than a SERDES solution.AMD ironed out many of the issues with ccx and numa domains way back on Zen1 and Zen1+ and is just sailing away now with Zen3 and Zen4... But Intel is in the worst possible time to do that for a MCM that needs to look like Monolithic Die.
nicalandia
Diamond Member
Intel will be integrating their VPU for Meteor Lake
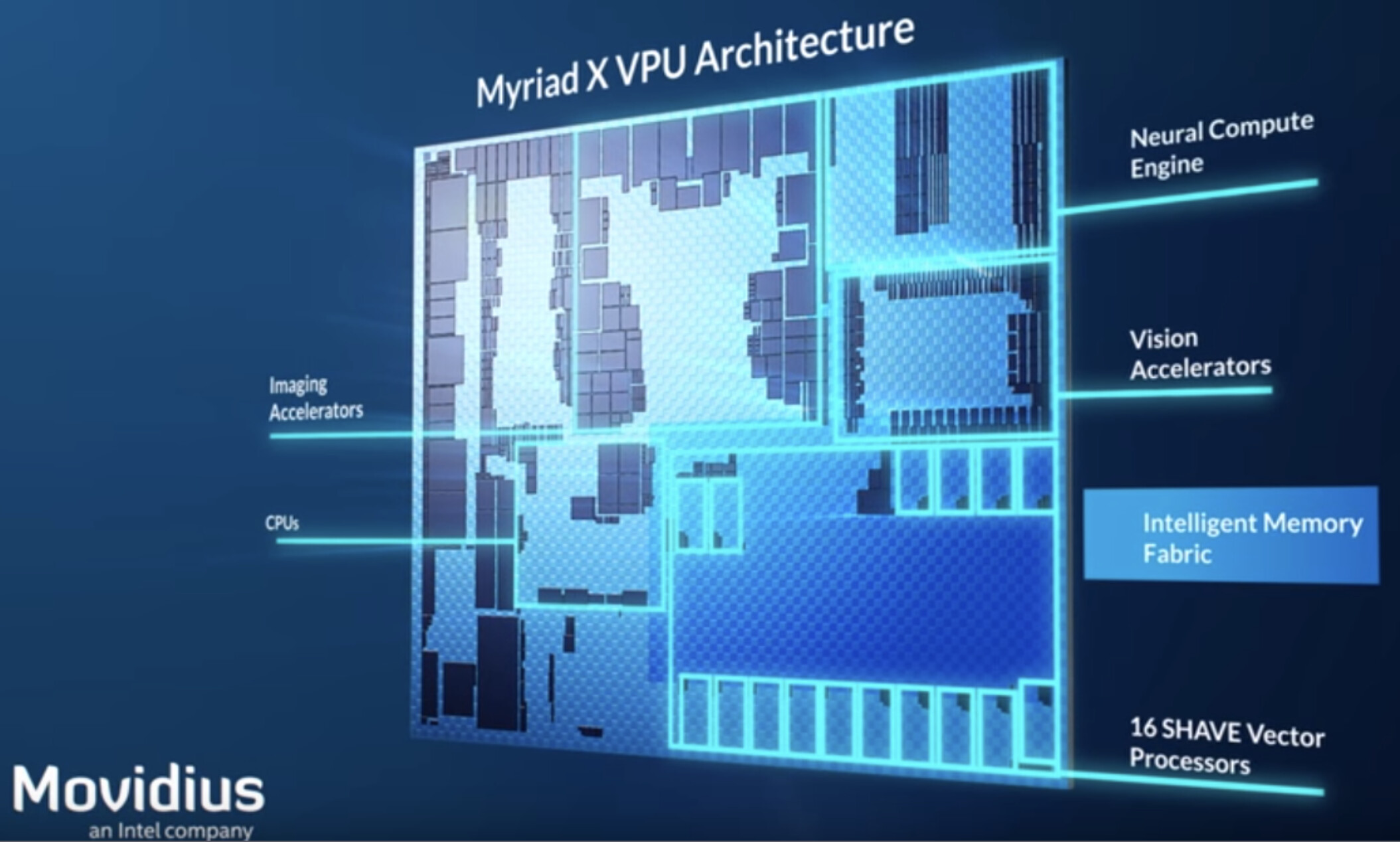
 www.techpowerup.com
www.techpowerup.com
How would that compare to Xilinx AI engine on AMD APUs on 2023?
Intel Driver Update Confirms VPU Integration in Meteor Lake for AI Workload Acceleration
Intel yesterday confirmed its plans to extend its Meteor Lake architecture towards shores other than general processing. According to Phoronix, Intel posted a new driver that lays the foundations for VPU (Versatile Processing Unit) support under Linux. The idea here is that Intel will integrate...
How would that compare to Xilinx AI engine on AMD APUs on 2023?
Too many variables right now. Configs, workloads, software support, etc. AMD will have a distinct process advantage, if nothing else.Intel will be integrating their VPU for Meteor Lake
Intel Driver Update Confirms VPU Integration in Meteor Lake for AI Workload Acceleration
Intel yesterday confirmed its plans to extend its Meteor Lake architecture towards shores other than general processing. According to Phoronix, Intel posted a new driver that lays the foundations for VPU (Versatile Processing Unit) support under Linux. The idea here is that Intel will integrate...
How would that compare to Xilinx AI engine on AMD APUs on 2023?
nicalandia
Diamond Member
Some say that Intel VPU is like Nvidia Tensor Cores, but so far what I have read about each. they don't seem comparable.Too many variables right now. Configs, workloads, software support, etc. AMD will have a distinct process advantage, if nothing else.
Architectures are probably different, but they're both going to be used for ML inference in the same market, so it'll make sense to compare them. I think software will end up being the big question though, if Android is anything to go by.Some say that Intel VPU is like Nvidia Tensor Cores, but so far what I have read about each. they don't seem comparable.
nicalandia
Diamond Member
Architectures are probably different, but they're both going to be used for ML inference in the same market, so it'll make sense to compare them. I think software will end up being the big question though, if Android is anything to go by.
There was a comparison of NVIDIA Tensor Cores(GPU) and Intel VPU for ML Inference and this one of the points made.
"The difference between these two accelerators can also be noticed on the side of the programming process. In many cases the implementation of an application which uses GPU does not require any special knowledge about the accelerator itself. Most of the AI frameworks provide a built-in support for GPU computing (both training and interference) out of the box. In Movidius case, however, it is required to gain knowledge about its SDK as well"

Benchmark of common AI accelerators: NVIDIA GPU vs. Intel Movidius
This document compares the performance of NVIDIA GPUs and Intel Movidius VPUs for object detection using the YOLO real-time detection model across different hardware configurations. Results indicate that NVIDIA GPUs significantly outperform Intel Movidius VPUs in terms of processing speed and...
 www.slideshare.net
www.slideshare.net
The main benchmark will probably be how both interact with the WinML API. Most developers aren't going to target vendor-specific accelerators. Though I imagine we'll see some high profile demos with e.g. Adobe.There was a comparison of NVIDIA Tensor Cores(GPU) and Intel VPU for ML Inference and this one of the points made.
"The difference between these two accelerators can also be noticed on the side of the programming process. In many cases the implementation of an application which uses GPU does not require any special knowledge about the accelerator itself. Most of the AI frameworks provide a built-in support for GPU computing (both training and interference) out of the box. In Movidius case, however, it is required to gain knowledge about its SDK as well"
Benchmark of common AI accelerators: NVIDIA GPU vs. Intel Movidius
This document compares the performance of NVIDIA GPUs and Intel Movidius VPUs for object detection using the YOLO real-time detection model across different hardware configurations. Results indicate that NVIDIA GPUs significantly outperform Intel Movidius VPUs in terms of processing speed and...
Edit: I guess they could maybe get away with using oneAPI or ROCm (does ROCm support non-GPU architectures?) for more arch-specific support.
igor_kavinski
Lifer
I was wondering and apologies if this has been discussed before: is Alder Lake as we know it today, a direct result of the original Zen launch? It takes maybe 3 to 4 years from designing the architecture to the CPU shipping so does that mean Intel's engineers predicted correctly how powerful Zen might turn out to be in future iterations and hurriedly went with the area-efficient core design to ensure they could still be competitive with AMD despite a process disadvantage? Or is there any indication that ADL was put together even later, like maybe 2018 and rushed through everything that a CPU normally has to pass through?
I was wondering and apologies if this has been discussed before: is Alder Lake as we know it today, a direct result of the original Zen launch? It takes maybe 3 to 4 years from designing the architecture to the CPU shipping so does that mean Intel's engineers predicted correctly how powerful Zen might turn out to be in future iterations and hurriedly went with the area-efficient core design to ensure they could still be competitive with AMD despite a process disadvantage? Or is there any indication that ADL was put together even later, like maybe 2018 and rushed through everything that a CPU normally has to pass through?
No one knows, and I’d be really interested in reading an insider telling of it.
Intel pulling up Raptor Lake mobile launch. MLID get wrecked again https://www.tomshardware.com/news/intel-to-change-raptor-lake-cpu-roll-out-plan
shady28
Platinum Member
I was wondering and apologies if this has been discussed before: is Alder Lake as we know it today, a direct result of the original Zen launch? It takes maybe 3 to 4 years from designing the architecture to the CPU shipping so does that mean Intel's engineers predicted correctly how powerful Zen might turn out to be in future iterations and hurriedly went with the area-efficient core design to ensure they could still be competitive with AMD despite a process disadvantage? Or is there any indication that ADL was put together even later, like maybe 2018 and rushed through everything that a CPU normally has to pass through?
I'm pretty sure Intel has had multiple architectures essentially done for years. They simply didn't have the process nodes ready to deliver, or more accurately the executives prior to Gelsinger were not ready to spend the capital to move to improved nodes. This is why they've been able to push out 3 new chips with 3 different architectures in two years - Gen 10 (Skylake +++), Gen 11 desktop (Ice Lake on 14nm), Tiger Lake (Ice Lake + with Xe iGPU), and Gen 12 (Alder Lake).
As example, Jim Keller left Intel in 2020 and his main contributions appear to be to Arrow Lake (15th gen) and Lunar Lake (16th Gen). So we won't even see 15th gen until 2024, 4 years after he left, two years from now. These are the two, it is speculated (worse than rumor), may double Intel's IPC.
If that happens, admittedly a big if, we may be seeing a rehash of Intel 2008-2011 when Intel went from Core, to Core 2, to Nehalem, to Sandy Bridge. AMD was competitive with Athlon II vs Core 2 and Phenom vs Nehalem, but AMD lost it when Sandy Bridge came out vs AMD FX. Intel also lost money in 2009. The parallel is there, but the last half of the story has yet to be written.
Thunder 57
Diamond Member
I'm pretty sure Intel has had multiple architectures essentially done for years. They simply didn't have the process nodes ready to deliver, or more accurately the executives prior to Gelsinger were not ready to spend the capital to move to improved nodes. This is why they've been able to push out 3 new chips with 3 different architectures in two years - Gen 10 (Skylake +++), Gen 11 desktop (Ice Lake on 14nm), Tiger Lake (Ice Lake + with Xe iGPU), and Gen 12 (Alder Lake).
As example, Jim Keller left Intel in 2020 and his main contributions appear to be to Arrow Lake (15th gen) and Lunar Lake (16th Gen). So we won't even see 15th gen until 2024, 4 years after he left, two years from now. These are the two, it is speculated (worse than rumor), may double Intel's IPC.
If that happens, admittedly a big if, we may be seeing a rehash of Intel 2008-2011 when Intel went from Core, to Core 2, to Nehalem, to Sandy Bridge. AMD was competitive with Athlon II vs Core 2 and Phenom vs Nehalem, but AMD lost it when Sandy Bridge came out vs AMD FX. Intel also lost money in 2009. The parallel is there, but the last half of the story has yet to be written.
Speculated by who? I don't see that being realistic at all. The only reason we saw such IPC increases from Pentium D --> Core 2 and FX --> Zen was because the previous architecture in both cases were power hungry "Speed Demons" with low IPC and generally thought of as some of the weakest CPU's in both company's history.
shady28
Platinum Member
Nova Lake was rumored to come with a big architectural change and up to 50% CPU performance improvement over Lunar Lake , it's not Arrow/Lunar.
Arrow Lake will be the architectural update to Meteor Lake in the 'tick-tock' sense, as they will both be on Intel 4 and both be using the same socket. The "Royal Core" enhancements Keller worked on are supposed to debut with Arrow Lake, though it is supposedly a 'lite' version. The full fat Royal Core is supposed to come with Gen 16/17 Lunar and Nova.
Personally IDC, I'm going to go for a Raptor Lake build as it's the last of the truly monolithic non-tiled single node designs. I have a feeling it's going to be the best at some things (like those requiring low latency memory) for a very, very long time.
Arrow Lake will be the architectural update to Meteor Lake in the 'tick-tock' sense, as they will both be on Intel 4 and both be using the same socket. The "Royal Core" enhancements Keller worked on are supposed to debut with Arrow Lake, though it is supposedly a 'lite' version. The full fat Royal Core is supposed to come with Gen 16/17 Lunar and Nova.
Arrow Lake comes with Intel 20A says Intel, Meteor Lake is the only Intel 4 client core CPU as far as we know unless the plan changed. Maybe we will get an update at Intel innovation. I know about the lite and full Royal core, to me lite doesn't sound major and Arrow Lake in the reddit leak didn't sound like a major architecture uplift.
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 25K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 24K
-

-
