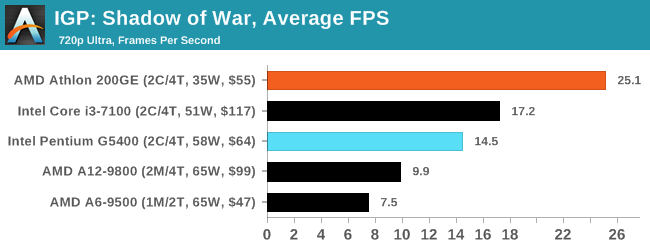
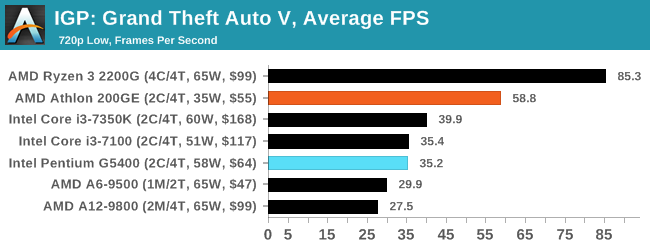
Would it be possible to make one of the (int) cores in an XV module run at reverse bias (for optimizing freqs at maximal perf/watt and somewhat above) while making the other int core run at fwd bb to maximize freqs (performance)?
FBB is aimed at running frequencies and RBB is aimed at idle frequencies. In multi-vt designs FBB and RBB can be used at the same time. However in single-vt designs only FBB or RBB can be used. This is fixed in 12FDX with DITO, which allows the transistor to have two body bias diodes; one for FBB and one for RBB. They do not run at the same time; FBB is for active/awake and RBB is for idle/sleep.
It is not possible in a migration port of Excavator to have independent core body biasing.
Any and all of those AVFS modules can be upgraded to AVFBS modules. The B in the letters is the body bias.
Lets say they can body bias independently...
Core A and Core B have intedependent voltage and body bias
Workload A goes to Core A
Workload B goes to Core B
Workload A is going to take awhile.
Workload B can be finished quickly.
Core A will then use FBB to get same frequency at a trimmed voltage. To maximize perf/watt. <== crawl-to-sleep
Core B will then use FBB to get higher frequencies at a higher voltage. To maximize performance. <== race-to-sleep
If so, what top freqs could a module reach given ~5W?
And secondly, could the perf/watt of the low freq thread surpass two threads on a single zen+ core at ~1.5-2ghz
Given a 5W TDP.
1.2(Throttle)~2.1 GHz(Base)~2.7 GHz(boost) @ ~1.25W
3.5W * 0.35 = ~1.23W
500~600 MHz @ <2.5W
^-- this expects similar devices, no tweaks for the newer client of the core(cpu/gpu): IoT/Consumer/Mobile, etc.
-> Faster AVFS implementations, increased frequency multiplier granularity, etc.
Makes all of the calculations based on 28BLK/XV pretty much mute. AMD does not do simple ports, it will be a full redesign(top-to-bottom) port at minimum. At maximum, it could be a full new design(bottom-to-top) for a new processor lineup for 22FDX/12FDX/7FDX.
The added components in Piledriver, Steamroller, and Excavator. Have implementations in FDSOI which have further increases performance or increase power efficiency. Basically, a flat 1.5x or 50% increase in frequency is not what is the max capability in 22FDX. Which limits the numbers that I can actually provide without knowing what is implemented.
I'm not going to look up Resonant Clock Mesh vs Adaptive Quasi-resonant Clock Meshes.
I'm not going to look up AVFS to AVFBS. I'm not going to look at what happens if a clock multiplier can be switched in 1us vs 100us, or by 0.0025x vs 0.25x, etc.
I can sort of look up potentials of a Integer PRF redesign and FPU datapath/PRF redesign.
In regards to track height, 22FDX 7T/8T vs 28nm 9T. Which if 28FDS is any indication: 28FDS 7T is close to 28G/HP at 12T. Do to the decline in scaling in 22BLK, I would say 7T/8T 22FDX design would perform higher than in 12T/13T 22BLK design.
The transition to FinFETs means sacrifice. While, the switch to FDSOI means "there is so much optimizations!"