There is something I would like to learn more about though. What will this more aggressive prefetcher and branch prediction mean for this architecture?
(Damn, I already typed about 5 paragraphs and then I clicked an updated link from my email and it just replaced the tab I was working on)
Anyway, that is about as "star material" as this architecture can get for desktop use. Before we delve into that, in contrast serverland can be well served as long as the "perf/watt" promised materializes - it's not a tough sell, especially for those with power limits set by off-site datacenters, or even an internal company IT infrastructure limitation. You'll be getting 16 strong cores (or 32/64 in 2p/4p), and compared to 200 mini cores like a SeaMicro deal, this is way better for reasons serverland is concerned with (bursty usage, for one - in fact that's one of the things they mentioned in their slides aside from perf/watt and perf/mm2 - "smoothing out bursty usage"; clearly, they are selling this arch hard to serverland, and so far everything they've laid out makes me feel this is a "server-first" arch - look at everything they've been saying, and it's a clear serverland message, nothing for desktops really, unless your local computer store salesman quotes you perf/watt, perf/mm2, "efficiency", etc.) So as far as serverland is concerned, and they hold true to the promise of better than MC performance (not hard to do - compared to Thuban, MC has low clocks, which made Thuban all the more a surprise when it clocked at 3.3 GHz), BD Interlagos is not a hard sell.
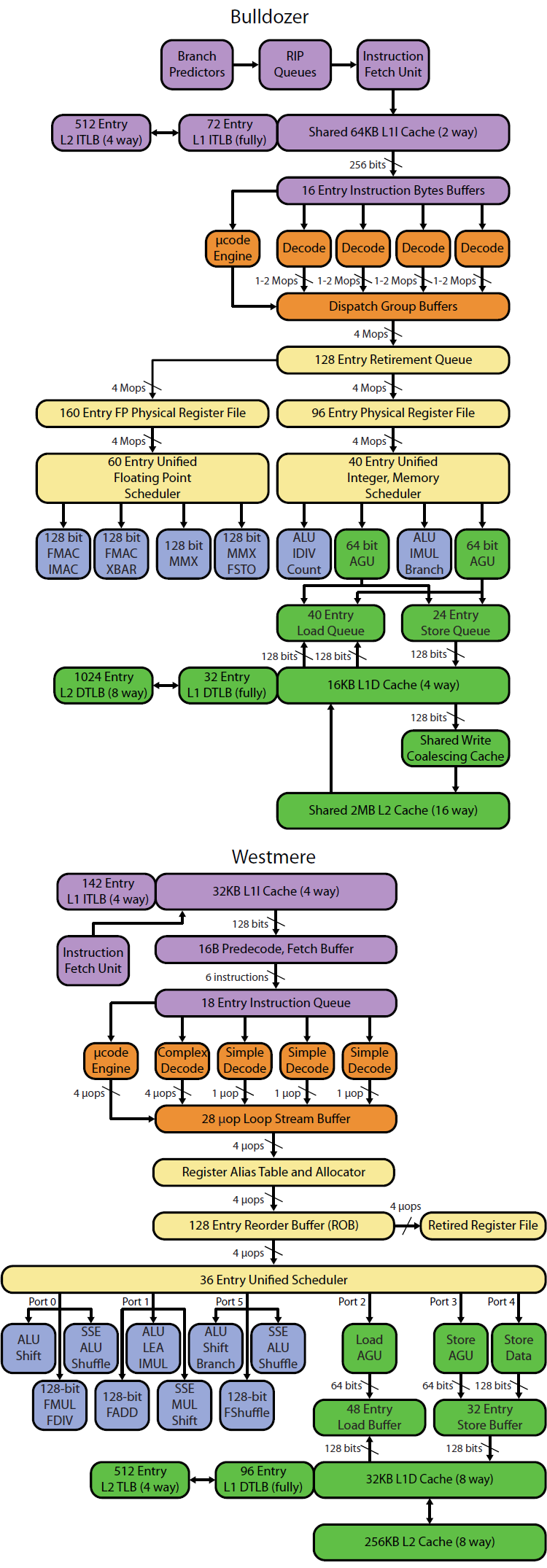
For desktop usage, it's a hard sell. Cutting down on execution units means less IPC (assuming nothing was changed to improve instruction fetch and branch prediction compared to last arch), but the fact that they changed fetch and prediction can tell us one of two things, depending on if we are optimistic or pessimistic.
If we are optimistic, it means something within this line: when they made instruction fetch and branch prediction better (not just more aggressive but decoupling them), they found out that IPC improved to a point that removing the third ALU and AGU resulted in a hit that was still better (maybe far better, depending on how generous you are with adjectives) than their previous case - all that matters is they do hit their target, which they've set way before when all they had was the drawing board, before any real silicon was in their hands.
If we are pessimistic, well, then it's a
"holy-crap-this-arch-is-made-for-serverland-and-now-we-are-stuck-with-low-cost-desktop-chips-to-compensate-for-the-performance" type of scenario. They pretty much removed 33% of the execution units. If the changes above did not result in far beyond 33% improvement, then there's no gain, and 33% is a tough figure to overcome. I, for one, don't want more cores - I love quad-cores just fine, and now I want even-faster quad-cores, not just-as-fast octo-cores.
Which one is a better POV is a tough call. On the more optimistic scale, there are two things that make it believable:
1.) There's been talk before of why the hell the third ALU and AGU is there, that it is more of historical reasons that they are still there. Due to the harder work of optimizing fetch and decode, it's easier to just add or retain (retain = nice to save die space, but unless IPC is improved from somewhere else like faster cache, then don't cut out a unit) execution units to increase IPC (of course, as you can imagine, this is merely to a point - at a certain point adding more units increases IPC less and less, and the diminishing returns come at a great cost of power and space), especially since there hasn't been an overhaul of archs for quite a time. Now that they have worked on a new arch and decided to go the "correct" way, they then improved fetch and prediction, cut an ALU and AGU, and went their merry way. By "correct", I do not mean that the brute force way of adding execution units is the "wrong/lazy" way. Rather, I mean it is more in line with their "perf/mm2" goals - if, after optimizing fetch, the third ALU+AGU is now only adding x% of performance but at y% cost of size&power, and the relationship of x with y is beyond/below their threshold, then it makes sense to cut the third ALU+AGU. In reality it would be more complicated than that, since optimizing and decoupling fetch and prediction didn't come for free (the module design itself isn't free), but they've accounted for those as well.
2.) Cutting out 33% of ALUs and AGUs might be significant enough to actually make performance better even if the optimizations in fetch alone could not make the IPC much better than before. After all, clockspeeds also play a big part. If IPC just increased by 5% due to optimized fetch, but cutting down ALU/AGU by 33% means smaller cores or a smaller chip and X% more clockspeed, then performance per core just went up - it's not just IPC that matters, after all, and slimming down the cores can (not guaranteed, as that's not the only thing to consider) give you more thermal headroom and better clockspeeds. Maybe the act of cutting 33% of their exec units ended up giving them more thermal rope, and that's a good thing, since it's always a balancing act of performance and the thermal envelope you need to be in (IBM might be an exception, if they are done selling their power chips to outsiders - if all they need to service are their midranges and mainframes, they can go crazy with thermals as long as the rest of their mainframe design compensates for it, and all their Z-series already come with their own refrigeration units, even for a "single book" cage, so their thermal limit may well be beyond what Intel and AMD has for now. I have had the misfortune of having to to deal with their Z-series tech manual before, "IBM System Z10 Enterprise Class Technical Guide", and while no TDP figures sticks in my memory - I don't think it ever was mentioned, but I could easily just have forgotten - I remember quite well that uniprocessor performance improved 60% (based on LSPR mixed workload) over Z9 - ~60% single-thread improvement in our language, in one iteration, just a sample of how different IBM's playing field is, compared to us in PC world getting stuck with %s well below that in single-thread performance increase per generation due to much harder power and thermal budgets)
As for the pessimistic, well... I personally just find the cut rather unnerving - although it is too early to tell, I admit. You know, if they cut only the third AGU, I would really be unconcerned. It reminds me of a post from Matthias (Dresdenboy) in July, about ALU:AGU being 4:3 per core, and I thought "
yeah, better ratio". Then of course, here comes Hot Chips and we get... 2:2. So instead of more ALU than AGU, we get less. It's understandable that with less number-crunchers (yep, that's an engineering term now) inside, now it's all up to the fetch and prediction to be loads better. In fact, we better pray Deneb had terrible instruction fetch and prediction (possible), because if it's actually pretty efficient already, we aren't getting much more, and those two ALUs better be damn good.
As I've said earlier in the thread, I'm more "wait-and-see" for Bulldozer, as compared to excited for Bobcat. However, for even more consolation, Matthias seems to be pretty pumped about Bulldozer, expecting it to be almost a 5.2GHz Phenom II in performance. However, when I saw his computation, it is no different from the joke post I made that concludes in 40% performance increase (41%, actually). The only problem there is that it is based on a marketing statement, made from basket benchmarks that are all server loads. There is no way to tell if 40% is possible or not because there is no info on what benchmarks were ran. It makes all the difference because if we did, we can see how bad (or good) the scaling is, and if it is one that hammers the FPU or not (big difference - if it isn't, then ho-hum, but if it is, then better performance can be expected). Anyway, when I saw his post, well... at least that's one person with more credibility than me who thinks Bulldozer can be pretty good, and he damn knows his stuff. Of course, it is worth noting that both our computations hinge on a marketing statement, and we know such statements (especially this early - come on, didn't they just finalize whether or not BD will be AM3 drop-in or not, right? That just isn't good news to measure BD development progress) can easily change.