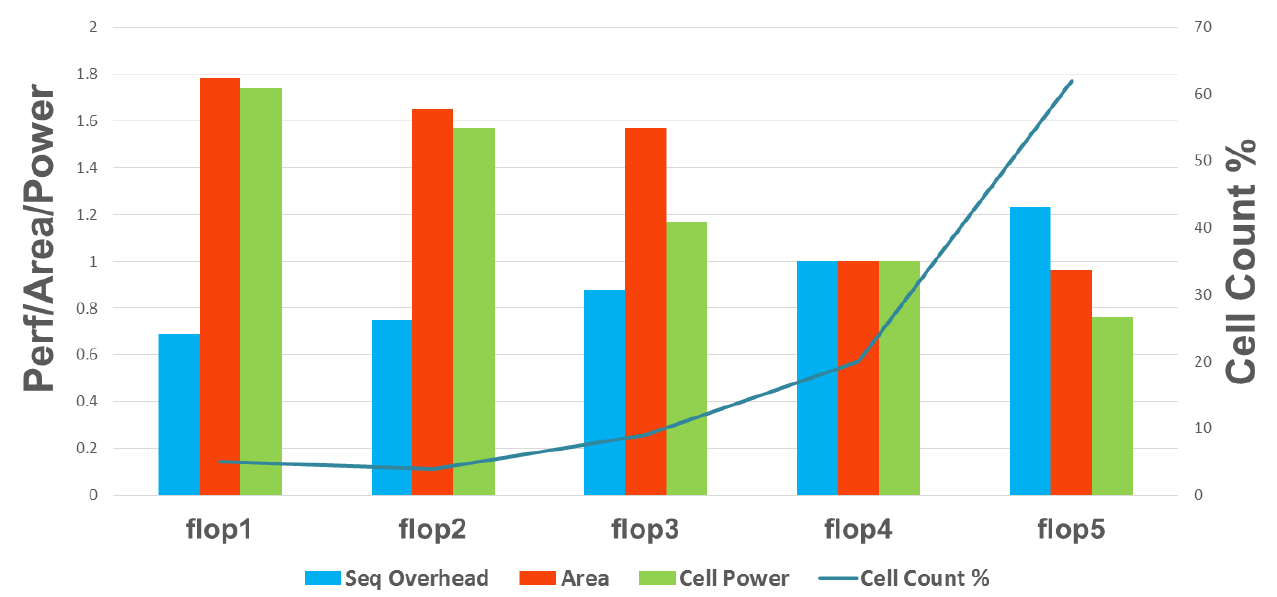
The design of the core was also extensively optimized to use less power. Integrated circuits are built of a variety of standard units such as NAND and NOT logic gates, flipflops, and even more complex elements such as half and full adders. For each of these components (called standard cells), a range of designs is possible with different trade-offs between performance, size, and power consumption.

Enlarge / Fast flipflops, on the left, are large and power-hungry. Most of Zen uses slower, more efficient ones, on the right.
AMD
AMD built a large library of standard cells with different characteristics. For example, it has five different flipflop designs. The fastest is twice as fast as the slowest, but it takes about 80 percent more space and uses more than twice as much power. Armed with this library, Zen was optimized to use the smaller, slower, more efficient parts where it can and the faster, larger, high-performance parts when it must. In Zen, the high-performance design is used for fewer than 10 percent of the flipflops, with the efficient one used about 60 percent of the time.