Yeah actually they should be faster because all the tested games are highly multi-threaded. Oh, well, it still shows that there is a penalty on having dependent threads on two different CCX.Why would not they be?
-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Ryzen: Strictly technical
Page 23 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
- Status
- Not open for further replies.
Kromaatikse
Member
If the schedulers and thread switching were creating the entire problem, You would not be seeing good performance in ANY benchmarks because Thread switching is tied solely to CPU activity.
Thanks to core parking, it appears that single-threaded benchmarks are in fact being kept on one CCX - most of the time. So, even if they are frequently moved between cores, they only suffer context switching and extra L2 misses, which hit in the L3 cache instead. That's a relatively minor problem, and Ryzen is well-equipped to deal with it since its L3 cache is high-bandwidth and reasonably low-latency.
With a full multi-threaded benchmark which uses all available cores (virtual and otherwise), the scheduler doesn't move threads around because there are no idle cores to move them to. Context-switch overhead and excess cache misses go away. Furthermore, most workloads of this type are "embarrassingly parallelisable" which means very little communication between threads is necessary for correct results - mostly "I've finished this batch" and "Here's another one to work on". Inter-CCX traffic therefore remains low, and Ryzen still performs very well.
Games don't cleanly fall into either of the above categories. Modern game engines are multithreaded to some degree, but they generally can't keep all 16 hardware threads busy at once, yet they *can* keep the CPU busy enough for many (if not all) cores to be unparked. Worse, they are not running clean, uniform, embarrassingly-parallelisable algorithms, but a heterogeneous mixture of producers and consumers which are *constantly* communicating and synchronising among themselves. This, for Ryzen, is the worst-case scenario.
And that's why we're talking about the problem in these terms - if we can tame Windows' scheduler, Ryzen will run faster in games.
Kromaatikse
Member
What I don't like about the specific benchmark, is that it is single player. Multiplayer BF1 needs ~50% more CPU resources.
Aha - I was trying to re-find that using Google, and failed. Forgot it was in German.
sirmo
Golden Member
depends.. 3+3 cores could mean more L3 cache.guessing people that buy the 6 core R5 are going to really want 4+2 enabled cores instead of 3+3 enabled cores if their purchase is for gaming
I'm assuming R5s are R7s with 2 cores disabled
powerrush
Junior Member
Hi, Somebody tested this:
Processor Performance Core Parking Min Cores
The minimum percentage of logical processors (in terms of all logical processors that are enabled on the system) that can be placed in the unparked state at any given time. For example, on a system with 16 logical processors, configuring the value of this setting to 25% ensures that at least 4 logical processors are always in the unparked state. The Core Parking algorithm is disabled if the value of this setting is not less than the value of the Processor Performance Core Parking Maximum Cores setting.
GUID 0cc5b647-c1df-4637-891a-dec35c318583
ideal for ryzen = 50 % = 8 logical threads unparked. Just 4 cores unparked all the time. Maybe it will put the first 4 cores in unparked state and the other 4 cores of the second ccx in parked state if they aren't used. It is a suggestion, i haven't Ryzen in my hands... :...(
This can be done with process lasso too...

Processor Performance Core Parking Min Cores
The minimum percentage of logical processors (in terms of all logical processors that are enabled on the system) that can be placed in the unparked state at any given time. For example, on a system with 16 logical processors, configuring the value of this setting to 25% ensures that at least 4 logical processors are always in the unparked state. The Core Parking algorithm is disabled if the value of this setting is not less than the value of the Processor Performance Core Parking Maximum Cores setting.
GUID 0cc5b647-c1df-4637-891a-dec35c318583
ideal for ryzen = 50 % = 8 logical threads unparked. Just 4 cores unparked all the time. Maybe it will put the first 4 cores in unparked state and the other 4 cores of the second ccx in parked state if they aren't used. It is a suggestion, i haven't Ryzen in my hands... :...(
This can be done with process lasso too...
Kromaatikse
Member
Hi, Somebody tested this:
Processor Performance Core Parking Min Cores
ideal for ryzen = 50 % = 8 logical threads unparked. Just 4 cores unparked all the time. Maybe it will put the first 4 cores in unparked state and the other 4 cores of the second ccx in parked state if they aren't used. It is a suggestion, i haven't Ryzen in my hands... :...(
Unfortunately, that would probably (certainly on Win7) result in 8 physical cores being unparked, one virtual core each. That's because the Core Parking algorithm is "SMT-aware" and always optimises for performance in that sense.
This isn't how it works, the setting you've highlighted parks at a minimum 4 cores (plus SMT?) when the system is idle. That's it, if the max number of cores t(hat can be parked) is also set to 50% or whatever, using park control, then that means even in the "lightest performance" state there would be a maximum of 4 cores parked. Generally the maximum number of cores that can be parked is higher than the minimum number, so essentially every core can be parked except the first one AFAIK, the first is parked when the system enters sleep. Core parking works only when the system is idle, AFAIK the idle cores are easily unparked on user interaction or any background activity, depending on the increase policy.Hi, Somebody tested this:
Processor Performance Core Parking Min Cores
The minimum percentage of logical processors (in terms of all logical processors that are enabled on the system) that can be placed in the unparked state at any given time. For example, on a system with 16 logical processors, configuring the value of this setting to 25% ensures that at least 4 logical processors are always in the unparked state. The Core Parking algorithm is disabled if the value of this setting is not less than the value of the Processor Performance Core Parking Maximum Cores setting.
GUID 0cc5b647-c1df-4637-891a-dec35c318583
ideal for ryzen = 50 % = 8 logical threads unparked. Just 4 cores unparked all the time. Maybe it will put the first 4 cores in unparked state and the other 4 cores of the second ccx in parked state if they aren't used. It is a suggestion, i haven't Ryzen in my hands... :...(
So if I understand you correctly you'd like to see how 4 (real) cores work along with SMT vs 8 cores using park control, but even in case you carefully tweaked enough settings through Windows, the system process would still access the other CCX, the only way to stop that would be to disable it through BIOS. At this point in time I'm not aware of any method where inter CCX communication can be halted without physically disabling the cores.
Last edited:
Is there any way to convince Windows to see each Ryzen CCX as a separate CPU (i.e. treat it as a 2P system with two 4C/8T processors)? It would be interesting to see if that improved the performance by stopping it from shuffling threads around between processors.
On that subject, why does Windows find it necessary to do this thread-shuffling in the first place? Apparently other OSes do not.
On that subject, why does Windows find it necessary to do this thread-shuffling in the first place? Apparently other OSes do not.
I know how it works, why don't you try a few mouse clicks & see if any number of cores are unparked?
It Works like that.... Not idle...
The setting you're looking for is increase policy, unless we're talking about different things ~The mínimum percentage of logical cores (aka threads) that can be in the unparked state at any given time

Yeah I get that but I don't think you're getting what I'm trying to say.The minimum percentage of logical processors (in terms of all logical processors that are enabled on the system) that can be placed in the unparked state at any given time.
Did you read that?
Edit - don't see how core parking or unparking would tell how threads interspersed between the two CCX hamper gaming.
Last edited:
powerrush
Junior Member

I forget to mention that i have set core overutilization at 100%
Edited "High Performance power profile" with:
943c8cb6-6f93-4227-ad87-e9a3feec08d1
Processor Performance Core Parking Overutilization Threshold
Set at 100%
ea062031-0e34-4ff1-9b6d-eb1059334028
Processor Performance Core Parking Max Cores
Set at 100%
0cc5b647-c1df-4637-891a-dec35c318583
Processor Performance Core Parking Min Cores
Set at 50%
Last edited:
gtbtk
Junior Member
Thanks to core parking, it appears that single-threaded benchmarks are in fact being kept on one CCX - most of the time. So, even if they are frequently moved between cores, they only suffer context switching and extra L2 misses, which hit in the L3 cache instead. That's a relatively minor problem, and Ryzen is well-equipped to deal with it since its L3 cache is high-bandwidth and reasonably low-latency.
With a full multi-threaded benchmark which uses all available cores (virtual and otherwise), the scheduler doesn't move threads around because there are no idle cores to move them to. Context-switch overhead and excess cache misses go away. Furthermore, most workloads of this type are "embarrassingly parallelisable" which means very little communication between threads is necessary for correct results - mostly "I've finished this batch" and "Here's another one to work on". Inter-CCX traffic therefore remains low, and Ryzen still performs very well.
Games don't cleanly fall into either of the above categories. Modern game engines are multithreaded to some degree, but they generally can't keep all 16 hardware threads busy at once, yet they *can* keep the CPU busy enough for many (if not all) cores to be unparked. Worse, they are not running clean, uniform, embarrassingly-parallelisable algorithms, but a heterogeneous mixture of producers and consumers which are *constantly* communicating and synchronising among themselves. This, for Ryzen, is the worst-case scenario.
And that's why we're talking about the problem in these terms - if we can tame Windows' scheduler, Ryzen will run faster in games.
I am not saying that there is absolutely no impact, however the thread switching impact will be minimal. Games are not the only applications that are moderately multi threaded but you are not seeing performance drops in anything except gaming. It would seem that you didn't bother to actually read what I wrote before. Thread switching speed is totally reliant on available DF bandwidth, so it will be impacted it there is no or limited additional capacity. No argument, but it is still a symptom and not the cause.
But you keep believing that if it makes you happy. It doesn't make much time to actually test out what I am saying and see for yourself but who wants to gather those pesky facts?
Kromaatikse
Member
As I very specifically said, games are a very special kind of workload, with lots of inter-thread communication. This both reduces the average number of running threads at any given instant (confusing Windows' scheduler) and increases memory traffic between threads - which, if they happen to be on opposite CCXes, increases inter-CCX traffic greatly.
Consider that one of those threads is typically responsible for delivering draw calls and texture uploads to the GPU (in an OpenGL or DX11 game), but the calls' data is generated by *other* threads so that the "render" thread can run as fast as possible. These in turn rely on gobs of data from the physics and AI threads, which might be on the same CCX as the render thread but the opposite one to the generator threads...
...and all this data transfer is repeated upwards of 100 times a second, ideally. That's a *lot* of inter-CCX traffic, and with the user closely observing every tiny little hitch, stutter and speck of input lag.
Now, please, who is the one not reading and understanding what the other posts?
Consider that one of those threads is typically responsible for delivering draw calls and texture uploads to the GPU (in an OpenGL or DX11 game), but the calls' data is generated by *other* threads so that the "render" thread can run as fast as possible. These in turn rely on gobs of data from the physics and AI threads, which might be on the same CCX as the render thread but the opposite one to the generator threads...
...and all this data transfer is repeated upwards of 100 times a second, ideally. That's a *lot* of inter-CCX traffic, and with the user closely observing every tiny little hitch, stutter and speck of input lag.
Now, please, who is the one not reading and understanding what the other posts?
looncraz
Senior member
Is there any way to convince Windows to see each Ryzen CCX as a separate CPU (i.e. treat it as a 2P system with two 4C/8T processors)? It would be interesting to see if that improved the performance by stopping it from shuffling threads around between processors.
On that subject, why does Windows find it necessary to do this thread-shuffling in the first place? Apparently other OSes do not.
Yes:
bcdedit.exe /set groupsize 8
Now the OS will treat Ryzen as two distinct socketed CPUs for four cores and SMT each.
CatMerc
Golden Member
Has anyone attempted game benchmarks with this?Yes:
bcdedit.exe /set groupsize 8
Now the OS will treat Ryzen as two distinct socketed CPUs for four cores and SMT each.
looncraz
Senior member
Has anyone attempted game benchmarks with this?
It's part of my alternative config testing. Not sure how I'm going to get all of this in an article, LOL!
Definitely will need to change layout from original intentions: http://zen.looncraz.net/
gtbtk
Junior Member
You even state in your answer
"...and all this data transfer is repeated upwards of 100 times a second, ideally. That's a *lot* of inter-CCX traffic, and with the user closely observing every tiny little hitch, stutter and speck of input lag."
What do you think the inter CCX traffic is running on?
That would be the Data Fabric.....
"...and all this data transfer is repeated upwards of 100 times a second, ideally. That's a *lot* of inter-CCX traffic, and with the user closely observing every tiny little hitch, stutter and speck of input lag."
What do you think the inter CCX traffic is running on?
That would be the Data Fabric.....
lolfail9001
Golden Member
I believe Kyle has posted that his gaming benchmarks did not change one iota after trying that. Maybe it's broken in Win10 too 😛.Has anyone attempted game benchmarks with this?
http://www.hardocp.com/news/2017/03/03/ryzen_smt_groupaware_groupsize_settings
looncraz
Senior member
You even state in your answer
"...and all this data transfer is repeated upwards of 100 times a second, ideally. That's a *lot* of inter-CCX traffic, and with the user closely observing every tiny little hitch, stutter and speck of input lag."
What do you think the inter CCX traffic is running on?
That would be the Data Fabric.....
It also belies traffic snooping logic that eliminates hops. The signal doesn't need to be repeated on an on-die HT bus, there's a 48-bit address packet that is sent - if that applies to your link, you read the packet, if it doesn't... you ignore it.
It's a low latency, low overhead, connection. Making a trip on the longest HT 3.1 pathway on Ryen should take <1ns. Of course, there's always the matter of finding a place in the data stream on the bus... and if there are hubs to enable prioritization... well, that will incur a latency penalty.
If I weren't busy testing Ryzen, I'd make a graphic of how I think things are connected to minimize that issue. But I still have no idea how they connect those darn far-flung DDR4 PHYs...
CatMerc
Golden Member
Is Windows aware of what parts of the chip should be split?I believe Kyle has posted that his gaming benchmarks did not change one iota after trying that. Maybe it's broken in Win10 too 😛.
http://www.hardocp.com/news/2017/03/03/ryzen_smt_groupaware_groupsize_settings
As in we are setting groupsize of 8, but how can we know it's not splitting those 8 between both CCX's?
looncraz
Senior member
Is Windows aware of what parts of the chip should be split?
As in we are setting groupsize of 8, but how can we know it's not splitting those 8 between both CCX's?
Windows CPU grouping is always linear with the logical cores... at least on Intel... I haven't actually tried it on Ryzen, yet.
deadhand
Junior Member
Unfortunately my attempts at writing a micro benchmark have produced wildly inconsistent results, so I do not feel comfortable posting them until I figure out what's going on, of which I don't have any more time for today. (It can be very difficult to test the right thing with micro benchmarks)
Sometime next week I plan to go through it more in-depth and read through an assembly listing to see what is actually being produced by MSVC.
Anyway, I'm interested in exploring the performance penalties of 'False Sharing' on Ryzen.
In effect, 'False Sharing' is what occurs when a thread is writing to data located on the same cache line that another thread is attempting to access. As I understand it, only one core can have a lock on the cache line when it's being modified, so this produces a dependency between threads that is not obvious to the programmer. It's a serialization of resource access where the entire cache line is bounced back and forth between cores, even if each thread are operating on completely different (but within the same cache line) memory locations, and are otherwise embarrassingly parallel.
So, what's the effects of false sharing on performance?
1. CPU utilization will appear high, even maxing out, while a given core is waiting to get exclusive access to a cache line (if it needs to perform a write).
2. It's very difficult to actually detect false sharing - most profilers will simply show you hot spots in your code, unless you have access to hardware performance counters.
In blue, all threads are on separate cache lines. In red, all threads share the same cache line, even when they're not modifying or reading from the same data. The performance can actually get worse (scaling with thread count) than just using a single thread in this kind of extreme scenario.
Of course, the following graph shows an extreme scenario of False Sharing, in the real world you might just see poor thread scaling as they won't constantly be accessing the same cache line, nor constantly writing.
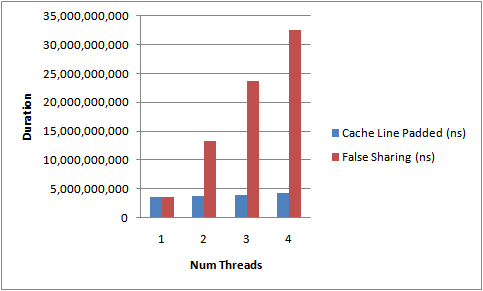
Source: https://mechanical-sympathy.blogspot.ca/2011/07/false-sharing.html
Here's a diagram of a cache line being accessed by two different threads. As you can clearly see, the threads are operating on different pieces of data.
On modern x86 CPUs, a cache line is 64 bytes (irrespective of 64 bit or 32 bit, to anyone who might try and make that connection). Thus, you could have an array of 16 integers (adjusted to the beginning of a cache line boundary), and if a single one is being modified by a thread while another is being read by another thread, the other thread will have to wait.

Source: https://software.intel.com/en-us/articles/avoiding-and-identifying-false-sharing-among-threads
Here's an example of how false sharing can look on a CPU utilization graph, and how deceiving it can be:
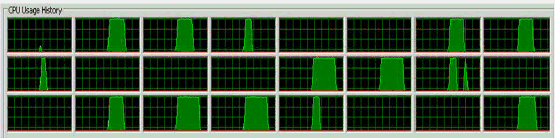
Source: http://www.drdobbs.com/parallel/eliminate-false-sharing/217500206?pgno=2
Below is a single thread doing the same amount of work, but faster, and with significantly less overall CPU utilization: (the total amount of work being done appears to be much smaller, but it's actually the same!)
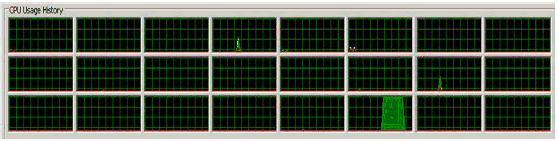
Source: http://www.drdobbs.com/parallel/eliminate-false-sharing/217500206?pgno=2
So, what I'm interested in finding out, is:
1. How prevalent is false sharing in game engines? Even the software I tested on Page 9 ( https://forums.anandtech.com/threads/ryzen-strictly-technical.2500572/page-9#post-38776310 ) appears to exhibit this behavior when I push it through a profiler (huge number of hot spots on a few load instructions). It also fails to scale beyond ~8 threads, with very little benefit beyond 4.
2. Is the serializing effects of false sharing (which essentially increases the 'serialized' portion in Amdahl's law with thread count, thus reducing scaling the more false sharing that occurs) exacerbated with NUMA and NUMA-like topologies (in the case of Ryzen)? Could the increased cache coherency traffic saturate the bandwidth of QPI, or, in the case of Ryzen, the inter-CCX fabric? Is there a higher latency penalty with cache line bouncing between CCX's vs within a single CCX?
Unfortunately I can't answer these questions as I don't believe I have the knowledge to give a clear answer, but I'm hoping someone like @Dresdenboy would be able to chime in.
Sometime next week I plan to go through it more in-depth and read through an assembly listing to see what is actually being produced by MSVC.
Anyway, I'm interested in exploring the performance penalties of 'False Sharing' on Ryzen.
In effect, 'False Sharing' is what occurs when a thread is writing to data located on the same cache line that another thread is attempting to access. As I understand it, only one core can have a lock on the cache line when it's being modified, so this produces a dependency between threads that is not obvious to the programmer. It's a serialization of resource access where the entire cache line is bounced back and forth between cores, even if each thread are operating on completely different (but within the same cache line) memory locations, and are otherwise embarrassingly parallel.
So, what's the effects of false sharing on performance?
1. CPU utilization will appear high, even maxing out, while a given core is waiting to get exclusive access to a cache line (if it needs to perform a write).
2. It's very difficult to actually detect false sharing - most profilers will simply show you hot spots in your code, unless you have access to hardware performance counters.
In blue, all threads are on separate cache lines. In red, all threads share the same cache line, even when they're not modifying or reading from the same data. The performance can actually get worse (scaling with thread count) than just using a single thread in this kind of extreme scenario.
Of course, the following graph shows an extreme scenario of False Sharing, in the real world you might just see poor thread scaling as they won't constantly be accessing the same cache line, nor constantly writing.
Source: https://mechanical-sympathy.blogspot.ca/2011/07/false-sharing.html
Here's a diagram of a cache line being accessed by two different threads. As you can clearly see, the threads are operating on different pieces of data.
On modern x86 CPUs, a cache line is 64 bytes (irrespective of 64 bit or 32 bit, to anyone who might try and make that connection). Thus, you could have an array of 16 integers (adjusted to the beginning of a cache line boundary), and if a single one is being modified by a thread while another is being read by another thread, the other thread will have to wait.
Source: https://software.intel.com/en-us/articles/avoiding-and-identifying-false-sharing-among-threads
Here's an example of how false sharing can look on a CPU utilization graph, and how deceiving it can be:
Source: http://www.drdobbs.com/parallel/eliminate-false-sharing/217500206?pgno=2
Below is a single thread doing the same amount of work, but faster, and with significantly less overall CPU utilization: (the total amount of work being done appears to be much smaller, but it's actually the same!)
Source: http://www.drdobbs.com/parallel/eliminate-false-sharing/217500206?pgno=2
So, what I'm interested in finding out, is:
1. How prevalent is false sharing in game engines? Even the software I tested on Page 9 ( https://forums.anandtech.com/threads/ryzen-strictly-technical.2500572/page-9#post-38776310 ) appears to exhibit this behavior when I push it through a profiler (huge number of hot spots on a few load instructions). It also fails to scale beyond ~8 threads, with very little benefit beyond 4.
2. Is the serializing effects of false sharing (which essentially increases the 'serialized' portion in Amdahl's law with thread count, thus reducing scaling the more false sharing that occurs) exacerbated with NUMA and NUMA-like topologies (in the case of Ryzen)? Could the increased cache coherency traffic saturate the bandwidth of QPI, or, in the case of Ryzen, the inter-CCX fabric? Is there a higher latency penalty with cache line bouncing between CCX's vs within a single CCX?
Unfortunately I can't answer these questions as I don't believe I have the knowledge to give a clear answer, but I'm hoping someone like @Dresdenboy would be able to chime in.
Last edited:
- Status
- Not open for further replies.
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 24K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 24K
-

-
