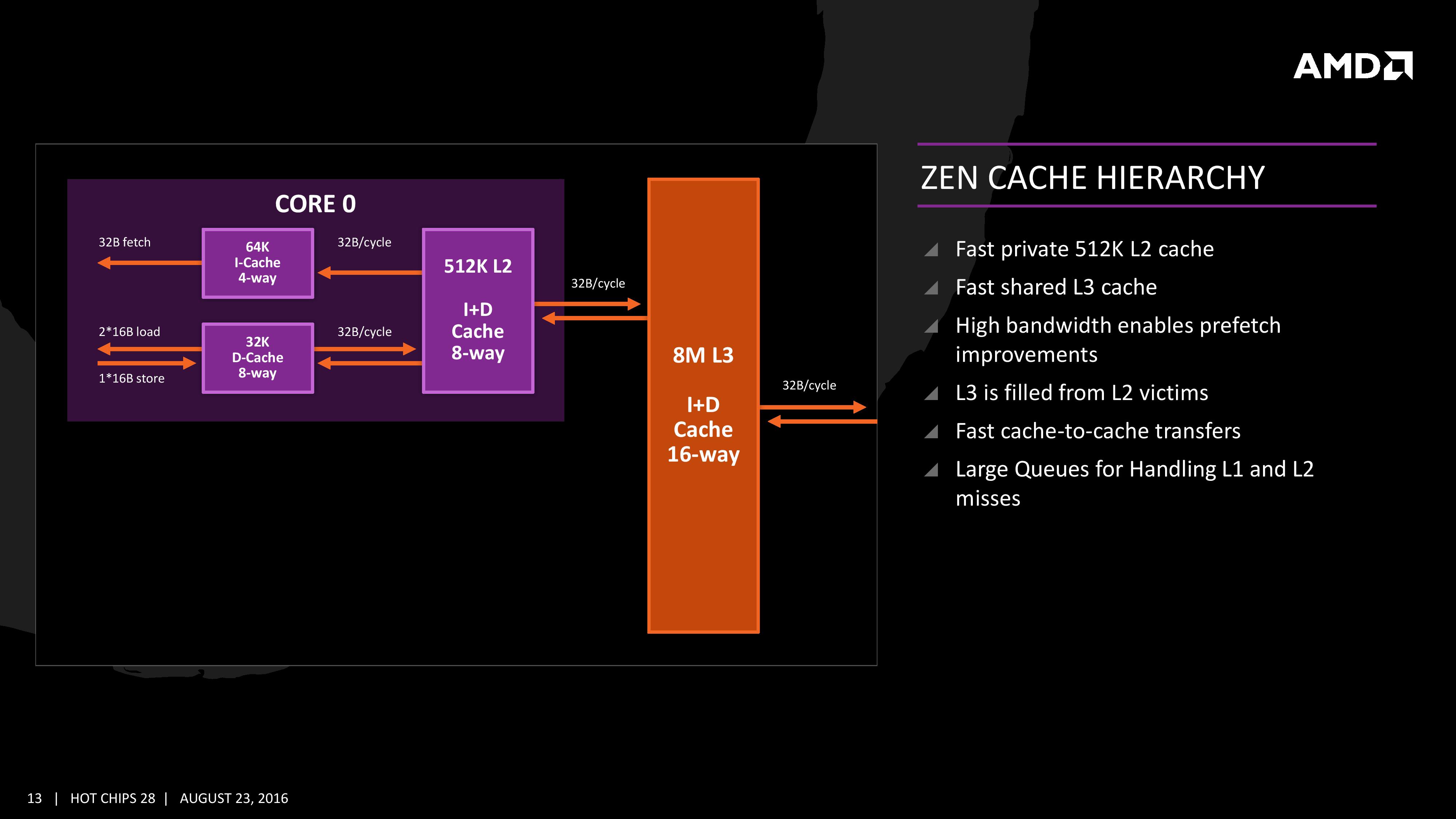
Thanks to core parking, it appears that single-threaded benchmarks are in fact being kept on one CCX - most of the time. So, even if they are frequently moved between cores, they only suffer context switching and extra L2 misses, which hit in the L3 cache instead. That's a relatively minor problem, and Ryzen is well-equipped to deal with it since its L3 cache is high-bandwidth and reasonably low-latency.
With a full multi-threaded benchmark which uses all available cores (virtual and otherwise), the scheduler doesn't move threads around because there are no idle cores to move them to. Context-switch overhead and excess cache misses go away. Furthermore, most workloads of this type are "embarrassingly parallelisable" which means very little communication between threads is necessary for correct results - mostly "I've finished this batch" and "Here's another one to work on". Inter-CCX traffic therefore remains low, and Ryzen still performs very well.
Games don't cleanly fall into either of the above categories. Modern game engines are multithreaded to some degree, but they generally can't keep all 16 hardware threads busy at once, yet they *can* keep the CPU busy enough for many (if not all) cores to be unparked. Worse, they are not running clean, uniform, embarrassingly-parallelisable algorithms, but a heterogeneous mixture of producers and consumers which are *constantly* communicating and synchronising among themselves. This, for Ryzen, is the worst-case scenario.
And that's why we're talking about the problem in these terms - if we can tame Windows' scheduler, Ryzen will run faster in games.

 From your wikichip link (and elsewhere):
From your wikichip link (and elsewhere):