A Diagram of Ryzen’s Clock Domains
For the past few days, there have been talks around tech forums about Ryzen’s clock domains. Specifically about how some parts of the internal fabric of Ryzen run at memory clockspeed, or half effective transfer speed.
Thanks to hardware.fr, we now have a diagram of the clock domains in Ryzen.

From the above diagram, we can conclude there are three major clock domains in Ryzen:
- CClk (Core Clock): The speed advertised on the box, and the speed at which the cores and cache run at
- LClk (Data Launch Clock): A fixed frequency at which the IO Hub Controller (PCI-E and friends) operates
- MemClk (Memory Clock): The memory clock speed, half of the number you see advertised (1.3GHz for 2667, as an example)
As can be seen in the diagram, the internal Data Fabric, part of the Infinity Fabric advertised by AMD, runs in the MemClk domain.
The Data Fabric is reponsible for the core’s communication with the memory controller, and more importantly, inter-CCX communication.
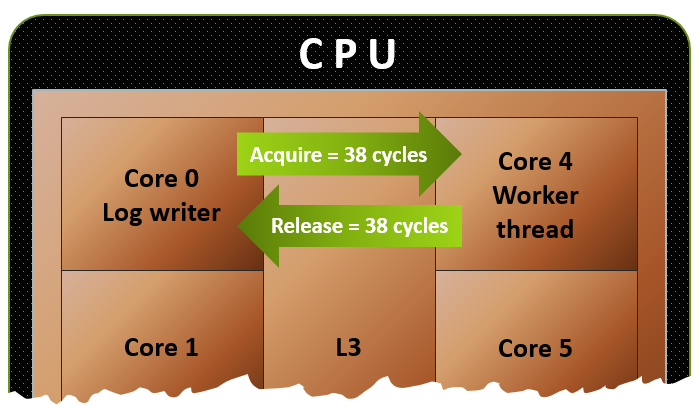
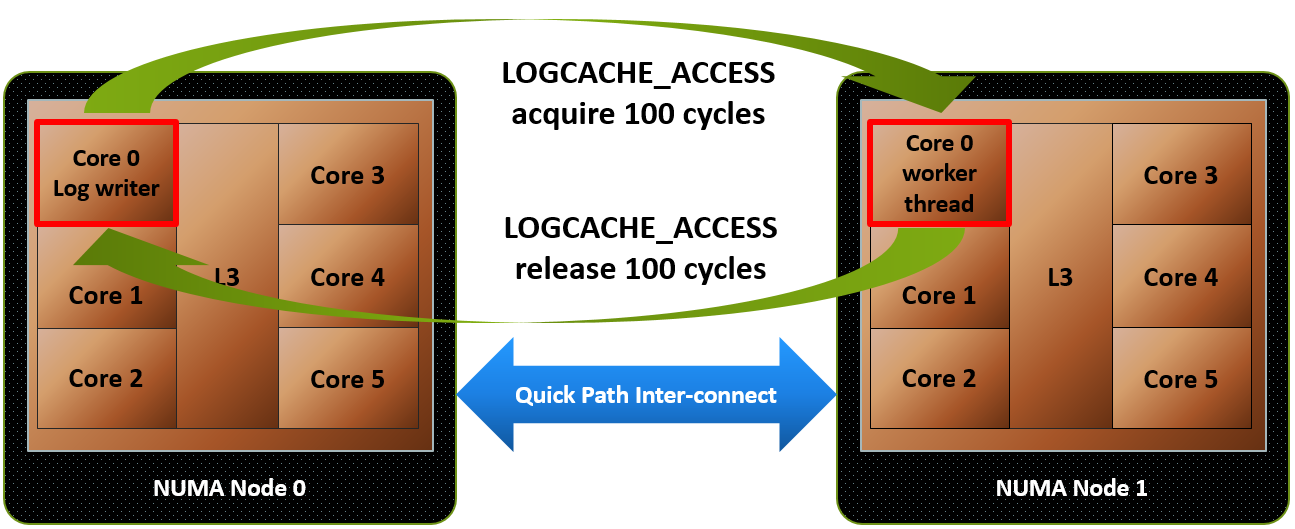
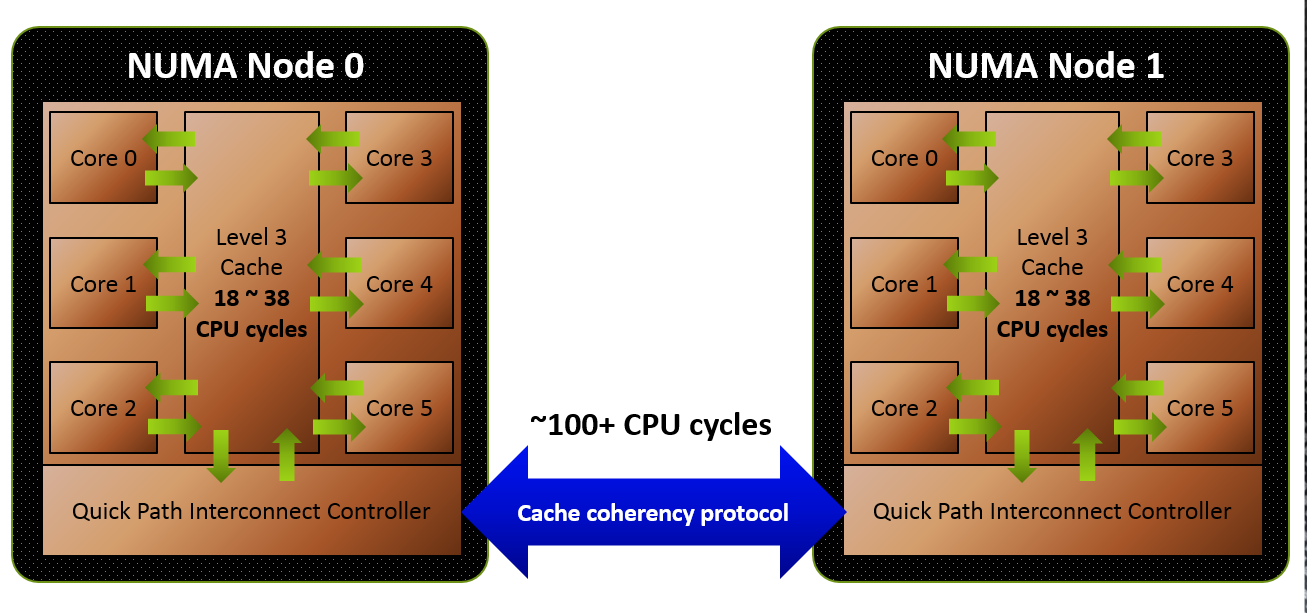
As previously explained, AMD’s Ryzen is built in modular blocks called CCX’s, each contianing four cores and its own bank of L3 cache. An 8 core chip like Ryzen contains two of these. In order for CCX to CCX communication to take place, such as when a core from CCX 0 attempts to access data in the L3 cache of CCX 1, it has to do so through the Data Fabric. Assuming a standard 2667MT/s DDR4 kit, the Data Fabric has a bandwidth of 41.6GB/s in a single direction, or 83.2GB/s when transfering in both directions. This bandwidth has to be shared between both inter-CCX communication, and DRAM access, quickly creation data contention whenever a lot of data is being transfered from CCX to CCX at the same time as reading or writing to and from memory.
Memory Scaling
To put things into perspective, communication to and from cores to L3 cache inside the same CCX happens at around 200GB/s. Combine this with the massive difference in latency you would expect from having to go through extra hoops to reach the other CCX, and the communication speed between CCX’s is simply not anywhere near intra-CCX communication speeds. This is why changing the Windows scheduler to keep data from a single thread in the same CCX is so important, as otherwise you incur a performance penalty, as observed in gaming performance tests.
As observed in multiple tests, Ryzen appears to scale quite well with memory speeds, and this knowledge sheds light on why. It’s not necessarily the increased speeds with the DDR4 kits themselves, though it certainly helps. Rather, it’s the increased internal bandwidth for inter-CCX communication, which alleviates some of the performance issues when threads have to communicate between CCX’s.
Due to this, if you’re picking up a Ryzen system, it’s highly recommended to get a decently fast memory kit, as it will help performance more than you would otherwise expect.
Why is it built this way?
Well, the answer is quite simple. AMD as a semi-custom company, would like to have modularity in their designs. Instead of building a large monolithic 8 core complex that would be relatively hard to scale, they’ve created a quad core building block, from which they can scale core counts as as they see fit. This reduces design costs and time to market for their customers.
There is a trade off, as detailed above. However, as seen in the impressive performance of Ryzen, it’s not too hampering. As soon as the Windows scheduler gets updated to minimize movement of data between CCX’s, and developers release patches in the few games where that will not be enough to solve issues, the gaming performance should be similar to the performance of a 6900K, just like with professional workloads.
https://thetechaltar.com/amd-ryzen-clock-domains-detailed/