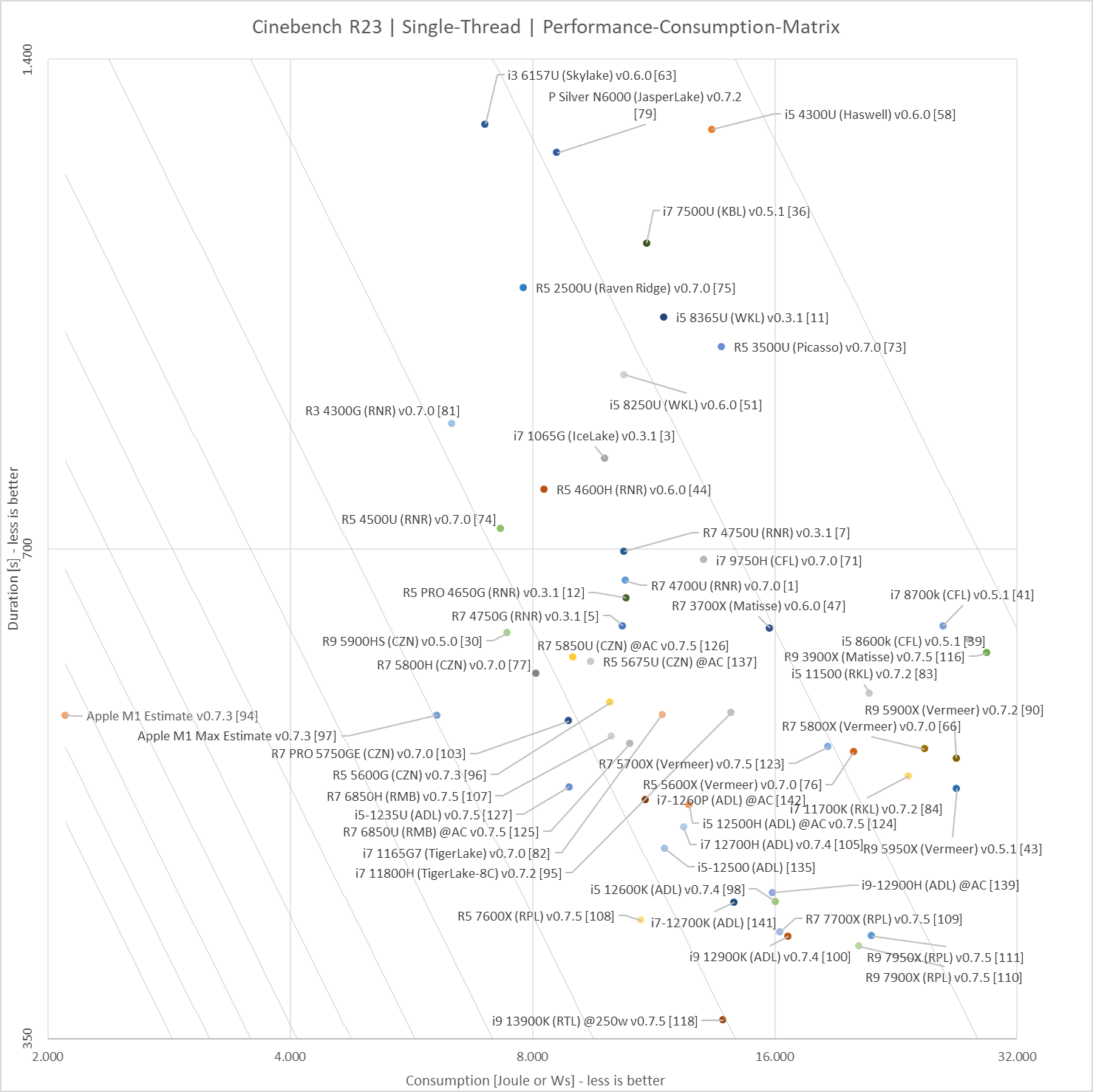
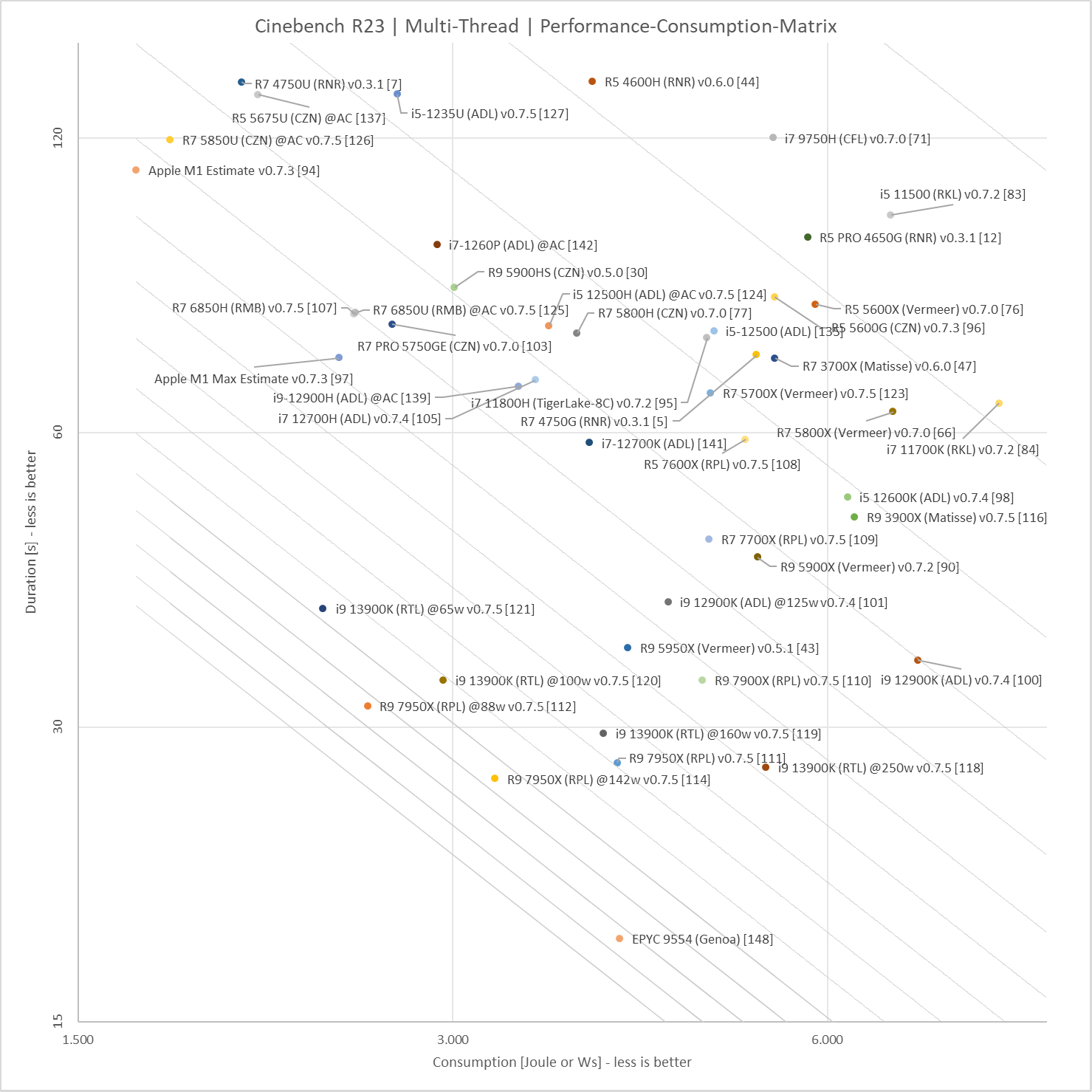
Okay, I was able to finish a Quick Research on each core area(mm2 on the die) and performance using Geekbench I will try to find info for power usage.
We've run thousands of CPU benchmarks on all new and older Intel and AMD CPUs and ranked them.

www.anandtech.com
So these scores are for Performance per Area(square millimeter)
A single Apple Firestorm core is about 9 mm2 in size, they get about 1740 points on GB5, that puts them at 193 points per area.
A single Amd Zen3 core is about 6.5 mm2 in size, they get about 1500 points on GB5, that puts them at 230 points per area.
A single Intel Golden Cove core is 10.5 mm2 and they get abut 190 points on GB5, that gets them about 100 points per area.
Edit.
Also as I pointed out earlier, this is 1C/1T which puts the X86 CPUs on a disadvantage when compared to a 1C/1T Apple Firestorm. so add about 30% performance per core since the HT/SMT is already built on the Core