-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Question Performanc per Area and Performance per Watt of Apple Firestorm vs Zen 3 vs Intel Golden Cove ?
- Thread starter FlameTail
- Start date
-
- Tags
- core performance
Det0x
Golden Member
Performance in what ? Cinebench r23 or Cpumark99 ? Packman ?
What architecture of Zen3 ? APU or 5xx0 series or maybe Epyc ? What Alder lake SKU ? At what binning, cherry picked silicon or over how big average sample size ?
Area including what ? Cores alone ? Uncore? with or without L1, L2 and L3 ? Memory controller ? IO die for Zen3 ? Maybe you mean mm2 socket ?
How do you measure power ? In idle or in what workload ? avx512 or SSE ? Including gpu (apu) ? Powerdraw shown in hwinfo or measured from the wall ? What bios settings, MCE enabled ?
Your question is like me asking what the color purple taste like.. it have no meaning.
What architecture of Zen3 ? APU or 5xx0 series or maybe Epyc ? What Alder lake SKU ? At what binning, cherry picked silicon or over how big average sample size ?
Area including what ? Cores alone ? Uncore? with or without L1, L2 and L3 ? Memory controller ? IO die for Zen3 ? Maybe you mean mm2 socket ?
How do you measure power ? In idle or in what workload ? avx512 or SSE ? Including gpu (apu) ? Powerdraw shown in hwinfo or measured from the wall ? What bios settings, MCE enabled ?
Your question is like me asking what the color purple taste like.. it have no meaning.
Last edited:
moinmoin
Diamond Member
This tool tries to make performance per watt comparable based on Cinebench 23:
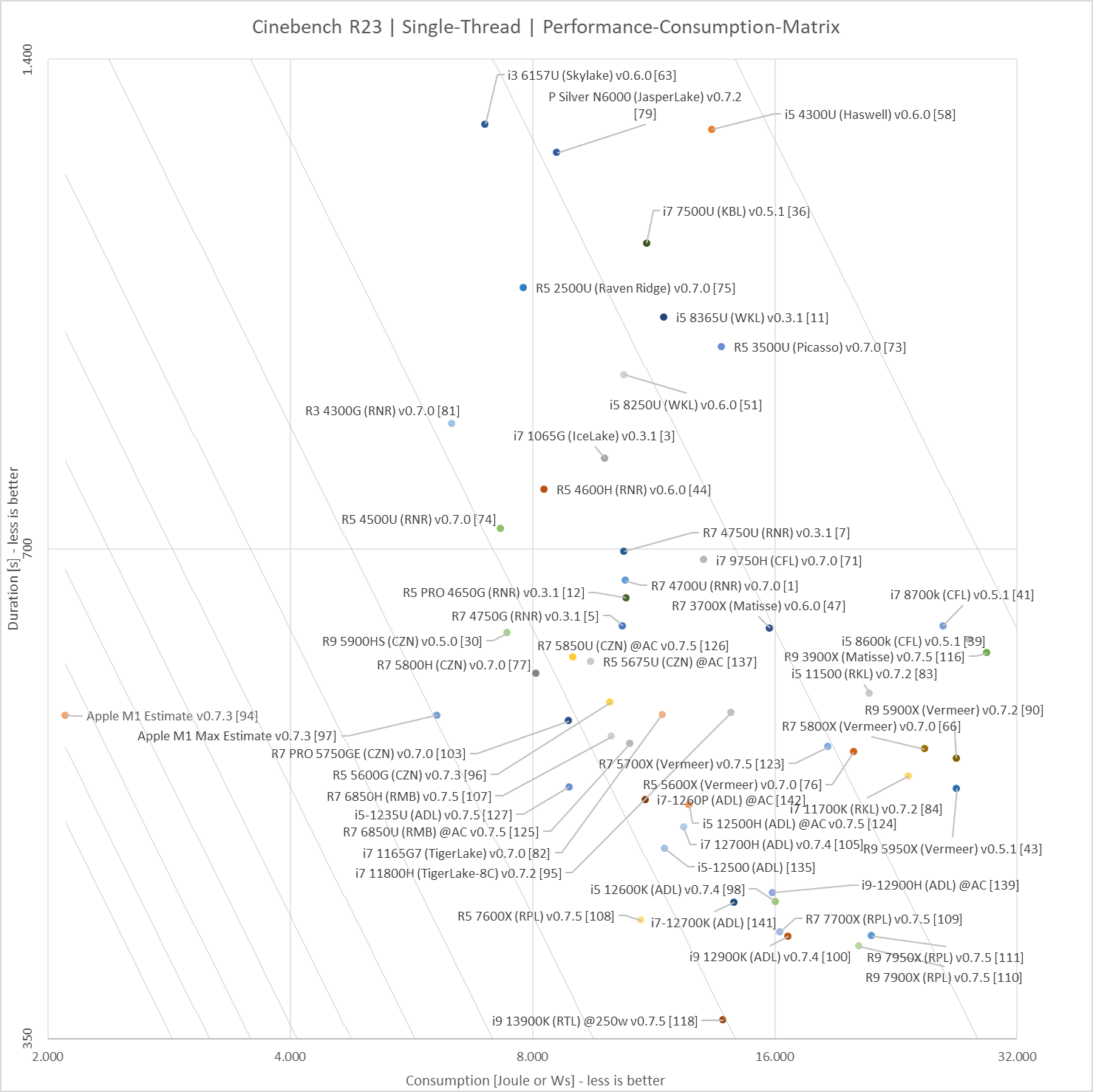
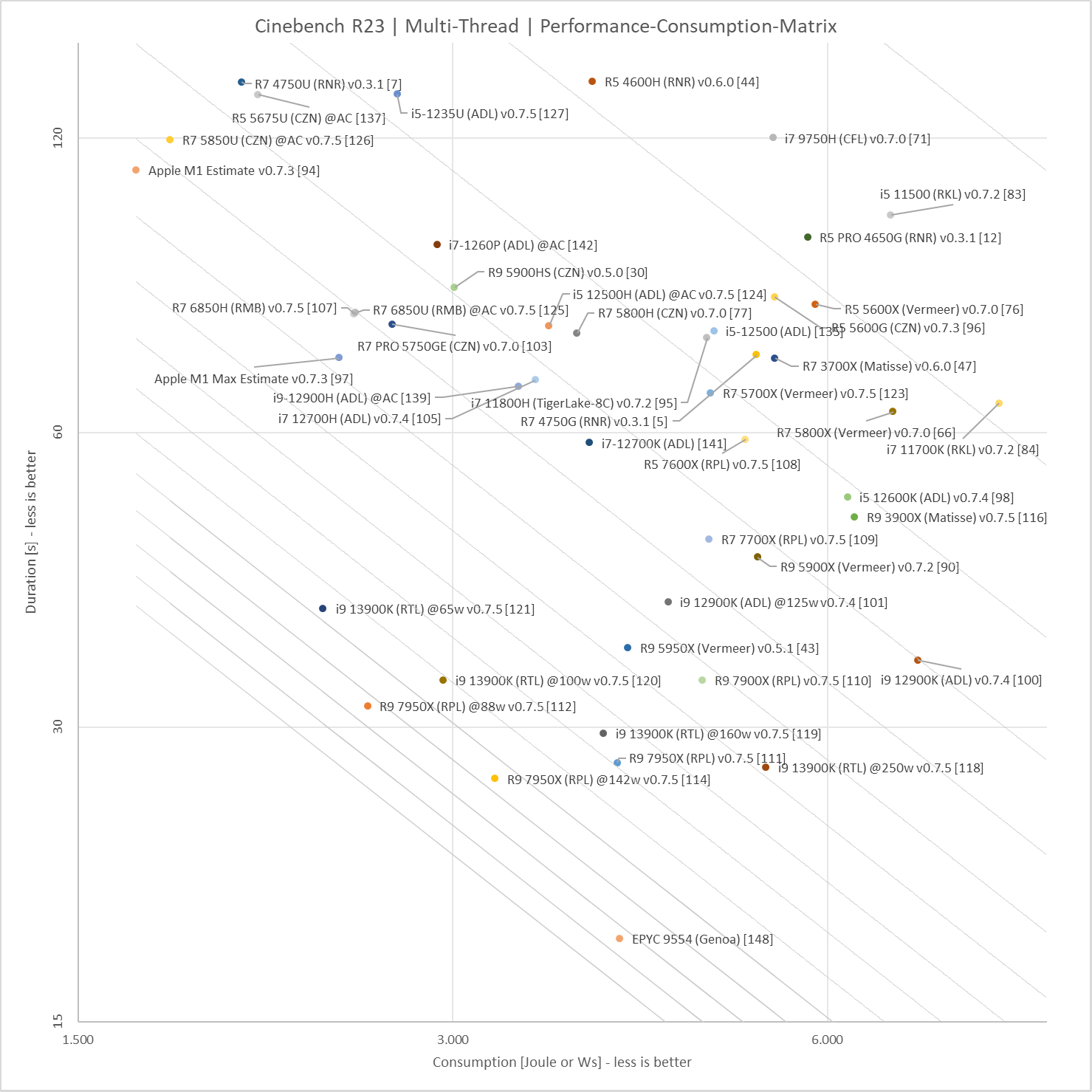
But most of the questions raised by Det0x still apply.
Discussion - PES | Assessing Power and Performance Efficiency of x86 CPU architectures
Dear Community, so this is my first thread here as a long-time lurker - but I felt the desire to share a small hobby-project of mine from the last couple of months with you... Performance Efficiency Suite - What is it about? Most Reviewers solely focus on what they consider to be the most...
forums.anandtech.com
But most of the questions raised by Det0x still apply.
nicalandia
Diamond Member
Can someone calculate the [1] Performance per Area and [2] Performance per Watt of the following cores:
1) Apple Firestorm
2) AMD Zen 3
3) Intel Golden Cove
Thanks in advance : )
Edit : I Wouldn't mind values of Sunny Cove if Golden Cove isn't available.
Performance per area would need to be taken as a whole(with SMT On and full $Cache) because HT/SMT only takes about 5% of die area.
nicalandia
Diamond Member
Okay, I am gathering the information and using Geekbench browser tests. I currently have the values for Zen 3 and Apple Firestore. Just looking for Intel info
 browser.geekbench.com
browser.geekbench.com
When finished I will post it here.
Geekbench 5 CPU Search - Geekbench
browser.geekbench.com
When finished I will post it here.
nicalandia
Diamond Member
Okay, I was able to finish a Quick Research on each core area(mm2 on the die) and performance using Geekbench I will try to find info for power usage.

 www.anandtech.com
www.anandtech.com
So these scores are for Performance per Area(square millimeter) per core without L3$ just L2
A single Apple Firestorm core is about 9 mm2 in size, they get about 1740 points on GB5, that puts them at 193 points per area.
A single Amd Zen3 core is about 4.3 mm2 in size, they get about 1700 points on GB5, that puts them at 395 points per area.
A single Intel Golden Cove core is 7 mm2 and they get abut 2000 points on GB5, that gets them about 285 points per area.
Edit.
Also as I pointed out earlier, this is 1C/1T which puts the X86 CPUs on a disadvantage when compared to a 1C/1T Apple Firestorm. so add about 30% performance per core since the HT/SMT is already built on the Core
CPU Benchmarks and Hierarchy 2025: CPU Rankings
We've run thousands of CPU benchmarks on all new and older Intel and AMD CPUs and ranked them.
So these scores are for Performance per Area(square millimeter) per core without L3$ just L2
A single Apple Firestorm core is about 9 mm2 in size, they get about 1740 points on GB5, that puts them at 193 points per area.
A single Amd Zen3 core is about 4.3 mm2 in size, they get about 1700 points on GB5, that puts them at 395 points per area.
A single Intel Golden Cove core is 7 mm2 and they get abut 2000 points on GB5, that gets them about 285 points per area.
Edit.
Also as I pointed out earlier, this is 1C/1T which puts the X86 CPUs on a disadvantage when compared to a 1C/1T Apple Firestorm. so add about 30% performance per core since the HT/SMT is already built on the Core
Last edited:
Are the x86 core values corrected for fab node geometry differences to the N5 that A14 is produced on?Okay, I was able to finish a Quick Research on each core area(mm2 on the die) and performance using Geekbench I will try to find info for power usage.
CPU Benchmarks and Hierarchy 2025: CPU Rankings
We've run thousands of CPU benchmarks on all new and older Intel and AMD CPUs and ranked them.
So these scores are for Performance per Area(square millimeter)
A single Apple Firestorm core is about 9 mm2 in size, they get about 1740 points on GB5, that puts them at 193 points per area.
A single Amd Zen3 core is about 6.5 mm2 in size, they get about 1500 points on GB5, that puts them at 230 points per area.
A single Intel Golden Cove core is 10.5 mm2 and they get abut 190 points on GB5, that gets them about 100 points per area.
Edit.
Also as I pointed out earlier, this is 1C/1T which puts the X86 CPUs on a disadvantage when compared to a 1C/1T Apple Firestorm. so add about 30% performance per core since the HT/SMT is already built on the Core
FlameTail
Diamond Member
Okay, I was able to finish a Quick Research on each core area(mm2 on the die) and performance using Geekbench I will try to find info for power usage.
CPU Benchmarks and Hierarchy 2025: CPU Rankings
We've run thousands of CPU benchmarks on all new and older Intel and AMD CPUs and ranked them.
So these scores are for Performance per Area(square millimeter)
A single Apple Firestorm core is about 9 mm2 in size, they get about 1740 points on GB5, that puts them at 193 points per area.
A single Amd Zen3 core is about 6.5 mm2 in size, they get about 1500 points on GB5, that puts them at 230 points per area.
A single Intel Golden Cove core is 10.5 mm2 and they get abut 190 points on GB5, that gets them about 100 points per area.
Edit.
Also as I pointed out earlier, this is 1C/1T which puts the X86 CPUs on a disadvantage when compared to a 1C/1T Apple Firestorm. so add about 30% performance per core since the HT/SMT is already built on the Core
Thank you very much for this. Really appreciate the effort !
This was the type of calculation that i was exactly looking for !
It would be good if you or someone else can also do the same calculation for other benchmarks like Cinebench and SPEC.
That would help us to arrive at meaningful conclusion.
Interesting, the Zen 3 has high performance per area than the other two, as per your calculation.
Last edited:
FlameTail
Diamond Member
Performance in what ? Cinebench r23 or Cpumark99 ? Packman ?
What architecture of Zen3 ? APU or 5xx0 series or maybe Epyc ? What Alder lake SKU ? At what binning, cherry picked silicon or over how big average sample size ?
Area including what ? Cores alone ? Uncore? with or without L1, L2 and L3 ? Memory controller ? IO die for Zen3 ? Maybe you mean mm2 socket ?
How do you measure power ? In idle or in what workload ? avx512 or SSE ? Including gpu (apu) ? Powerdraw shown in hwinfo or measured from the wall ? What bios settings, MCE enabled ?
Your question is like me asking what the color purple taste like.. it have no meaning.
Honestly, i dont know much about how cores work in the insides ( registers, avx512 and other really advanced stuff ), so please forgive me.
Since you know better than me, i suggest you do the calculation making your own decisions/assumptions ( based on which things you think are correct - is cache also considered part of the core ? I cant really say- you choose ) and mention them in the final answer.
nicalandia
Diamond Member
NoAre the x86 core values corrected for fab node geometry differences to the N5 that A14 is produced on?
nicalandia
Diamond Member
I omitted Area without L3 because the M1 lacks L3$...But its a big Fat L2, without any Cache or with full Cache would have been better. Amd Full 8 Mb $ per core is as big as the Core/L2 sizeThank you very much for this. Really appreciate the effort !
This was the type of calculation that i was exactly looking for !
It would be good if you or someone else can also do the same calculation for other benchmarks like Cinebench and SPEC.
That would help us to arrive at meaningful conclusion.
Interesting, the Zen 3 has high performance per area than the other two, as per your calculation.
nicalandia
Diamond Member
Shall we do a performancex MTr/mm²?Are the x86 core values corrected for fab node geometry differences to the N5 that A14 is produced on?
FlameTail
Diamond Member
I omitted Area without L3 because the M1 lacks L3$...But its a big Fat L2, without any Cache or with full Cache would have been better. Amd Full 8 Mb $ per core is as big as the Core/L2 size
Ah the huge L2 cache must be the reason why the Firestorm core has such a large silicon footprint, despite being on the smaller 5nm node.
nicalandia
Diamond Member
I am currently gathering all of the data to present it with and without L2 cache$ on Firestorm(A14), Zen3(Cezanne) and Golden Cove/Willow CoveAh the huge L2 cache must be the reason why the Firestorm core has such a large silicon footprint, despite being on the smaller 5nm node.
I am currently gathering all of the data to present it with and without L2 cache$ on Firestorm(A14), Zen3(Cezanne) and Golden Cove/Willow Cove
IMO with and without LLC (L3/SLC) would be more interesting.
It's a hard comparison to make because having an SLC instead of a traditional L2 is obviously a design choice that isn't made in a vacuum. Apple had much larger L1 caches (the I-cache for each Firestorm core is 192 KB) compared to the x86 CPUs from Intel and AMD.
If you have a traditional L2 cache you're probably comfortable making a trade for a faster, but smaller L1 cache. If Apple's next stop is SLC then they obviously need a larger L1 and the lower clock speeds they operate at mean that the size doesn't create as much of a penalty in terms of delay cycles.
Really you should consider the chip and memory system as a whole. No one benchmark or workload will give a perfect answer as to efficiency because some tests will favor that larger L1 cache and others won't care about it at all.
If you have a traditional L2 cache you're probably comfortable making a trade for a faster, but smaller L1 cache. If Apple's next stop is SLC then they obviously need a larger L1 and the lower clock speeds they operate at mean that the size doesn't create as much of a penalty in terms of delay cycles.
Really you should consider the chip and memory system as a whole. No one benchmark or workload will give a perfect answer as to efficiency because some tests will favor that larger L1 cache and others won't care about it at all.
It's a hard comparison to make because having an SLC instead of a traditional L2 is obviously a design choice that isn't made in a vacuum. Apple had much larger L1 caches (the I-cache for each Firestorm core is 192 KB) compared to the x86 CPUs from Intel and AMD.
If you have a traditional L2 cache you're probably comfortable making a trade for a faster, but smaller L1 cache. If Apple's next stop is SLC then they obviously need a larger L1 and the lower clock speeds they operate at mean that the size doesn't create as much of a penalty in terms of delay cycles.
Really you should consider the chip and memory system as a whole. No one benchmark or workload will give a perfect answer as to efficiency because some tests will favor that larger L1 cache and others won't care about it at all.
Apple chips have traditional L2 caches for each CPU group (1 L2 cache shared by the P cores and 1 shared by the E cores). They then have another cache level, "system level cache" (SLC), that is shared by all the CPUs and the GPU and probably other blocks. This is similar to Alderlake with the difference being that the P cores have individual instead of shared caches. I can't imagine the SLC on Alderlake and M1 aren't by and large open for the CPUs though when running CPU only benchmarks.
Maybe I'd misread an article because for some reason I'd thought that Apple's L2 was basically just an SLC cache. Either that or it was some site with missing data. I just pulled up an AT article and it does talk about L2 cache.
Really though if you're running a controlled benchmark comparing an L3 and SLC would be reasonable. There's probably not enough GPU activity to seriously impact the performance of the SLC.
Really though if you're running a controlled benchmark comparing an L3 and SLC would be reasonable. There's probably not enough GPU activity to seriously impact the performance of the SLC.
Perf/watt is not always clear cut. Let's take an example: An AVX-512 workload with fallbacks for other architectures. Which wins out? An Intel chip, of course. Intel is the only company (thus far, AMD coming next year) to implement AVX-512. Ergo, Intel has the fastest chip. The days of measuring pure integer performance are long gone. ARM has equivalents to some instruction sets, but the native implementation of those instruction sets is up to either the compiler or the app maker, depending on the instruction set.
That would be great just for reference sake, but I've no idea how you would dial that back into your current comparison values in the post I replied to.Shall we do a performancex MTr/mm²?
My math skills stink for lack of use I'm afraid 😅.
nicalandia
Diamond Member
Okay, I found a better source for Apple Firestorm Core + L2, the one at Techpowerup I found earlier had a rough diagram that made the L2 larger than expected and the 9.1 was for the two cores and the big L2$, here is a better diagram that I was able to confirm(Pixel/mm2 wise), also there is detailed chart per block.
Here is the diagram.
Apple Firestorm Core on the A14 SOC size: 3.76 mm2 per Core with L2$

Source: https://semiwiki.com/semiconductor-...sis-terrifying-implications-for-the-industry/
AMD Zen3 Core on Cezanne SOC size: 6.4 mm2 with L3$ and 4.2 mm2 with L2$ only

Source: https://videocardz.com/newz/amd-ryzen-5-5600g-cezanne-apu-die-has-been-pictured-up-close
Intel Golden Cove core on Alder Lake SOC size: 7.04 mm2 with L2$ and 9.4 with L3$, the Ring bus is Huge compared to Zen 3

Some benchmarks(CBR23 and Geekbench 5) and Final numbers.


Apple Firestorm core area: 3.76 mm2 per core with L2$ only(no system cache)
CBR23: 408.5 points per area,
GB5: 463.3 points per area
11 Watts peak power CBR23 ST: 139.6 points per watt
Intel Golden Cove core area: 7.04 mm2 per core with L2$ only
CBR23: 254.5 points per area
GB5: 229.7 points per area
45 Watts peak power CBR23 ST: 39 points per watt
AMD Zen3 Core area: 4.2 mm2 per core with L2$ only
CBR23: 362 points per area
GB5: 384.2 points per area
45 Watts peak power CBR23 ST: 33.8 points per watt
Here is the diagram.
Apple Firestorm Core on the A14 SOC size: 3.76 mm2 per Core with L2$
Source: https://semiwiki.com/semiconductor-...sis-terrifying-implications-for-the-industry/
AMD Zen3 Core on Cezanne SOC size: 6.4 mm2 with L3$ and 4.2 mm2 with L2$ only
Source: https://videocardz.com/newz/amd-ryzen-5-5600g-cezanne-apu-die-has-been-pictured-up-close
Intel Golden Cove core on Alder Lake SOC size: 7.04 mm2 with L2$ and 9.4 with L3$, the Ring bus is Huge compared to Zen 3
Some benchmarks(CBR23 and Geekbench 5) and Final numbers.
Apple Firestorm core area: 3.76 mm2 per core with L2$ only(no system cache)
CBR23: 408.5 points per area,
GB5: 463.3 points per area
11 Watts peak power CBR23 ST: 139.6 points per watt
Intel Golden Cove core area: 7.04 mm2 per core with L2$ only
CBR23: 254.5 points per area
GB5: 229.7 points per area
45 Watts peak power CBR23 ST: 39 points per watt
AMD Zen3 Core area: 4.2 mm2 per core with L2$ only
CBR23: 362 points per area
GB5: 384.2 points per area
45 Watts peak power CBR23 ST: 33.8 points per watt
Last edited:
nicalandia
Diamond Member
Okay basing this chart I built off this article.
https://wccftech.com/why-apple-m1-single-core-comparisons-are-fundamentally-flawed-with-benchmarks/
True Performance of a single x86 core with SMT

Intel Golden Cove core 2330 points / 7.04 mm2 : 330 per mm2
AMD Zen3 core 1997 points / 4.2 mm2 : 475 points per mm2
Apple Firestorm core 1521 points / 3.76 mm2 : 404 points per mm2
Intel Gracemont core 1295 points / 2.2 mm2 : 588 points per mms
https://wccftech.com/why-apple-m1-single-core-comparisons-are-fundamentally-flawed-with-benchmarks/
True Performance of a single x86 core with SMT
Intel Golden Cove core 2330 points / 7.04 mm2 : 330 per mm2
AMD Zen3 core 1997 points / 4.2 mm2 : 475 points per mm2
Apple Firestorm core 1521 points / 3.76 mm2 : 404 points per mm2
Intel Gracemont core 1295 points / 2.2 mm2 : 588 points per mms
Last edited:
Okay basing this chart I built off this article.
https://wccftech.com/why-apple-m1-single-core-comparisons-are-fundamentally-flawed-with-benchmarks/
True Performance of x86 cores with SMT
View attachment 54788
Intel Golden Cove core 2330 points / 7.04 mm2 : 330 per mm2
AMD Zen3 core 1997 points / 4.2 mm2 : 475 points per mm2
Apple Firestorm core 1521 points / 3.76 mm2 : 404 points per mm2
What an incredibly stupid take.
The whole point of a single core test is to test what happens when you run a single thread of code. Tells me the author of that wccftech article is butthurt about how well M1 compares to x86 and wants to find a way to put some artificial distance between them.
Rename it single thread test then if you want, but running two threads and calling it a "single core" test is down there with correcting spelling like replying "*you're" to someone when you can't come up with any actual defense against their position.
nicalandia
Diamond Member
I agree...but in this case its valid since the OP requested info on performance/die area per core and thats exactly this because SMT is built on the coreWhat an incredibly stupid take.
The whole point of a single core test is to test what happens when you run a single thread of code. Tells me the author of that wccftech article is butthurt about how well M1 compares to x86 and wants to find a way to put some artificial distance between them.
Rename it single thread test then if you want, but running two threads and calling it a "single core" test is down there with correcting spelling like replying "*you're" to someone when you can't come up with any actual defense against their position.
FlameTail
Diamond Member
I agree...but in this case its valid since the OP requested info on performance/die area per core and thats exactly this because SMT is built on the core
Yes, I agree.
Since we are talking about about single-core performance and not single-threaded performance, the no. of threads don't really matter.
But if a core performs at it's best when it has HT /2 threads per core. So I'll take 1C/2T
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 25K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 24K
-

-
