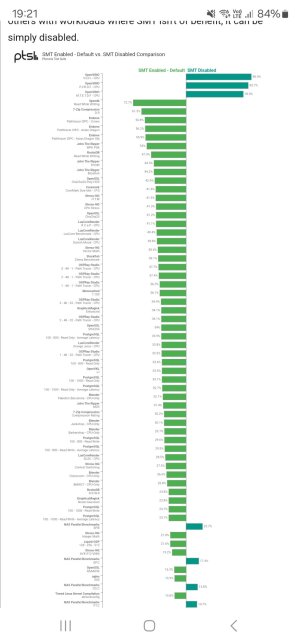
It's been a while since we've had a dedicated SMT thread where we can debate the pros and cons and ask ourselves and each other whether Intel and AMD should ditch the technology or keep it......and also whether ARM CPUs should adopt it.
Having owned many SMT capable CPUs, I can definitely say one thing. The introduction of efficiency cores has definitely lessened the impact of that technology. I ran a test in another thread where I transcoded a 4K60 FPS video to x265, and logged the difference between having HT on and off. HT on yielded 8.37% performance increase if I recall correctly over not having HT. Power usage was slightly more with HT as well as temps, but it wasn't a huge difference.
At first I was a bit surprised, given the fact that on my previously owned SMT capable CPUs (ranging from Nehalem all the way to Broadwell-E), the HT advantage was much greater in encoding workloads. It was always double digits, as encoding typically has both high TLP and ILP. Raptor Lake was the first CPU I've ever tested in encoding that had a single digit performance increase for HT enabled. But obviously, those previous CPUs that I owned didn't have 16 efficiency cores either.
So the efficiency cores are definitely sucking up a lot of TLP in those workloads. Which begs the question, is SMT now worth keeping or should Intel (and AMD should they ever implement efficiency cores) ditch SMT completely in favor of these efficiency cores?
Honestly, I am leaning strongly towards having SMT, but not because I believe it necessarily increases multithreading performance significantly. I've been doing some research, and one interesting tidbit I came across was from a recently released Chips and Cheese article convinced me of the virtues of SMT:
Golden Cove’s Lopsided Vector Register File – Chips and Cheese
I definitely agree with the author's assessment here and it supports the performance characteristics I saw in my encoding test with HT on and off. HT/SMT is no longer just about increasing multithreaded performance. It's also about increasing single threaded performance. Case in point, my 13900KF saw a 8.37% gain in performance just by switching on HT. Does this mean that there was some TLP left that the 16 efficiency cores didn't tap into? Perhaps......but I doubt it. The task manager showed all 32 threads on my system at 100% capacity, as 4K transcoding is very compute intensive. After reading the Chips and Cheese article, what I think happened now is that HT enabled the performance cores to increase throughput and efficiency and better utilize the P cores. That's why the gain was much smaller than in the past, because with the efficiency cores now eating up a lot of the TLP, SMT is now primarily about increasing overall throughput in the core irrespective of whether it's a single threaded or multithreaded application.
This is because of the lopsided vector register file structure. Apparently, this makes it easier for the cores to dynamically adapt to high TLP or low TLP workloads without negatively impacting performance. It seems it's kind of like having your cake and eating it too. Now if I had turned off the efficiency cores, the HT impact would have been much larger I suspect due to more TLP being available so the second thread would have been allowed more resources.
The author states that this approach is not only more performant, but more die space efficient as well. So with that said, I declare the SMT debate to be over with, in favor of SMT
OK I'm sure there will be plenty of dissent. But this to me is an indication that SMT is not what it used to be. It has evolved and is now much more adaptive to the workload.
This merits it being kept around in my opinion.
Having owned many SMT capable CPUs, I can definitely say one thing. The introduction of efficiency cores has definitely lessened the impact of that technology. I ran a test in another thread where I transcoded a 4K60 FPS video to x265, and logged the difference between having HT on and off. HT on yielded 8.37% performance increase if I recall correctly over not having HT. Power usage was slightly more with HT as well as temps, but it wasn't a huge difference.
At first I was a bit surprised, given the fact that on my previously owned SMT capable CPUs (ranging from Nehalem all the way to Broadwell-E), the HT advantage was much greater in encoding workloads. It was always double digits, as encoding typically has both high TLP and ILP. Raptor Lake was the first CPU I've ever tested in encoding that had a single digit performance increase for HT enabled. But obviously, those previous CPUs that I owned didn't have 16 efficiency cores either.
So the efficiency cores are definitely sucking up a lot of TLP in those workloads. Which begs the question, is SMT now worth keeping or should Intel (and AMD should they ever implement efficiency cores) ditch SMT completely in favor of these efficiency cores?
Honestly, I am leaning strongly towards having SMT, but not because I believe it necessarily increases multithreading performance significantly. I've been doing some research, and one interesting tidbit I came across was from a recently released Chips and Cheese article convinced me of the virtues of SMT:
Golden Cove’s Lopsided Vector Register File – Chips and Cheese
Modern high performance CPUs from both Intel and AMD use SMT, where a core can run multiple threads to make more efficient use of various core resources. Ironically, a large motivation behind SMT is likely the need to improve single threaded performance. Doing so involves targeting higher performance per clock with wider and deeper cores. But scaling width and reordering capacity runs into increasingly diminishing returns. SMT is a way to counter those diminishing returns by giving each thread fewer resources that it can make better use of. SMT also introduces complexity because resources may have to be distributed between multiple active threads.
I definitely agree with the author's assessment here and it supports the performance characteristics I saw in my encoding test with HT on and off. HT/SMT is no longer just about increasing multithreaded performance. It's also about increasing single threaded performance. Case in point, my 13900KF saw a 8.37% gain in performance just by switching on HT. Does this mean that there was some TLP left that the 16 efficiency cores didn't tap into? Perhaps......but I doubt it. The task manager showed all 32 threads on my system at 100% capacity, as 4K transcoding is very compute intensive. After reading the Chips and Cheese article, what I think happened now is that HT enabled the performance cores to increase throughput and efficiency and better utilize the P cores. That's why the gain was much smaller than in the past, because with the efficiency cores now eating up a lot of the TLP, SMT is now primarily about increasing overall throughput in the core irrespective of whether it's a single threaded or multithreaded application.
This is because of the lopsided vector register file structure. Apparently, this makes it easier for the cores to dynamically adapt to high TLP or low TLP workloads without negatively impacting performance. It seems it's kind of like having your cake and eating it too. Now if I had turned off the efficiency cores, the HT impact would have been much larger I suspect due to more TLP being available so the second thread would have been allowed more resources.
The author states that this approach is not only more performant, but more die space efficient as well. So with that said, I declare the SMT debate to be over with, in favor of SMT
OK I'm sure there will be plenty of dissent. But this to me is an indication that SMT is not what it used to be. It has evolved and is now much more adaptive to the workload.
This merits it being kept around in my opinion.
Last edited: