looncraz
Senior member
- Sep 12, 2011
- 722
- 1,651
- 136
Now you are shifting the goalposts, or maybe AMD itself was being duplicitous in making the calculation.
No, I showed another way this time around, my first example was the entire board power. Originally, AMD only mentioned 2.8x performance in relation to Polaris. Only later did this get stuck on the RX 480 product in a few slides - which could be a communication issue, or it could be due to the use of a method similar to mine, or it could be because they compared using TDP rather than actual consumption.
My only real interest is in what the process achieved for Polaris 10 - and 2.8x is within the region of what is observed (lower power, higher clocks). I don't think AMD was being deceitful, I think RX 480 power consumption is 15W too high - which may be entirely due to the VRM usage not being included in their board logic (the VRM uses about 16W under full load, AFAICT).
As others have mentioned, it is expected for the RX 470 to use less power yet not give up much performance. Some rumors are as high as 95% of the 4GB card's performance, but only 90% of the power draw.
But as the majority of people assume the meaning to be, 2.8x performance per watt increase means 2.8 faster FPS for the same power usage by the entire card.
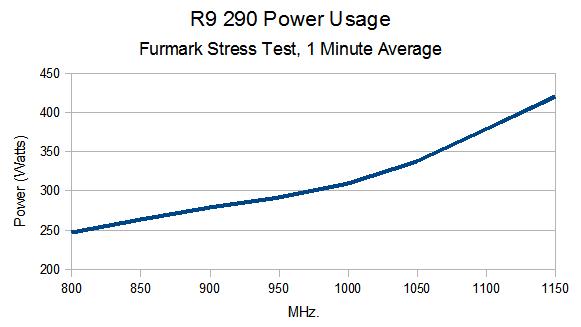
According to Anandtech, the stock R9 290 uses 88W more in Crysis 3 (so 165W vs 253W), but the RX 480 performs 3.8% better. That is only 1.6x improvement by that method - which is no less valid of a method, no doubt, but it measures a different type of efficiency (FPS/W, rather than W/CU/HZ - which is the concern for process-derived improvements).
But, that little "up to" gives so much room to wiggle that we have to look at other FPS/W or Perf/W scenarios... because only one is needed to be true by this method. The closest I've found is TessMark, at 2.35x.
However, if we use each card's TDP, things get interesting. Crysis 3 shows a 1.9x improvement, and Tessmark shows a 2.81x improvement.
Really can't help but to wonder if this is what someone did at AMD. Kind of makes sense... some management type said: 150W TDP, 275W TDP, Tessmark result is 53% faster, that gives... 2.81x performance/w improvement. Sweet, run with it!
OR, they could compare it with the R9 380... and use TDP comparisons... numbers don't change much for most games, interestingly, though the best result is in Lux Mark at 2.44x, and Tessmark becomes just 1.82x.
In fact introducing other variables such as clockspeed, process, and ram power usage, you are doing exactly what you said is not part of the "scientific method": examining several variables at once.
No, I'm removing variables by fixing values in place and comparing like to like.
The FPS/W metric does not do this except at the macro level (comparing one product directly with another). It is immensely useful for the end consumer, no doubt, but much less so for someone interested in the technical improvements of the process (which is my focus).
I'm not saying AMD should have rolled around saying 2.8x performance/watt improvement. I firmly believe under-hyping products is something AMD needs to learn has value. nVidia said almost nothing about the GTX 1060 until it was about to be released. And it will sell like hotcakes nonetheless. I am just saying that the accuracy of the 2.8x claim completely depends on the little footnote AMD has for their claims.
Now if the 470 meets that target, or if they were using some other way to calculate "performance per watt" they technically may have met the criteria, but in a what I consider a deceptive manner.
If AMD believed they had met their goal from internal testing and only realized they failed it after the next few thousand GPUs were sent into the wild and tested by dozens of people, then they weren't being deceptive, they simply missed the target they thought they had achieved.
I even think the 2.8x figure was first leaked before AMD had a prototype die, but I don't have time to check on that, ATM.
EDIT:
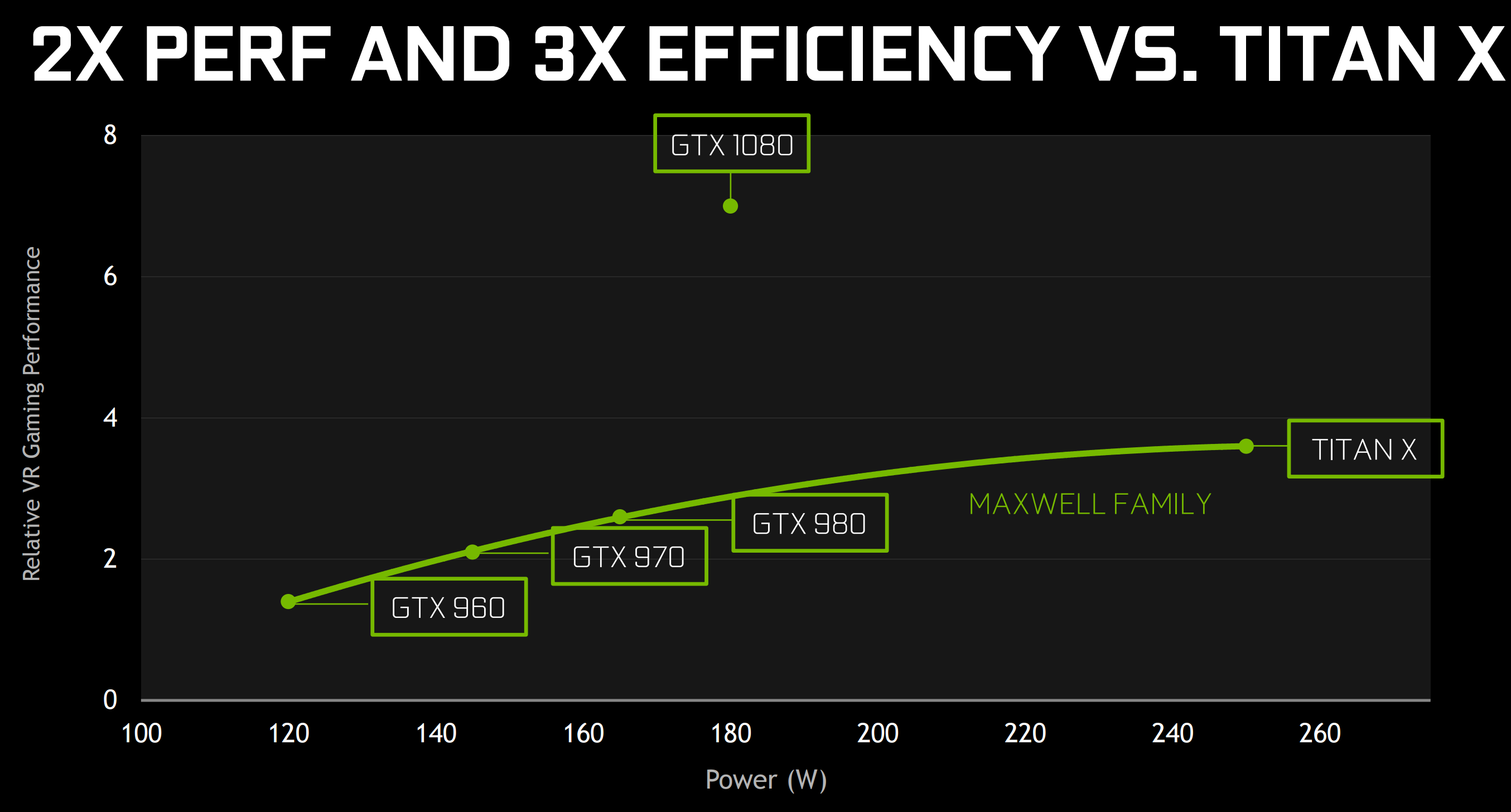
And it's not like nVidia doesn't do the same... or worse:
Last edited:
 .
.