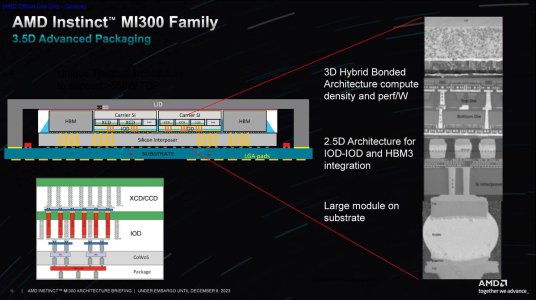
Instead of mocking, you can post a counter argument.
If the information was readily available, there would be no need to ask AI to deduce it. Since the info is not readily available, you can choose to be completely in the dark or you can ask one of the AI tools, to find tidbits of information and then try to connect them.
Because it is the best of the ones I have available.
Google generally generates garbage
CoPilot is very fast, but superficial (gave 4x to 15x range but mixed-up the units)
Grok can do deep search and deep reasoning
It seems like you don't have experience in how the LLMs work. They can find credible tidbits and then they can try to find corroborating information.
Google came up with NADA:
"While precise cost per mm² figures are difficult to obtain due to the proprietary nature of these technologies and varying product specifics, the cost difference between the two is significant."
You can read significant as you wish
CoPilot
Relative Cost per mm² (Estimates)
- CoWoS: Typically ranges from $2,000 to $3,000 per mm².
- InFO: Generally falls between $200 to $500 per mm²
I think this may be per wafer. But pretty good and informative for extremely fast turnaround.
Grok was the only one to be able to find one single reference there is on internet and found out it is relevant:
"One historical account notes that early CoWoS pricing was around 7 cents per mm², which customers deemed too expensive for adoption; they indicated willingness to use it only at around 1 cent per mm². This feedback directly led TSMC to develop InFO as a more cost-effective alternative, achieving broader adoption (e.g., in Apple processors) and generating substantial revenue."
It links to this article:
台積電 CoWoS 技術由於人工智能的推動而變得火紅。然而,十多年前該技術卻沒有客户,只有賽靈思 (Xilinx) 願意採用。當時每個月只需生產 50 片,數量相當有限。台積電投資了大量資源發展這項技術,但卻沒有收益。最終,他們採取了降低成本的另一種先進封裝技術 InFO。InFO 成為蘋果等智能手機芯片客户採用的先進封裝技術,也是台積電的主要技術之一。

longportapp.com
"Shang-Yi Chiang shared that he had promoted the CoWoS technology to customers everywhere, but no one was willing to use it. Later, during a dinner with a vice president of a customer, the reason for not adopting CoWoS was casually mentioned as the high price. If selling at 7 cents per square millimeter was too expensive, they would only consider using it if it was sold at 1 cent per square millimeter. This realization prompted him to immediately instruct the R&D manager to develop a cost-reducing technology, which turned out to be another advanced packaging technology called InFO."
Grok gave 67 links to web pages on which it based further analysis. And based on those, it gave final estimate as a range of 3x-7x cost differential between CoWoS and InFO.
Downside is that the current deployment level of Grok 4 I have access to is quite slow. Which is why I use CoPilot for simple quick searches.
I invite you to do better than this.


.png")