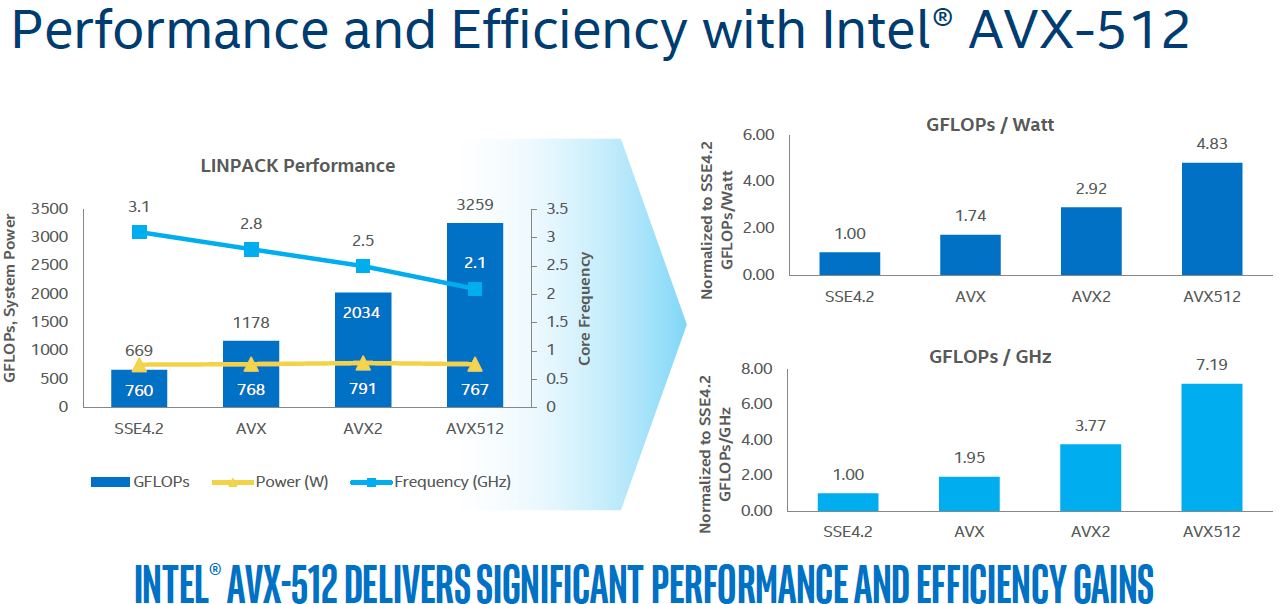
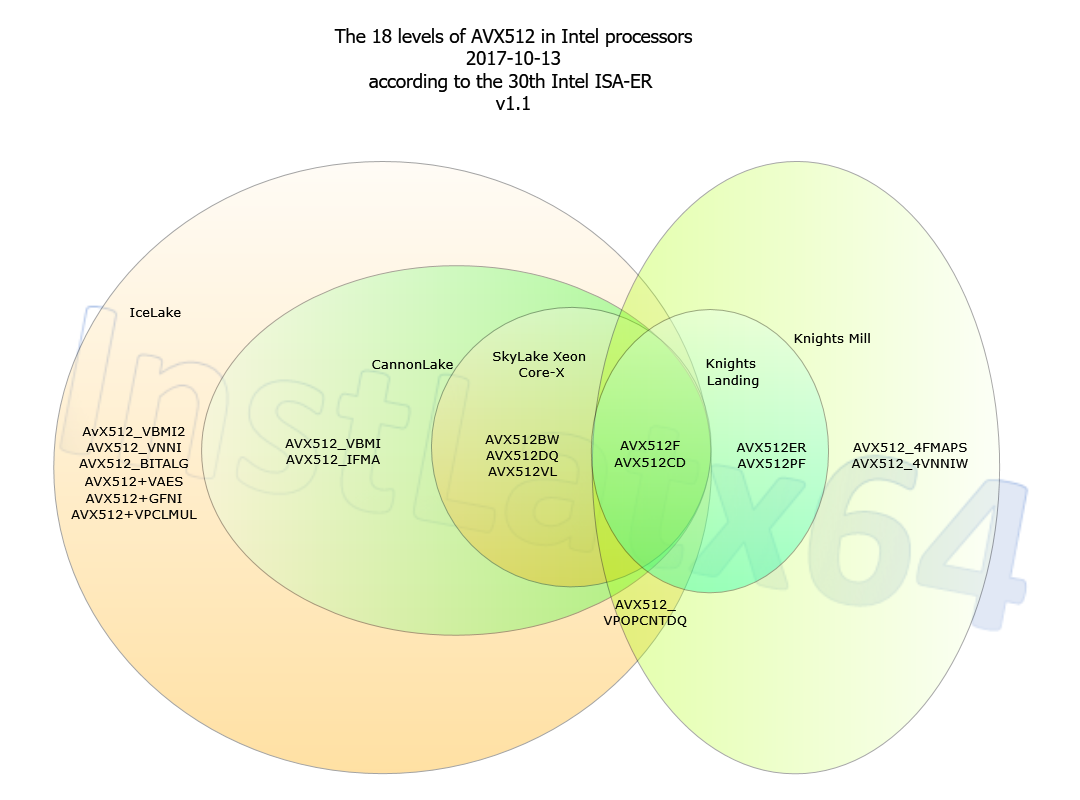
Source?
Isn't that what PAO is supposed to be?
Process = Cannonlake
Architecture = Icelake
Optimization = Tigerlake
So now that Cannonlake is all but dead; and they can't do 10 nm server products without EMIB because of the awful yield... sooo it kind of makes sense to just skip Icelake Server too and just go to Tigerlake since it was built with 10++ in mind and presumably EMIB too.
Ice Lake Refresh refers to a refresh of the platform to include an Ice Lake-based processor family.
I dunno... seems to fit perfectly to go straight to Tigerlake since they need EMIB.