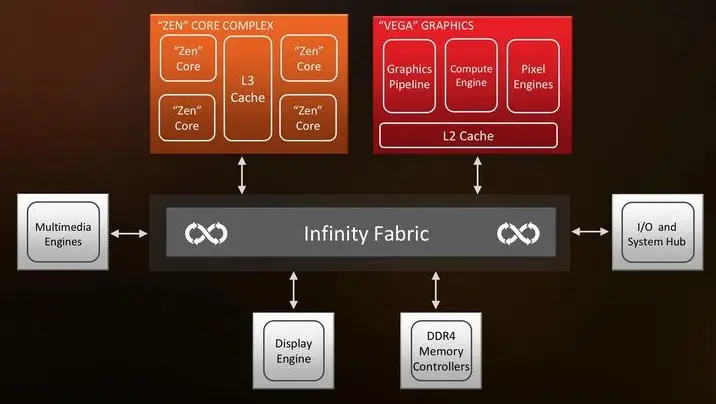
With respect to memory bandwidth contention as compared to the most recent Bristol Ridge chips, please remember that Ryzen G has an actual L3 cache (4MB to be precise). This will make a significant difference in the behavior of the memory controller. The flip side will be that, in the full fat Ryzen 5Gs with 4 cores and 8 threads, there can be 8 active threads all clamoring for memory bandwidth at the same time, which will definitely hit the L3 cache hard.
All that said, there will still be a major bottleneck with respect to memory bandwidth. I firmly believe that we will see a significant performance uplift over Bristol Ridge given the increased efficiency of the core internals, especially when considering thermal and power budgets, but, the lack of a major improvement in memory bandwidth will still put an absolute limit on higher resolution performance that will be unacceptable to many. While I realize that AMD has a still very limited R&D budget, I think that it would have been worth their while to consider cutting the CUs down to 8, expanding the die size by 20%, and including a roughly 128MB L4 cache to further help with memory bandwidth contention issues. We've already seen that this approach can make a noticeable improvement in iGPU performance from Intel's IRIS Pro products, and it could have done the same here. I also realize that it would have increased the cost of the chips by a non-trivial amount and would likely make them all at least 20% more expensive. I would take a 2200G that cost $125 over $99 and a 2400g that was a bit over $200 if it offered performance that was solidly past 1030/RX550 performance levels and nearing RX560 levels.