
- Aug 14, 2000
- 22,709
- 3,007
- 126
This thread was started in mid 2021 and is being retired/locked. As the OP is no longer active, or updating and maintaining it.
Mod DAPUNISHER
8GB
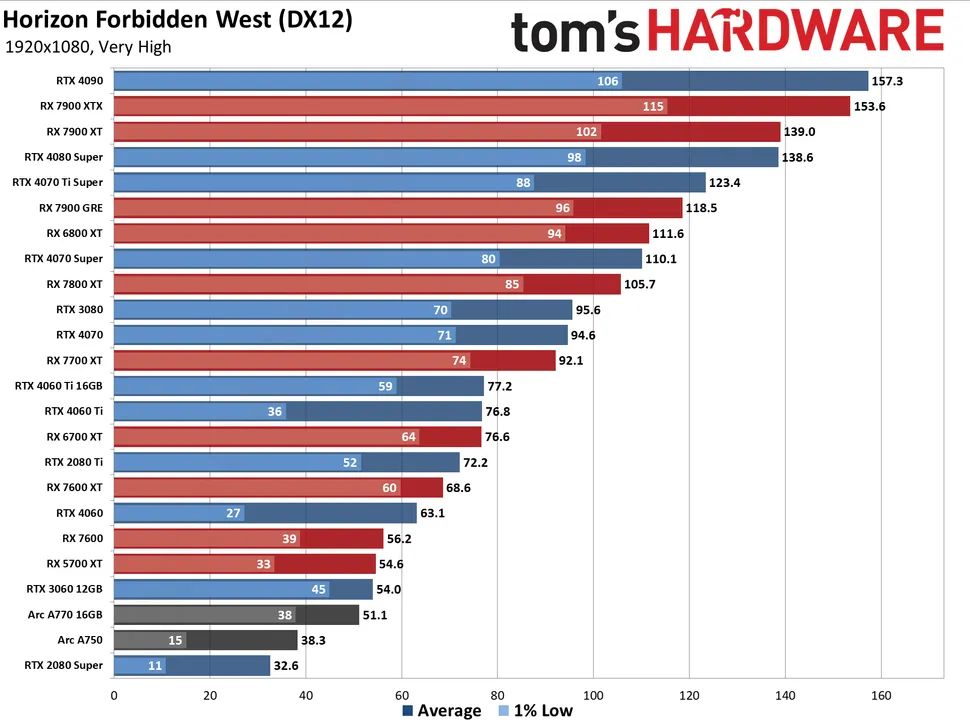 Resident Evil Village 3060TI/3070 tanks at 4K and is slower than the 3060/6700XT when ray tracing:
Resident Evil Village 3060TI/3070 tanks at 4K and is slower than the 3060/6700XT when ray tracing:
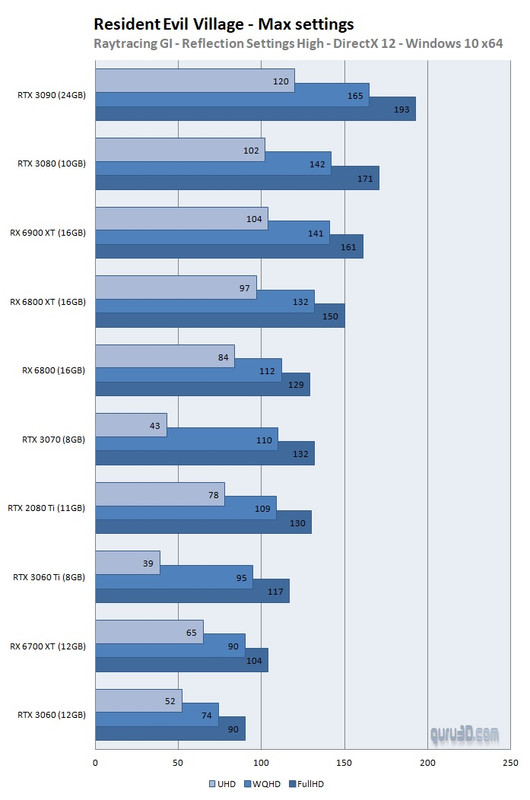 Company Of Heroes 3060 has a higher minimum than the 3070TI:
Company Of Heroes 3060 has a higher minimum than the 3070TI:
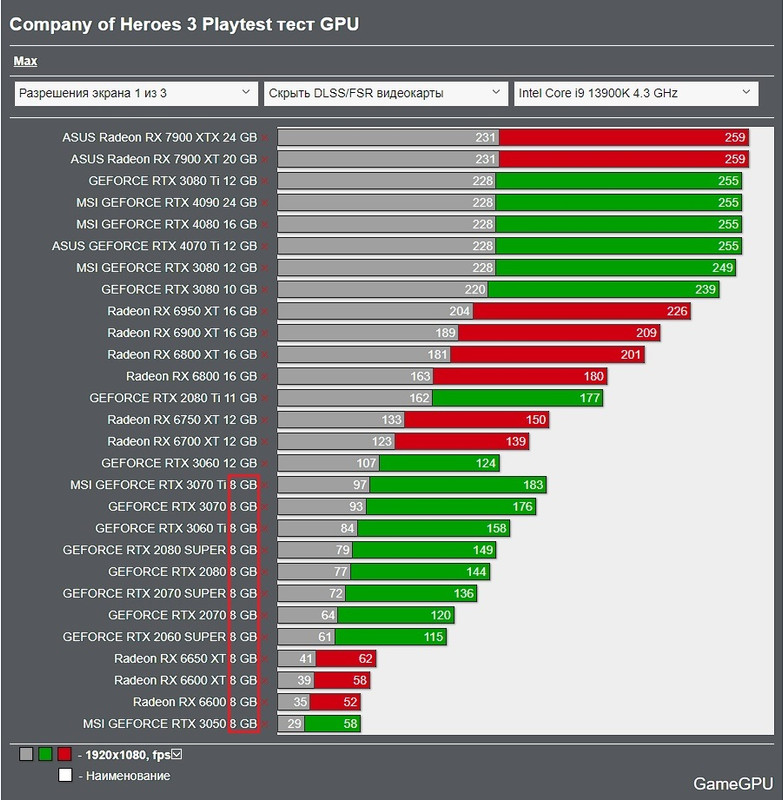
10GB / 12GB
Reasons why still shipping 8GB since 2014 isn't NV's fault.
Mod DAPUNISHER
8GB
- Dying Light 2, Battlefield 2042, Avatar Frontiers of Pandora, Call of Duty Modern Warfare 3, Starfield, Forza Horizon 5, Horizon Forbidden West, Alan Wake 2, The Last of Us, Tekken 8, FC 24, Detroit Become Human, Death Stranding, Alone in The Dark, Overwatch 2
3060 12GB higher 1% low than 4060 8GB https://www.youtube.com/watch?v=gIfz57wmywg - Cyberpunk 2077, Diablo 4, Hogwarts Legacy, Horizon Zero Dawn, Microsoft Flight Sim 2020, Witcher 3, Watch Dogs Legion skip to 4K + DLSS for each game https://www.youtube.com/watch?v=tPiaWWd0xGc
- Ratchet & Clank, Plague Tale Requiem, Last Of Us, Jedi Survivor, Far Cry 6, Hogwarts Legacy, Forza Horizon 5, Cyberpunk 2077 https://www.youtube.com/watch?v=Wr3MckDxMfE&pp=ygUTMTZnYiB2cyA4Z2IgNDA2MCB0aQ==
- Far Cry 6, Godfall, Hogwarts Legacy, Forza Horizon 5, Forspoken, Doom Eternal, Watchdogs Legion https://youtu.be/fJc--C01P90?t=268
- Last Of Us, Resident Evil 4, Callisto Protocol, Plague Tale Requiem, Halo Infinite, Forspoken https://youtu.be/2_Y3E631ro8?t=429
- Last Of Us, Hogwarts Legacy, Resident Evil 4, Forspoken, Plague Tale Requiem, Callisto Protocol https://youtu.be/Rh7kFgHe21k?t=288
- Hogwarts Legacy, Last Of Us, Spider Man Remastered, Doom Eternal, Forza Horizon 5 https://youtu.be/R943CbDTq_s?t=1473
- Horizon Forbidden West 4060 has issues @ 1080p + DLSS unless you switch off frame generation and reduce settings to high https://youtu.be/3AyKvI23VGw?t=233
- Horizon Forbidden West 3070 requires reducing textures 2 notches https://youtu.be/xTwEGy6HHKo?t=351
- Deathloop https://youtu.be/lu_XHyO-6zY?t=918
- Ghost Recon Breakpoint https://youtu.be/iUGppQVpXzU?t=529
- Resident Evil 2 https://youtu.be/Aa-gsgRjMII?t=796
- Talos Principle 2 https://youtu.be/K6FATQAuEwI?t=337
- Spider Man Remastered https://youtu.be/vRVR_plVSlc?t=1060
- Witcher 3 https://youtu.be/vRVR_plVSlc?t=1240
10GB / 12GB
- Plague Tale Requiem 3080 10GB tanks if you enable ray tracing, would be fast enough if it had more VRAM because if you stop moving, the framerate stabilizes to >60FPS https://youtu.be/7zjrMww3fAc?t=496
- Hogwarts Legacy 4K + RT, 4060Ti 16GB is faster than 4070 12GB https://youtu.be/X-h_R488Mq8?t=191
Reasons why still shipping 8GB since 2014 isn't NV's fault.
- It's the player's fault.
- It's the reviewer's fault.
- It's the developer's fault.
- It's AMD's fault.
- It's the game's fault.
- It's the driver's fault.
- It's a system configuration issue.
- Wrong settings were tested.
- Wrong area was tested.
- Wrong games were tested.
- 4K is irrelevant.
- Texture quality is irrelevant as long as it matches a console's.
- Detail levels are irrelevant as long as they match a console's.
- There's no reason a game should use more than 8GB, because a random forum user said so.
- It's completely acceptable for the more expensive 3070/3070TI/3080 to turn down settings while the cheaper 3060/6700XT has no issue.
- It's an anomaly.
- It's a console port.
- It's a conspiracy against NV.
- 8GB cards aren't meant for 4K / 1440p / 1080p / 720p gaming.
- It's completely acceptable to disable ray tracing on NV while AMD has no issue.
- Polls, hardware market share, and game title count are evidence 8GB is enough, but are totally ignored when they don't suit the ray tracing agenda.
Last edited by a moderator:



