- Mar 3, 2017
- 1,774
- 6,757
- 136

Tbh, wouldn't be surprising if Strix uses N4P and server use N3.

4 years is basically the very beginning of a project, before the requirements have solidified, all the way to shipping. Regardless, the beauty of AMD's implementation is that they've developed something that they can happily sell with or without hybrid bonding, with minimal overhead. So they could plumb in the interface, but if the tech wasn't ready, no big deal.Lead times on design are usually around four years and v-cache isn't just something you can bolt on to an existing chip.
They've claimed that their hybrid bonding tech will be ready sometime this year, but how true that is or when we'll actually see a product with it remains to be seen.I'd imagine that Intel has something in the works that uses this sort of technology by now, or have started figuring out how to do something similar with their own future processes.
It doesn't appear to be using N4.
How come you think it is obsolete? Just because c != D ? Well, marketing names may change over time.This slide was an obsolete rumor from May 2021. These guys just thought Zen4D refered to Zen4 Dense but it turned out to be wrong with Zen4C(Cloud) official confirmation.
'Advanced node' with Strix Point on newest slide could mean AMD haven't decide which node should be used.
You just answer your own questionHow come you think it is obsolete? Just because c != D ? Well, marketing names may change over time.
")
Considering AMD is using D as part of their v-cache products (e.g., 5800X3D), it's unlikely that they'd use it for a separate product designation.
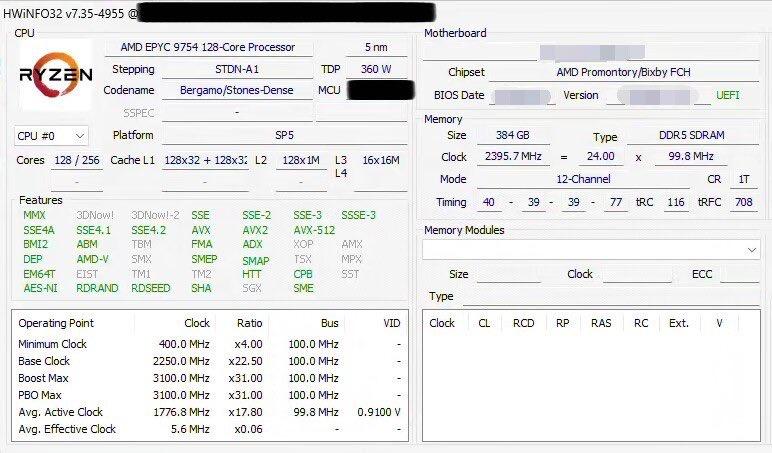
These are arbitrary names assigned to the CPUID by the author of that software.Long time lurker here, but in one of YuuKi_AnS’s tweets it’s shown that Bergamo is also called Stones-Dense.
The other way around: It is entirely possible that they named Bergamo Zen4D internally back in 2021 and before, but switched to Zen4c lafter on.Considering AMD is using D as part of their v-cache products (e.g., 5800X3D), it's unlikely that they'd use it for a separate product designation.
I am having a hard time understanding your first two points - somehow the words do not add up for me to become "reasoning".You just answer your own question
1. We cannot use codename like Zen4D(Dense) which is not existed. Especially the rumored one's meaning is very different from the official one Zen4C(Cloud)
2. StrixPoint process node is still uncertain with 'Advanced Node' statement.
It is strange for me that AMD use a new full node (3nm, 5nm, 7nm etc) on APUs ahead of non-APUs. If Zen5 non-APUs is on N4, it would be a surprise that StrixPoint on N3.
It is an old rumor. I don't know how the Zen4D rumor being filled 20 months ago but we can sure the old slide is obsolete or wrong cuz some products on the slide would never exist. Like Warhol.
Should I be worried that a tweet from YuuKi_AnS is "potentially sensitive content"?
In this case, thankfully just CPU-Z and similar screenshots.Well if it is like a lot of other leakers out there there it may be hentai or pubescent Asian girls.
I suspect Zen5 will use some of the stacking and connectivity tech used for RDNA3 and MI300, so it is kind of relevant. The things you have labeled as Zen4 cores look more like infinity cache, or maybe L2 cache, or something like that. I have seen the small chips between the HBM3 referred to as structural silicon (semiaccurate, I think). The chiplet you have labeled as "adaptive chiplet" looks exactly like a Zen 4 chiplet with 8 cores. The thing you have labeled "AI chiplet" may be partially FPGA. FPGAs have large arrays, so it could look like cache. It could also just be all AI hardware. That would have large, regular, arrays of things in addition to possible caches. It would be easier to tell if I knew the die size of HBM3. I didn't find it in a quick search and I don't have time to search more today. I thought HBM2 was around 100 mm2. The rendering may be completely inaccurate, but if the "AI chiplets" are actually cpu cores, then where do the 24 cores come from? There are essentially 3 GPUs (2 chiplets each), so having 3x8-cores would make sense. I don't know where the other 8 cores would be hiding unless there is something weird like 2 low power cores in each base die.Thanks. I did speculate that MI300 contains 6 APU chiplets, but there are other possibilities, of course. And, someone intriguingly hinted to me that my speculation is wrong. Anyway, here is my mock-up based on the slide rendering and the actual chip photo:

Page 467 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 467 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.forums.anandtech.com
Now, continue the "Zen 5" speculation!
Well if it is like a lot of other leakers out there there it may be hentai or pubescent Asian girls.
Has there been some feature or instruction that was present in Zen 4 QS samples but didn't get released in final silicon, based on your review of these patches?Not sure if this is widely known, Zen 5 is family 26/1Ah. Kernel patches are landing now.
Will never know such things, because in traditional AMD style they release manuals and patches after product launch, save for the vague unintelligble patches.Has there been some feature or instruction that was present in Zen 4 QS samples but didn't get released in final silicon, based on your review of these patches?

 videocardz.com
videocardz.com
I suspect Zen5 will use some of the stacking and connectivity tech used for RDNA3 and MI300, so it is kind of relevant. The things you have labeled as Zen4 cores look more like infinity cache, or maybe L2 cache, or something like that. I have seen the small chips between the HBM3 referred to as structural silicon (semiaccurate, I think). The chiplet you have labeled as "adaptive chiplet" looks exactly like a Zen 4 chiplet with 8 cores. The thing you have labeled "AI chiplet" may be partially FPGA. FPGAs have large arrays, so it could look like cache. It could also just be all AI hardware. That would have large, regular, arrays of things in addition to possible caches. It would be easier to tell if I knew the die size of HBM3. I didn't find it in a quick search and I don't have time to search more today. I thought HBM2 was around 100 mm2. The rendering may be completely inaccurate, but if the "AI chiplets" are actually cpu cores, then where do the 24 cores come from? There are essentially 3 GPUs (2 chiplets each), so having 3x8-cores would make sense. I don't know where the other 8 cores would be hiding unless there is something weird like 2 low power cores in each base die.
It's actually 153.6 GB/s.SK hynix now sampling LPDDR5T (Turbo) memory, up to 9.6 Gbps - VideoCardz.com
SK hynix Develops World’s Fastest Mobile DRAM LPDDR5T Data transmission speed increases by 13%, with improved energy-efficiency Application of HKMG process to DRAM maximizes product performance “SK hynix to spur technology development, aiming to be industry’s game changer” Seoul, January 25...
Any 128 bit memory controller will get 156 GB/s from this.
To put into perspective, Radeon RX 6500 XT from 18 Gbps GDDR6 memory on 64 bit bus gets 144 GB/s.
It's actually 153.6 GB/s.
This is nice and all but the price will be ridiculously high and only a few models will use them at best.
But at least there is this option.
Its 64 bit, as well.It's actually 153.6 GB/s.
This is nice and all but the price will be ridiculously high and only a few models will use them at best.
But at least there is this option.
.The new CAMM modules may include these as a possibility as they are supposed to support LPDDR too.It's actually 153.6 GB/s.
This is nice and all but the price will be ridiculously high and only a few models will use them at best.
But at least there is this option.
It was just developed, It's only sample production for customers.It will be expensive now, it must be seen if it will stay expensive when these APUs will arrive.
It doesn't have a wider bus per package.Its 64 bit, as well.
LPDDR5X(standard) is 16 bit.
51200/6400=8*8 => 64-bit packageAt 6,400 megabits per second (Mb/s), the new LPDDR5 is about 16 percent faster than the 12Gb LPDDR5 (5,500Mb/s) found in most of today’s flagship mobile devices. When made into a 16GB package, the LPDDR5 can transfer about 10 5GB-sized full-HD movies, or 51.2GB of data, in one second.