
- Oct 22, 2004
- 822
- 1,467
- 136
I've had my eye on SYCL for some time now. I don't think it is widely recognised that this is going to be the standard for heterogeneous programming models going forward (eventually to be merged into the ISO C++ standard, it seems). If you read any discussion on programming, tech and investor forums about Nvidia vs AMD in the AI space, you rarely see SYCL mentioned at all. The discussion is usually about CUDA vs ROCm/HIP — about how poor and difficult to install and use the latter is, and how good, easy and dominant the former is.
However, in the the supercomputer space they are looking for a vendor neutral programming model for AI and HPC. SYCL is just that:
"SYCL (pronounced “sickle”) is an open standard programming model that enables heterogeneous programming based on standard ISO C++. Heterogeneous programming is the basis for today’s growing HPC, AI, and machine learning applications. SYCL has been gaining momentum as supercomputing communities look for a nonproprietary programming model. Maintained under the Khronos Group and initially released in 2014, SYCL is a royalty-free, cross-platform open standard abstraction layer that enables code for heterogeneous processors to be written with the host and kernel code for an application contained in the same source file. SYCL has been closely aligned to OpenCL, but over time has evolved into its own completely distinct programming model. The latest revision SYCL 2020 can decouple completely from OpenCL and therefore eases deployment support on multiple backends."
hpcwire.com
So, in my view, CUDA is not long for this world — in the supercomputer space, at least. I think the transition to SYCL is going to trickle down, probably pretty rapidly. I fear a lot of Nvidia's valuation (currently over 4 times AMD and 2 times Intel in market capitalisation) is based on the idea that Nvidia is going to be "the Wintel of AI". I don't think so. I think AI is soon going to be wide open. On the other hand, I hope that Nvidia's valuation is just a prelude to the amount of investment dollars that are going to be poured into the high performance compute space, as AI takes off and the demand for ever more processing performance keeps growing.
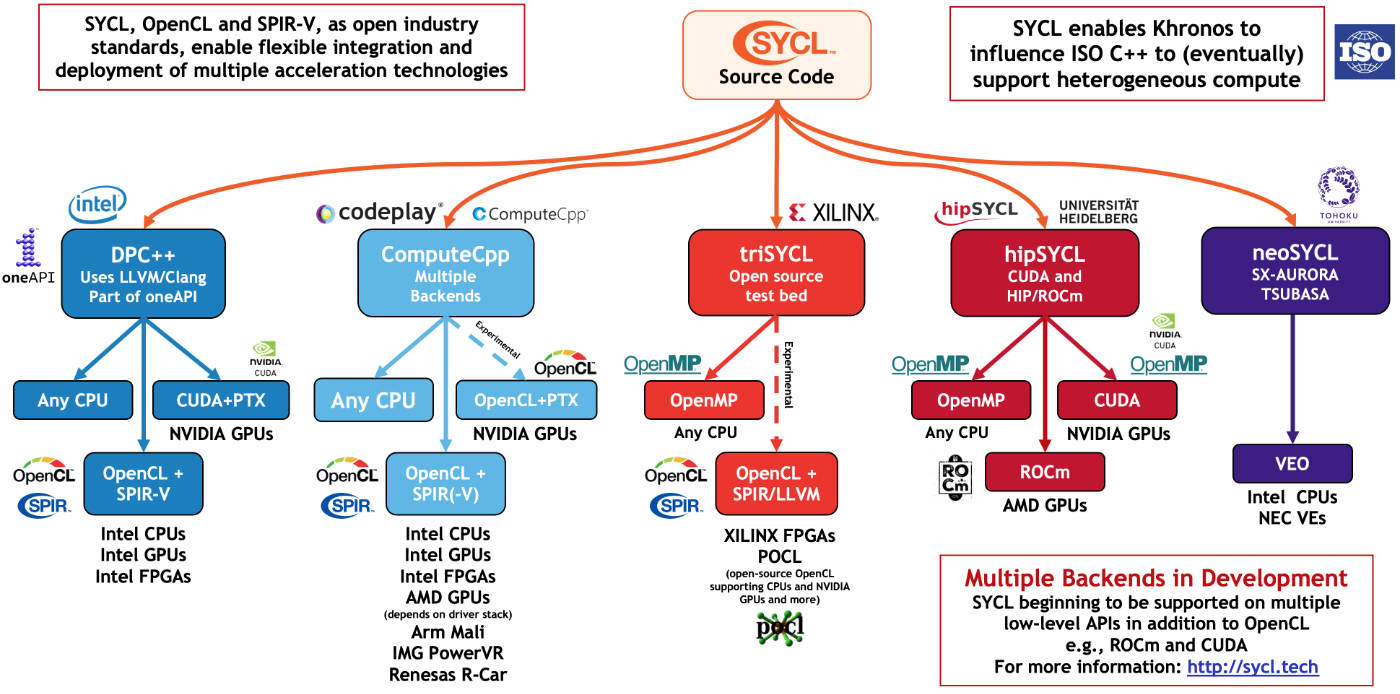
PS. To their credit, Intel chose the right path with oneAPI. Their open Data Parallel C++ compiler (DPC++) is becoming the de-facto open compiler for SYCL, it seems. There is also hipSYCL from Heidelberg university, providing a layered solution on top of CUDA and HIP/ROCm toolchains. Heidelberg is also working with Intel on compatibility with the oneAPI/DPC++ toolchain (link). It is also cool that Xilinx and AMD have been involved with SYCL from the beginning through the experimental triSYCL project. With the merger, I expect great things on the software side.
SYCL.tech - Find out the latest SYCL news, videos, learning materials and projects.
However, in the the supercomputer space they are looking for a vendor neutral programming model for AI and HPC. SYCL is just that:
"SYCL (pronounced “sickle”) is an open standard programming model that enables heterogeneous programming based on standard ISO C++. Heterogeneous programming is the basis for today’s growing HPC, AI, and machine learning applications. SYCL has been gaining momentum as supercomputing communities look for a nonproprietary programming model. Maintained under the Khronos Group and initially released in 2014, SYCL is a royalty-free, cross-platform open standard abstraction layer that enables code for heterogeneous processors to be written with the host and kernel code for an application contained in the same source file. SYCL has been closely aligned to OpenCL, but over time has evolved into its own completely distinct programming model. The latest revision SYCL 2020 can decouple completely from OpenCL and therefore eases deployment support on multiple backends."
hpcwire.com
So, in my view, CUDA is not long for this world — in the supercomputer space, at least. I think the transition to SYCL is going to trickle down, probably pretty rapidly. I fear a lot of Nvidia's valuation (currently over 4 times AMD and 2 times Intel in market capitalisation) is based on the idea that Nvidia is going to be "the Wintel of AI". I don't think so. I think AI is soon going to be wide open. On the other hand, I hope that Nvidia's valuation is just a prelude to the amount of investment dollars that are going to be poured into the high performance compute space, as AI takes off and the demand for ever more processing performance keeps growing.
PS. To their credit, Intel chose the right path with oneAPI. Their open Data Parallel C++ compiler (DPC++) is becoming the de-facto open compiler for SYCL, it seems. There is also hipSYCL from Heidelberg university, providing a layered solution on top of CUDA and HIP/ROCm toolchains. Heidelberg is also working with Intel on compatibility with the oneAPI/DPC++ toolchain (link). It is also cool that Xilinx and AMD have been involved with SYCL from the beginning through the experimental triSYCL project. With the merger, I expect great things on the software side.
SYCL.tech - Find out the latest SYCL news, videos, learning materials and projects.
Please do not post the same thread in multiple sub-forums here.
I will leave this thread open for now.
Iron Woode
Super Moderator
I will leave this thread open for now.
Iron Woode
Super Moderator
Last edited:



