Yep. The computing techniques to advance IPC should be independent of ISA. Outside of decode for X86 to translate complex instructions to simpler ones, there really is no significant difference, and this cost has a smaller % hit as complexity increases.Yes clearly x86-64 still has plenty of juice left in the glass, despite what ARM fans might say. It's going to be awesome watching an invigorated AMD (and Intel as well if they sort out their manufacturing woes) duke it out with ARM designs in the next couple of years in HPC, servers etcetera...

Speculation: Ryzen 4000 series/Zen 3
Page 210 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.

Yep. The computing techniques to advance IPC should be independent of ISA. Outside of decode for X86 to translate complex instructions to simpler ones, there really is no significant difference, and this cost has a smaller % hit as complexity increases.
Yeah, after thinking about it some more, I think a more accurate way to frame the upcoming battle between x86-64 and ARM-64 will be high speed designs like Zen 3 and Comet Lake vs the more brainiac designs like the Apple A series.
amrnuke
Golden Member
- Apr 24, 2019
- 1,181
- 1,772
- 136
I think to keep the title of a "braniac" design, Apple's A series will need to prove some innovations beyond leveraging TSMC's work and increasing clock speeds, running power up by double-digit percentages more than they gain in performance, etc.Yeah, after thinking about it some more, I think a more accurate way to frame the upcoming battle between x86-64 and ARM-64 will be high speed designs like Zen 3 and Comet Lake vs the more brainiac designs like the Apple A series.
Zen3, if IPC really does go up as much as it seems, would pass Zen2's chiplet design in my mind for the title of the most "braniac" work of the last 2-3 years, at least when it comes to everything I've seen from the CPU world.
I think to keep the title of a "braniac" design, Apple's A series will need to prove some innovations beyond leveraging TSMC's work and increasing clock speeds, running power up by double-digit percentages more than they gain in performance, etc.
From reading the realworldtech forums, it seems that one of the biggest reasons why Apple is able to extract such high performance from their CPUs is due to how "tightly optimized" the core is; whatever that means. I'm guessing tight optimization in this sense means the cores are geared towards burst and single threaded performance?
Zen3, if IPC really does go up as much as it seems, would pass Zen2's chiplet design in my mind for the title of the most "braniac" work of the last 2-3 years, at least when it comes to everything I've seen from the CPU world.
Whenever I've seen the word "brainiac" used on this and other forums, it's referred to high IPC wider designs. But I suppose it's a relative concept. I mean, compared to the P4, Conroe would be considered a brainiac CPU, but next to the A13 or something, it wouldn't be.
amrnuke
Golden Member
- Apr 24, 2019
- 1,181
- 1,772
- 136
From reading the realworldtech forums, it seems that one of the biggest reasons why Apple is able to extract such high performance from their CPUs is due to how "tightly optimized" the core is; whatever that means. I'm guessing tight optimization in this sense means the cores are geared towards burst and single threaded performance?
I think core optimization occurred a while ago though. There have been only minimal optimizations since then (single digit percentage per generation), taking into account clock speed increase and process changes with TSMC.
Well, just making a design wide isn't really all that brainiac. Making it work for the use-case and doing so with tact instead of brute-force, to me, is brainiac. For instance, Apple making the A13 20% faster than A12 is great, but it also uses almost 30% more power. That's not brainiac, that's just throwing watts and transistors at the problem. Same issue with Nvidia's GPUs. Same issue with Zen -> Zen+. If all you're doing is leveraging someone else's process improvement (GloFo / TSMC) or throwing more transistors at the problem, it's hard to really call that brainiac or ingenuity or whatever. It's like you want to get ahead in a war, you just enlist more men. Sure, I guess, but that's not really brainiac.Whenever I've seen the word "brainiac" used on this and other forums, it's referred to high IPC wider designs. But I suppose it's a relative concept. I mean, compared to the P4, Conroe would be considered a brainiac CPU, but next to the A13 or something, it wouldn't be.
Last edited:
And how do these not apply to Zen 3, in terms of real estate, process maturity, and clocks?Well, just making a design wide isn't really all that brainiac. Making it work for the use-case and doing so with tact instead of brute-force, to me, is brainiac. For instance, Apple making the A13 20% faster than A12 is great, but it also uses almost 30% more power. That's not brainiac, that's just throwing watts and transistors at the problem. Same issue with Nvidia's GPUs. Same issue with Zen -> Zen+. If all you're doing is leveraging someone else's process improvement (GloFo / TSMC) or throwing more transistors at the problem, it's hard to really call that brainiac or ingenuity or whatever. It's like you want to get ahead in a war, you just enlist more men. Sure, I guess, but that's not really brainiac.
DrMrLordX
Lifer
- Apr 27, 2000
- 23,131
- 13,224
- 136
And how do these not apply to Zen 3, in terms of real estate, process maturity, and clocks?
Zen3 achieves higher performance within the same power envelope as Zen2; to whit, the 5900X has the same 142W package power limit as a 3900X.
I repeat:Zen3 achieves higher performance within the same power envelope as Zen2; to whit, the 5900X has the same 142W package power limit as a 3900X.
How about real estate, process maturity, and clocks?
DrMrLordX
Lifer
- Apr 27, 2000
- 23,131
- 13,224
- 136
I repeat:
You can repeat all you like. The initial point was that Apple was driving up transistor count and power usage generation-over-generation, whereas AMD is not. They're upping transistor count I think, though I haven't seen chiplet size comparisons between Matisse and Vermeer so I can't be sure. Regardless, power isn't going up.
Clocks are apparently lower in MT despite Vermeer enjoying increased MT throughput anyway.
As far as "process maturity" goes, it's the same process as used in the XT chips, which had no appreciable improvement in voltage/clockspeed curve over first-gen Matisse.
LightningZ71
Platinum Member
- Mar 10, 2017
- 2,649
- 3,333
- 136
When you exclude the significant increases in cache size for the progressing Zen generations, the transistor count growth is relatively modest up to Zen2. Do we have final, official transistor counts and L3 sizes for the 5000 series processors yet?
amrnuke
Golden Member
- Apr 24, 2019
- 1,181
- 1,772
- 136
Real Estate: I assume you're talking about transistor counts. Of course, you know as well as I do that we don't know until we get die size comparisons, transistor density estimates, and so on. Ostensibly, since N7 is mature, they can increase die size or transistors per core because cost/yield won't be as much of an issue. We won't know for sure until we get the chips. Since it's still on AM4 and there is limited real estate, and AMD's presentation shows no substantial difference in chiplet size, I assume the transistor count isn't much different.And how do these not apply to Zen 3, in terms of real estate, process maturity, and clocks?
Process Maturity: Process is the same as Zen2. We saw that between Zen2 and the Zen2 XT versions, there is no substantial gain in IPC if we consider single-core GB5 score per GHz to be reflective of IPC (it seems reasonably close). Hence, for Zen3, process maturity will play little role in IPC, but does play a role in overall performance gain due to better binning and higher clocks enabled.
Clocks: The point is that AMD are achieving substantial gains even when accounting for clock speed, as I mentioned.
Apple have been pumping up transistor counts, clock speeds, and leveraging TSMC's process advancements to produce almost all of their performance gains. For Apple, then, while they have made uarch/core design changes, most of their gains are now coming from just ramping up transistor counts, clock speeds, and performance gains from TSMC node advances.
As we all know Intel have dumped their focus into enabling more power to feed more clocks and hence performance, rather than refining uarch/core design.
For AMD, we know they are not leveraging a new TSMC node, and we know therefore that transistor counts may go up, but can't go up by much since the chiplet appears the same size, and we know that even after adjusting for clocks, there are huge performance gains both raw and IPC, in the same power envelope. This reflects a far different approach than Apple and Intel are taking.
(For those to whom this sounds repetitive, I apologize, it's because I already went over these things in my post on page 209.)
Apple have been pumping up transistor counts, clock speeds, and leveraging TSMC's process advancements to produce almost all of their performance gains. For Apple, then, while they have made uarch/core design changes, most of their gains are now coming from just ramping up transistor counts, clock speeds, and performance gains from TSMC node advances.
That's one of the things that used to frustrate me when debating with ARM fans. They would often ignore the process node advantage that Apple has been enjoying courtesy of TSMC, while simultaneously ignoring the fact that Intel had been stuck on 14nm+++++ for God knows how long and are just starting to make hay from their 10nm process and use that as justification to put x86-64 in a poor light. If Intel had flawlessly executed their node advancement, they would be on 7nm by now and there probably wouldn't even be a debate.
But now that AMD can enjoy the same benefits as Apple in terms of node advancement, we are seeing a great rejuvenation in x86-64 performance. If AMD continues with these gains, the performance gap with ARM will continue to widen and they (ARM) will not be able to close it because despite what some have said, IPC isn't the "be all end all" of CPU performance. Frequency is very important to CPU performance as well. In fact, high frequency is one of the biggest reasons why Intel has been so dominant in performance over the years despite their aging microarchitecture.
High frequency plus high IPC is a brutal combination, and that's what AMD is targeting. The two can no longer be thought of as mutually exclusive.
Last edited:
LightningZ71
Platinum Member
- Mar 10, 2017
- 2,649
- 3,333
- 136
I wouldn't call TSMC's process tech world beating for all of history up until the release of N7, and, even then, it is essentially a trade-off between N7 and Intel 14nm. Intel's process tech clocks higher than TSMC's at present. We have yet to see an N5 product that clocks higher than the 10900K. Where N5 and the denser libraries for N7 lead is in transistor density, and, that's not a huge lead for N7. N7 is a bit better than Intel's 14nm on power when operating in its more favorable frequency ranges, but drinks power once it's outside of it in a similar fashion to Intel 14. Intel's 10nm process was broken in its first iteration, made functional for Ice Lake, and actually made to be a notable improvement over 14nm with the 10sf node, and there are still apparent trade offs.
Where people seem to not have a clear view of the real competition between ARM and x86-64 is in understanding that almost everything that's been produced up until recently, for ARM, has been targeted either at mobile, or at low cost, high durability products. You don't see any ARM processors that aren't specifically targeted at low volume solutions that get much higher clocked than 3.5Ghz. They have low power budgets and low thermal budgets, so they can't leave the nice areas of the power/frequency curve of their respective processes. This issue has been noted in multiple reviews of high end cell phones. So, while ARM chips may have a higher IPC than x86 parts, most of that is the result of deliberate design decisions for the individual cores used. They optimized for throughput at lower frequencies. It's not wrong or right, its a trade-off.
Where people seem to not have a clear view of the real competition between ARM and x86-64 is in understanding that almost everything that's been produced up until recently, for ARM, has been targeted either at mobile, or at low cost, high durability products. You don't see any ARM processors that aren't specifically targeted at low volume solutions that get much higher clocked than 3.5Ghz. They have low power budgets and low thermal budgets, so they can't leave the nice areas of the power/frequency curve of their respective processes. This issue has been noted in multiple reviews of high end cell phones. So, while ARM chips may have a higher IPC than x86 parts, most of that is the result of deliberate design decisions for the individual cores used. They optimized for throughput at lower frequencies. It's not wrong or right, its a trade-off.
moinmoin
Diamond Member
- Jun 1, 2017
- 5,248
- 8,463
- 136
That's one of the things that used to frustrate me when debating with ARM fans. They would often ignore the process node advantage that Apple has been enjoying courtesy of TSMC, while simultaneously ignoring the fact that Intel had been stuck on 14nm+++++ for God knows how long and are just starting to make hay from their 10nm process and use that as justification to put x86-64 in a poor light. If Intel had flawlessly executed their node advancement, they would be on 7nm by now and there probably wouldn't even be a debate.
But now that AMD can enjoy the same benefits as Apple in terms of node advancement, we are seeing a great rejuvenation in x86-64 performance. If AMD continues with these gains, the performance gap with ARM will continue to widen and they (ARM) will not be able to close it because despite what some have said, IPC isn't the "be all end all" of CPU performance. Frequency is very important to CPU performance as well. In fact, high frequency is one of the biggest reasons why Intel has been so dominant in performance over the years despite their aging microarchitecture.
High frequency plus high IPC is a brutal combination, and that's what AMD is targeting. The two can no longer be thought of as mutually exclusive.
In AMD's arguable most important market, datacenters, this is by far not as clear cut. There the combination of high frequency plus high IPC is not as applicable, instead it's pure IPC since lower frequency translates to higher effciency. Apple in this regard is no direct competitor, but a good target to strive for for all chip designers.
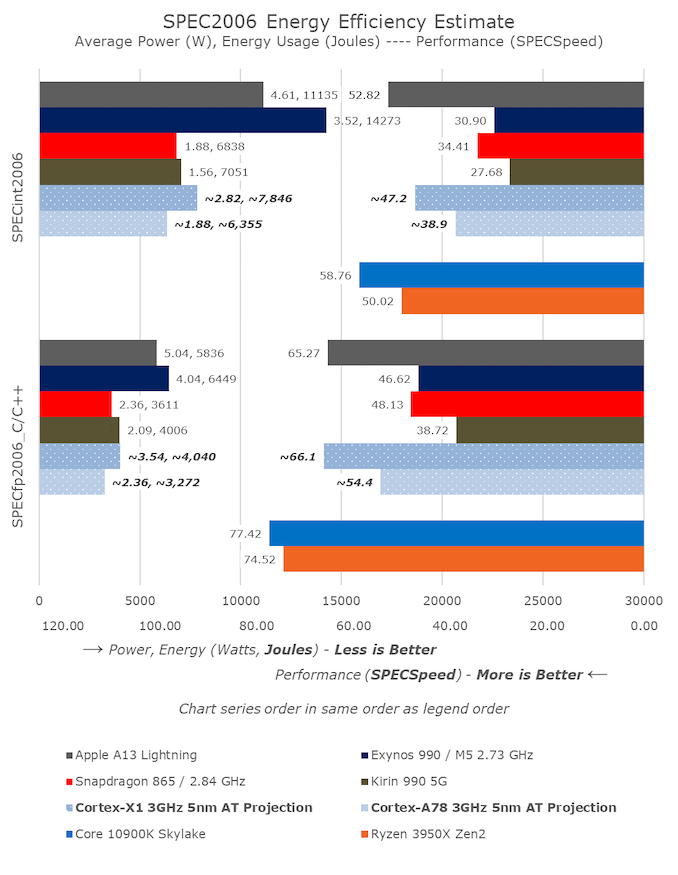
@amrnuke gladly did already a SPEC/GHz list for us a couple pages back:
Let's assume that SPECint2006 1T scales along with GB5 single-core. Known GB5/SPECint2006 results are in bold, projected results in italics.
A14:.......GB5 1586, SPECint2006 63.13 @ 3.0 GHz, SPEC/GHz = 21.04
A13:.......GB5 1327, SPECint2006 52.82 @ 2.66 GHz, SPEC/GHz = 19.86
5900X:...GB5 1605, SPECint2006 62.72 @ 4.95 GHz, SPEC/GHz = 12.67
1065G7:.GB5 ?????, SPECint2006 47.40 @ 3.9 GHz, SPEC/GHz = 12.15
3900X:...GB5 1280, SPECint2006 50.02 @ 4.6 GHz, SPEC/GHz = 10.87
9900K:...GB5 1334, SPECint2006 54.28 @ 5.0 GHz, SPEC/GHz = 10.86
10900K:.GB5 1412, SPECint2006 57.45 @ 5.3 GHz, SPEC/GHz = 10.84
* I scaled by architecture - A14 inferred SPEC score = (A13 SPEC score * A14 GB5 score) / A13 GB5 score. The 9900K/10900K also grouped, and 3900X/5900X grouped in a similar way.
A higher SPEC/GHz will be a crucial advantage in datacenters since the higher the value, the more processing power one can pack in a given power envelope, the higher one can scale the amount of cores. ARM with Neoverse and chip designers like Nuvia are in progress of cactching up with Apple. To stay ahead in datacenters AMD needs to be mindful of the impact many cores ARM servers can have in datacenters, ideally offering a competitive or even superior SPEC/GHz (or more generally perf/W) itself. There the potential gap to fill is still big enough to ensure sufficient work for AMD in the foreseeable time.
-----
As AMD shows on TSMC nodes high frequency is also not an issue of the TSMC node but one of the chip design. Which means any ARM chip designer should be able to push for similarly high frequencies as AMD chips on the same node if they ever choose to go down that path.Where people seem to not have a clear view of the real competition between ARM and x86-64 is in understanding that almost everything that's been produced up until recently, for ARM, has been targeted either at mobile, or at low cost, high durability products. You don't see any ARM processors that aren't specifically targeted at low volume solutions that get much higher clocked than 3.5Ghz. They have low power budgets and low thermal budgets, so they can't leave the nice areas of the power/frequency curve of their respective processes. This issue has been noted in multiple reviews of high end cell phones. So, while ARM chips may have a higher IPC than x86 parts, most of that is the result of deliberate design decisions for the individual cores used. They optimized for throughput at lower frequencies. It's not wrong or right, its a trade-off.
Gideon
Platinum Member
- Nov 27, 2007
- 2,042
- 5,090
- 136
Exactly. It's not so much about SPEC/GHz but perf/W, as each core will have at most 1.5 - 3W to use when a 64+ core system is running @ full-steam. The problem is that the frequency/voltage curve really takes off at somewhere above 3-3.5 Ghz (on pretty much all latest process nodes). So in the end they end up being more-or-less the same thing. The sweet-spot for that on most architectures is in the same ballpark (between 2.5 - 3.5 ghz). Here is zen 2 for example (courtesy of @TheStilt):ideally offering a competitive or even superior SPEC/GHz (or more generally perf/W) itself. There the potential gap to fill is still big enough to ensure sufficient work for AMD in the foreseeable time.

You are never gonna run it above 3.3 - 3.4 Ghz in a data-center (where it's usual for the vast majority of cores to be loaded 24/7). Therefore yes, in data-center SPEC/GHz does end up mattering. It's also the same for devices running on battery. You don't really want them running past that sweetspot for anything else than brief burst loads.
EDIT: spelling
Last edited:
insertcarehere
Senior member
- Jan 17, 2013
- 712
- 701
- 136
In AMD's arguable most important market, datacenters, this is by far not as clear cut. There the combination of high frequency plus high IPC is not as applicable, instead it's pure IPC since lower frequency translates to higher effciency. Apple in this regard is no direct competitor, but a good target to strive for for all chip designers.
A higher SPEC/GHz will be a crucial advantage in datacenters since the higher the value, the more processing power one can pack in a given power envelope, the higher one can scale the amount of cores. ARM with Neoverse and chip designers like Nuvia are in progress of catching up with Apple. To stay ahead in datacenters AMD needs to be mindful of the impact many cores ARM servers can have in datacenters, ideally offering a competitive or even superior SPEC/GHz (or more generally perf/W) itself. There the potential gap to fill is still big enough to ensure sufficient work for AMD in the foreseeable time.
Comparing AMD's designs to the Apple cores for peak performance is fun and all, but the real test for Zen 3 from ARM are the more efficient Cortex X1/A78 designs. We should know a bit more by December with the S875 announcement.
Not really quite fair, that's comparing a 5nm design to 7nm.Comparing AMD's designs to the Apple cores for peak performance is fun and all, but the real test for Zen 3 from ARM are the more efficient Cortex X1/A78 designs. We should know a bit more by December with the S875 announcement.
moinmoin
Diamond Member
- Jun 1, 2017
- 5,248
- 8,463
- 136
I doubt stock Cortex X1/A78 designs will already surpass Apple's cores in perf/W so for the time being Apple will stay the upper level of possible IPC performance to strive for.Comparing AMD's designs to the Apple cores for peak performance is fun and all, but the real test for Zen 3 from ARM are the more efficient Cortex X1/A78 designs. We should know a bit more by December with the S875 announcement.
insertcarehere
Senior member
- Jan 17, 2013
- 712
- 701
- 136
Except Cortex A77/A76 designs on 7nm already significantly outperform the Apple cores efficiency wise, and there's little reason to believe that changes for the cores moving forward.I doubt stock Cortex X1/A78 designs will already surpass Apple's cores in perf/W so for the time being Apple will stay the upper level of possible IPC performance to strive for.
moinmoin
Diamond Member
- Jun 1, 2017
- 5,248
- 8,463
- 136
@insertcarehere Ok, thanks for the correction. Makes me wonder why we see so little of stock ARM's advantage over Apple on the market.
amrnuke
Golden Member
- Apr 24, 2019
- 1,181
- 1,772
- 136
AMD isn't in the smartphone market, so I can only assume you're bringing up ARM as a better competitor than Apple because of the server or laptop environment.Comparing AMD's designs to the Apple cores for peak performance is fun and all, but the real test for Zen 3 from ARM are the more efficient Cortex X1/A78 designs. We should know a bit more by December with the S875 announcement.
Re: the laptop market it's getting cleanly fragmented right now - ARM is still in Chromebook land. Apple will be in Mac land. And AMD/Intel will continue fighting in Windows land. As ARM on Windows starts moving faster, that will obviously change, but again there will still be walls up between x86 and ARM ISAs.
Regarding ARM vs Apple, going off topic, if we accept ARM and Apple claims, then X1 will be 6 months behind the A14, and 34% behind in raw performance at the same 3.0 GHz clock speed. Year-to-year, it closes the gap, but we still need to check on power efficiency, and it's still going to be well behind in performance, even if it's more efficient (see my response to moinmoin below).
Regarding ARM vs AMD in the server space, assuming Neoverse 2 can parallel improvements that A78 and X1 bring, then the next server nodes could be quite good, at least in power efficiency. That being said, from a performance standpoint, a projected X1 SPECint2006 score of 47.2 @ 3.0 GHz leaves them within shooting range of the 3950X but still leaves it 33% behind the raw projected 5900X scores I calculated above. If we assume they can scale speed up to 3.5 GHz then it only falls 14% behind in raw performance to the 5900X. Again, this is just single core, so in the server space, a lot still needs to be hammered out since much of the cost of the system comes from other components as well.
Additionally, if AMD move to the same 5nm process ARM are projecting, doing so on Zen3 for some custom rollouts, power efficiency gains could bring things even closer on the EPYC side.
I'd argue that phone users would be more concerned with total J used rather than W given battery constraints. Andrei projects X1 to score 47.2 and draw 7846 J, while we know A13 scores 52.82 and draws 11135 J. Overall this projects that the A13 uses 63% more W to achieve the same task 12% faster, resulting in a 42% increase in total J drawn. That speed increase may be worth it depending on the battery technology used and efficiencies in other areas.I doubt stock Cortex X1/A78 designs will already surpass Apple's cores in perf/W so for the time being Apple will stay the upper level of possible IPC performance to strive for.
insertcarehere
Senior member
- Jan 17, 2013
- 712
- 701
- 136
@insertcarehere Ok, thanks for the correction. Makes me wonder why we see so little of stock ARM's advantage over Apple on the market.
A few factors go into it:
- The closed, walled garden approach allows Apple to optimize software in a way that Android cannot.
- Phone usage involves inherently bursty loads which perfectly epitomize "race to idle" with only the small cores in the SoC being under load for most of the time, and Apple's small cores destroy the ancient ARM Cortex A55s on that front in both performance and efficiency.
moinmoin
Diamond Member
- Jun 1, 2017
- 5,248
- 8,463
- 136
Makes me (again) wish for all benchmarks to include the amount of joules consumed.I'd argue that phone users would be more concerned with total J used rather than W given battery constraints. Andrei projects X1 to score 47.2 and draw 7846 J, while we know A13 scores 52.82 and draws 11135 J. Overall this projects that the A13 uses 63% more W to achieve the same task 12% faster, resulting in a 42% increase in total J drawn. That speed increase may be worth it depending on the battery technology used and efficiencies in other areas.
amrnuke
Golden Member
- Apr 24, 2019
- 1,181
- 1,772
- 136
What's clear is that Apple throws a lot of energy at the speed problem, and tosses efficiency out the window at those times.Makes me (again) wish for all benchmarks to include the amount of joules consumed.
What's not clear is how often a normal user pushes the Lightning core to its max, or whether people are largely using the Thunder cores when they "Like" their high school acquaintance's word-image hymn post on Facebook, making the power consumption numbers for Lightning largely useless if that's the case.
In AMD's arguable most important market, datacenters, this is by far not as clear cut. There the combination of high frequency plus high IPC is not as applicable, instead it's pure IPC since lower frequency translates to higher effciency. Apple in this regard is no direct competitor, but a good target to strive for for all chip designers.
I agree with this, but my point was that as far as raw performance goes, high IPC along with high frequency is the ultimate combo. Also, as amrnuke already illustrated several pages ago, Zen 3 manages to increase both performance and efficiency simultaneously on the same node, so they definitely know what they are doing and won't cede ground to ARM easily.
AMD has shown that you can have your cake and eat it too, by manufacturing a high frequency, high IPC and high efficiency CPU. Actually, Intel used to nail all three of those attributes but their struggles with their process node advancements have clearly stymied them in that regard.
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 23K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 23K
-

-

AnandTech is part of Future plc, an international media group and leading digital publisher. Visit our corporate site.
© Future Publishing Limited Quay House, The Ambury, Bath BA1 1UA. All rights reserved. England and Wales company registration number 2008885.