
Its a half node but I think there's a significant gain in density compared to 7nm that Zen 2 is using. Its not double but there seems to be room for AMD to increase the size of the chiplets (especially on EPYC and Threadripper). Plus, AMD will likely be changing packaging (i.e. socket) somwhere in there as well as shrinking the size of the I/O die, so they could increase the chiplet sizes themselves. And there's other aspects they can likely play with (shape of the chiplets as well for instance).
Well, I checked an article on Wikichip and was shocked to see that, according to TSMC's estimate, density will increase by approximately 85%!
This is probably for SRAM, so logic may not scale quite as well.
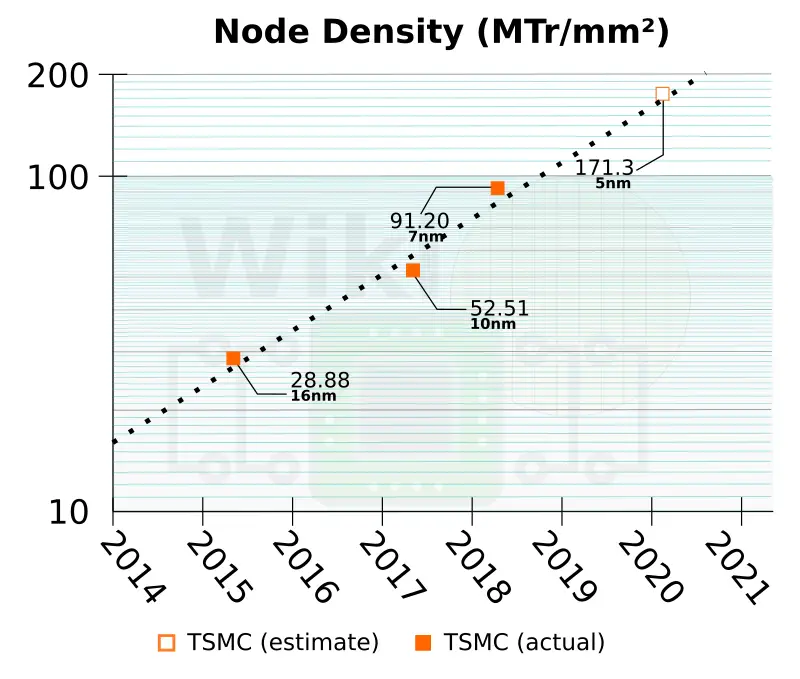
This give AMD allot of xtors to play with for Zen4. A 20% bump in chiplet size would double the number of CCXs per CCD, if AMD wants to go that way.
AMD may want to go for a wider core and increase cache instead. Lots of decisions to be made (well, AMD has already made them!).
Something I've been curious about (since I've been pushing for it a lot), due to the recent GF announcement about their new version of 12, including a new interposer for HBM (which I think HBM3 is supposed to be made on 12nm, so I'm still left wondering, what if they integrated the HBM into/on say the I/O die itself, skipping the interposer entirely), would slapping some of that with the I/O die let them reduce cache sizes? That'd let them increase core counts and/or size of the cores. Which, yes it'd be higher latency than L1, L2, and maybe L3 cache (although I think it'd be not that far off from the latter), but that could possibly be mitigated via the throughput (bandwidth), and pooling the cache (so perhaps there could be some smart sharing of resources that would mitigate latency issues). But maybe they could keep L1 and L2 cache low, replace L3 with a larger pool of HBM, which could double as buffer to system RAM and maybe even NAND, so that you're increasing the throughput significantly (more than making up with the slightly reduced latency).
HBM is way to slow compared to L3 cache, for example. The latency difference is huge (don't have the numbers on me, but HBM is at least an order of magnitude slower and would have to route through the IO chip to service all CCXs).
Last edited:
