There is patent from AMD about stacked die related on machine learning and GPU :
https://www.freepatentsonline.com/20210374607.pdf
Seems Greymon55 also saying that N3x will have ML die
Let's rekindle this thread, Computex is only 4 months away.
And of course the multi die GPU chiplets has been discussed at length and I will not repeat.
Many new patents from AMD for RT were published since the well known 11200724 :
Texture processor based ray tracing acceleration method and system (filed in 2017), which we know was used in RDNA 2/XSX/PS5
These are the new patents since then
10692271 Robust ray-triangle intersection
10706609 Efficient data path for ray triangle intersection
20200380761 COMMAND PROCESSOR BASED MULTI DISPATCH SCHEDULER
10930050 Mechanism for supporting discard functionality in a ray tracing context
20210209832 BOUNDING VOLUME HIERARCHY TRAVERSAL
Possible HW BVH Traversal
20210287421 RAY-TRACING MULTI-SAMPLE ANTI-ALIASING
20210287422 PARTIALLY RESIDENT BOUNDING VOLUME HIERARCHY
11158112 Bounding volume hierarchy generation
HW Assisted BVH structure generation
20210304484 BOUNDING VOLUME HIERARCHY COMPRESSION
BVH Compression
20210407175 EARLY CULLING FOR RAY TRACING
20210407176 EARLY TERMINATION OF BOUNDING VOLUME HIERARCHY TRAVERSAL
AMD is going all in on RT
But my most interesting part is the HW assisted convolution.
20200184002 HARDWARE ACCELERATED CONVOLUTION
This coupled with the ML chiplet (which is actually Cache+ML chiplet in one) could actually be the target implementation for
Gaming Super Resolution that we discussed here before
New Patent came up today for AMD's FSR

appft.uspto.gov
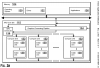
20210150669 GAMING SUPER RESOLUTION
Abstract
A processing device is provided which includes memory and a processor. The processor is configured to receive an input image having a first resolution, generate linear down-sampled versions of the input image by down-sampling the input image via a linear upscaling network and generate non-linear down-sampled versions of the input image by down-sampling the input image via a non-linear upscaling network. The processor is also configured to convert the down-sampled versions of the input image into pixels of an output image having a second resolution higher than the first resolution and provide the output image for display
It uses Inferencing for upscaling. As will all ML models, how you assemble the layers, what kind of parameters you choose, which activation functions you choose etc, matters a lot, and the difference could be night and day in accuracy, performance and memory
View attachment 44667
View attachment 44666
CNN are the most suited for performing ML with images and having that ML in the chiplet doesn't sound like a terrible idea.
One thing being that AMD could perform the upscaling without using motion vectors and utilizing the image at the end of the rendering pipeline, the output of which could be kept at the L3/chiplet die.
Another thing they mentioned in another patent is that they can extract motion vectors from pixel activity from multiple images instead of relying on games engine to provide the motion vectors
This means they can stick the upscaler in something like RSR without game engine integration.
The ML+Cache chiplet could actually be 3D IFC which could run on a different clock domain than the CUs.
And being specially optimized for convolution could mean that they are better for ML inferencing with images than general purpose matrix units
This could be the real Gaming Super Resolution, basically Radeon Super Resolution taken to the next level requiring no game integration at all.
/speculation
One hint, patents which are continuations or taking advantages of provisional patents are good candidates for being actual product technology
Linux merge window for 5.18 is coming in two months, so watch out for that
Infinity cache is like tailor made for BVH transversal. Similarly ML units sitting so close to the Cache is like PIM.
They just need to glue them well. FIngers crossed