Despoiler
Golden Member
True, but I've already tried up to 1.2v with the same result.
I didn't really want to go any higher.
Change your VTT DDR from auto to 0.675v.
True, but I've already tried up to 1.2v with the same result.
I didn't really want to go any higher.
Worth a go, I had assumed auto would set this anyway, as it's 1/2 of 1.35v as per spec.Change your VTT DDR from auto to 0.675v.
Worth a go, I had assumed auto would set this anyway, as it's 1/2 of 1.35v as per spec.
Thanks
Well, good news. Of sorts.From what I have read motherboard auto settings are not working correctly in this respect.
Yeah my Asus Prime X370-Pro seems to have a very nice design for a $160 board.That's . . . interesting. Look at all the doublers in use.
How does than compare to the previous with your ram?
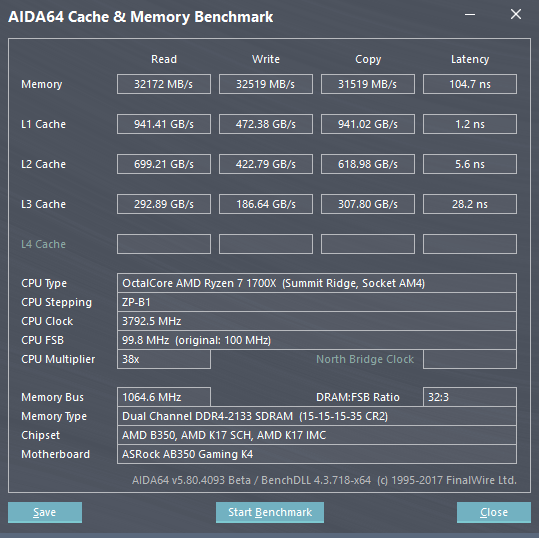
Wow, check out the the L2 and L3 latency, no problem there.Memory results didn't change at all.
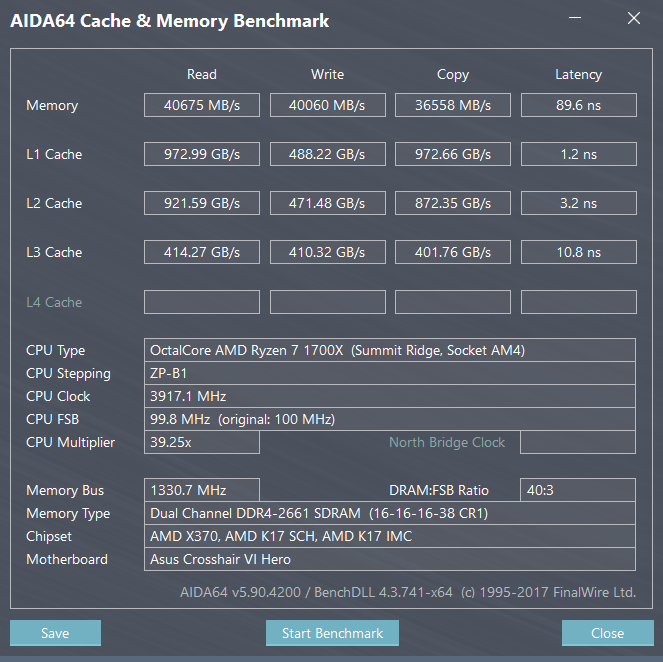
My former results (at 3.8GHz with DDR4-2133 speeds).
I am rerunning 3Ghz and stock with DDR4-2133 and DDR4-2667 speeds.
Despite 2933 now being doable, it's unstable, so I'm not going to mess with it outside of the memory section of the review (which is slowly coming along - I now have time to devote to it fully).
--
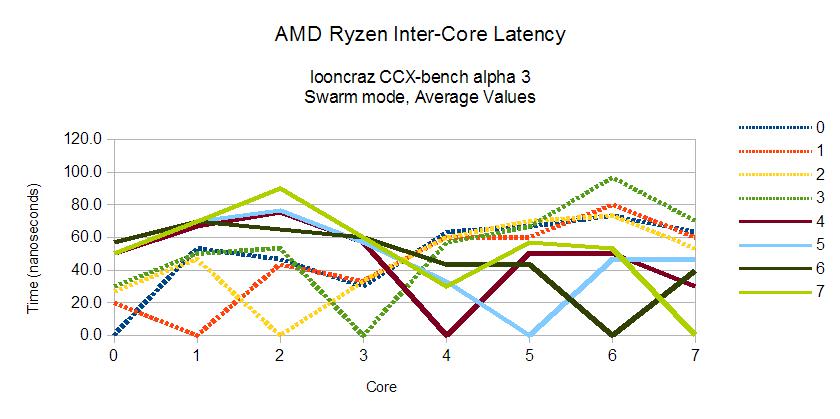
I'd also like to say that this seems to support my results that suggest burst/best inter-CCX latency is actually only 20ns, maybe even slightly less. It's just some coordination or microcode issue - the data fabric is insanely good.
Wait, what results, did i miss anything? Anyways, "best" inter-CCX latency may as well be intra-CCX, considering that 2*10.8ns = 21.6ns, in line with your results.I'd also like to say that this seems to support my results that suggest burst/best inter-CCX latency is actually only 20ns, maybe even slightly less. It's just some coordination or microcode issue - the data fabric is insanely good.
Well, didn't we know that anyway? AMD did mention something like 12 cycle latency for l2 and ~40 (i believe) for l3.Wow, check out the the L2 and L3 latency, no problem there.
Wait, what results, did i miss anything? Anyways, "best" inter-CCX latency may as well be intra-CCX, considering that 2*10.8ns = 21.6ns, in line with your results.
They also fixed the FMA3 throughput measurement. Instlatx now reports 0.5 t'put for all of them.@looncraz did you get to test the FMA and AVX2-optimized benchmarks for Ryzen in version 5.90?
I haven't released any specific results... until now, I guess:
You can see that the average gap between intra-CCX and inter-CCX latency is about 20ns.
There are 192 bits of data sent between cores for the entire process and I am deploying lock-free atomics for synchronization. Swarm mode (the only currently working mode) has the downside of high volatility in the results - this is a simple averaging of three runs.
EDIT:
From those runs, average inter-CCX latency was 25.5ns, peak was 19.2ns.
I haven't released any specific results... until now, I guess:
You can see that the average gap between intra-CCX and inter-CCX latency is about 20ns.
There are 192 bits of data sent between cores for the entire process and I am deploying lock-free atomics for synchronization. Swarm mode (the only currently working mode) has the downside of high volatility in the results - this is a simple averaging of three runs.
EDIT:
From those runs, average inter-CCX latency was 25.5ns, peak was 19.2ns.
That did jump out at me. 6 phase primary on the X370-Pro vs. doubled 4 on the C6H.
I haven't released any specific results... until now, I guess:
You can see that the average gap between intra-CCX and inter-CCX latency is about 20ns.
There are 192 bits of data sent between cores for the entire process and I am deploying lock-free atomics for synchronization. Swarm mode (the only currently working mode) has the downside of high volatility in the results - this is a simple averaging of three runs.
EDIT:
From those runs, average inter-CCX latency was 25.5ns, peak was 19.2ns.
Can't confirm but
Zen HEDT CPU's are called Threadripper!
Each CPU will include 64 PCI-E Lanes!
It includes 4 CCX's.
Lower SKU(Probably 12/24) 140W TDP, Higher SKU (Probably 16/32) 180W TDP.
Socket will be an SP3 LGA
Platform's name will probably be X399
Chips will be B2 revisions.
32MB L3 Cache
ES's are 3,3 or 3,4 Ghz base and 3,7 Ghz Boost
It is aimed for Retail SKU to have 3,6 Base/4 Ghz Boost
ES's that are in the wild have 2500 CB R15.
Infinity Fabric can have a bandwidth up to 100GB/S
Announcement; COMPUTEX at Taiwan, sales will start after 2-3 weeks following COMPUTEX.
Wow