-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Ryzen: Strictly technical
Page 27 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
- Status
- Not open for further replies.
malventano
Junior Member
The problem is the "Processor group" split, not the "NUMA group" split. If you could create two NUMA groups, without creating two Processor groups, it might give a better result, but it doesn't look like Microsoft is offering that option.
Actually, when I tried testing the split on Ryzen this morning, it did not work as it does with other CPUs. It only ended up disabling the cores after the boundary that should have started an additional NUMA node. Perhaps there is some whitelisting / configuration that needs to be coded into Windows to properly support manual NUMA splitting with Ryzen.
Either way, at least we can put the scheduler rumors to bed now that AMD has released a statement confirming the scheduler is not the issue (in Windows 10 and in Windows 7).
Kromaatikse
Member
Colour me confused, then.
My best interpretation of AMD's statement is: Windows is choosing the cores in the right order for performance (physical before virtual). But this is not implemented by the scheduler - rather, by the core parking algorithm.
They are however saying nothing about Windows' insistence on moving threads around so restlessly. That *is* a property of the scheduler, and it *is* harmful, on both Intel and AMD CPUs.
My best interpretation of AMD's statement is: Windows is choosing the cores in the right order for performance (physical before virtual). But this is not implemented by the scheduler - rather, by the core parking algorithm.
They are however saying nothing about Windows' insistence on moving threads around so restlessly. That *is* a property of the scheduler, and it *is* harmful, on both Intel and AMD CPUs.
looncraz
Senior member
Actually, when I tried testing the split on Ryzen this morning, it did not work as it does with other CPUs. It only ended up disabling the cores after the boundary that should have started an additional NUMA node. Perhaps there is some whitelisting / configuration that needs to be coded into Windows to properly support manual NUMA splitting with Ryzen.
Either way, at least we can put the scheduler rumors to bed now that AMD has released a statement confirming the scheduler is not the issue (in Windows 10 and in Windows 7).
I had the same experience when I set groupsize on Ryzen with Windows 7. Haven't tried with Windows 10, yet.
I will say one thing: Ryzen has the worst cache performance characteristics of any CPU of mine I have tested (so far) when dealing with random data.
We're talking about THREE TIMES worse... That's the main problem with some of the games.
Mind you, I'm still testing with DDR4-2133 CL15 2T settings, so that has an impact.

looncraz
Senior member
Colour me confused, then.
My best interpretation of AMD's statement is: Windows is choosing the cores in the right order for performance (physical before virtual). But this is not implemented by the scheduler - rather, by the core parking algorithm.
They are however saying nothing about Windows' insistence on moving threads around so restlessly. That *is* a property of the scheduler, and it *is* harmful, on both Intel and AMD CPUs.
My guess is that Microsoft plainly said: we aren't going to fix it for you, AMD. So AMD decided to stay in Microsoft's good graces, lest Microsoft further help Intel's monopoly.
AMD engineers have to understand this scheduling problem and how this is predominately a Windows problem and not application problem...
So why does the marketing department and customer service give another answer? Has MS said "your problem not ours" and AMD doesn't want to hurt their relationship with MS...? This makes no damn sense.
lol. looncraz beat me to it.
So why does the marketing department and customer service give another answer? Has MS said "your problem not ours" and AMD doesn't want to hurt their relationship with MS...? This makes no damn sense.
lol. looncraz beat me to it.
looncraz
Senior member
It is disabled.
"Comme pour au dessus, nous réalisons les tests à 3 GHz, le SMT est désactivé pour limiter la variabilité."
3GHz and SMT disabled
Thanks, I'm testing with both configurations right now. Cache performance seems to be positively abhorrent with random accesses. Even in-page.
Kromaatikse
Member
My guess is that Microsoft plainly said: we aren't going to fix it for you, AMD. So AMD decided to stay in Microsoft's good graces, lest Microsoft further help Intel's monopoly.
So we're back to the stupid manual workaround using CPU affinity. Hooray.
This is actually quite typical Microsoft attitude. As long as they have some convoluted workaround that needs applying on an application-by-application or installation-by-installation basis, they can pad their revenue streams from Support Incidents and training courses for Microsoft Certified Highly Paid Consultants. Indirectly, it even perversely reinforces the lock-in factor, because people are loath to discard all those tweaks they've built up over the years, even if the best alternative doesn't need them.
imported_jjj
Senior member
Thanks, I'm testing with both configurations right now. Cache performance seems to be positively abhorrent with random accesses. Even in-page.
Any guesses as to why?
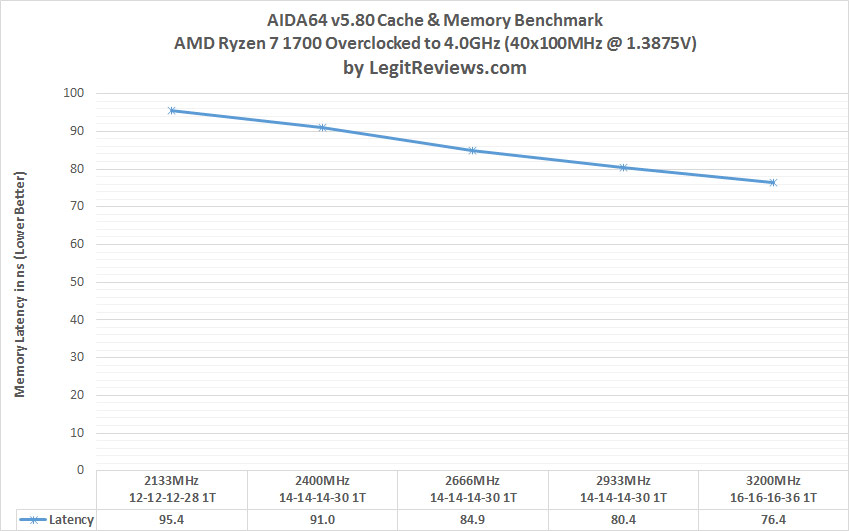
BTW, found this memory latency scaling graph, wonder if it can get a bit better if they open up access to more timings.Can't quickly find any tests with bclk OC as those could be helpful.
As for M$,maybe they are upset that Ryzen works on Win 7 since forcing AMD to not officially support it wasn't enough.
lolfail9001
Golden Member
The justification for moving threads is simple: scheduler cycles threads on any CPU all the damn time, so trying to force a thread onto the same core is actually a gamble for cache remaining hot against a whole quantum of time for thread being wasted. Workaround is basic: force highest priority on threads you do not want to see shuffled that often.They are however saying nothing about Windows' insistence on moving threads around so restlessly. That *is* a property of the scheduler, and it *is* harmful, on both Intel and AMD CPUs.
You may argue that Win10 is ignorant of CCX structure, but that's about it.
Also, i am the only one who finds the policy of reporting junction temperature offset by 20 degrees on X SKUs for nothing but to force fan to be louder... weird?
Wait, you are talking about L3, right (since well, L2 looks alright from what we see)? As in, it is slower than Phenom II? I'll blame memory instead of accepting it.I will say one thing: Ryzen has the worst cache performance characteristics of any CPU of mine I have tested (so far) when dealing with random data.
We're talking about THREE TIMES worse... That's the main problem with some of the games.
Kromaatikse
Member
The justification for moving threads is simple: scheduler cycles threads on any CPU all the damn time, so trying to force a thread onto the same core is actually a gamble for cache remaining hot against a whole quantum of time for thread being wasted. Workaround is basic: force highest priority on threads you do not want to see shuffled that often.
As I noted earlier, this is about threads which have nothing competing with them for the same core. The optimal strategy in that case, from a cache-miss, branch-predict and context-switch perspective, is always to keep it on that same core.
Any guesses as to why?
BTW, found this memory latency scaling graph, wonder if it can get a bit better if they open up access to more timings.Can't quickly find any tests with bclk OC as those could be helpful.
Thank you for that, I was correct, its definitely the UMC that is the issue. (or UMC + fabric). Its half speed MEMCLK will be its limitation, and with the Memory issues is likely to not be fixed this go around. Hardlocking the UMC and fabric speeds, preventing a software workaround, is the worst decision AMD could have possibly made.
Look at 2933 cl14 vs 3200 cl 16. With those timings 2933 should be faster(though scaling is never perfect). A massive decrease of roughly 4(approximately the average jump between 266mhz leaps) should not be possible. Not unless the bottleneck is the UMC.
6900k has 2.8ghz uncore. Skylakes have substantially faster. At 3200mhz, it would have 1.6ghz on ryzen. You would need Memory speeds in the range of at least 4800mhz to be able to reach anything close to parity(likely even more as 6900k OCers raise it to around 3.5 to maximize its performance).
The only change that occured for those latency jumps is the gradual bump of UMC + fabric speeds in that benchmark.
Edit: fixed last sentence. Not sure what that was about.
Kromaatikse
Member
Also, i am the only one who finds the policy of reporting junction temperature offset by 20 degrees on X SKUs for nothing but to force fan to be louder... weird?
If it's the only reported temperature directly from the CPU, then yes it is weird. I would expect to see a true reading alongside the "fan reference" tweaked one.
looncraz
Senior member
So we're back to the stupid manual workaround using CPU affinity. Hooray.
This is actually quite typical Microsoft attitude. As long as they have some convoluted workaround that needs applying on an application-by-application or installation-by-installation basis, they can pad their revenue streams from Support Incidents and training courses for Microsoft Certified Highly Paid Consultants. Indirectly, it even perversely reinforces the lock-in factor, because people are loath to discard all those tweaks they've built up over the years, even if the best alternative doesn't need them.
I think AMD is preferring to work with the specific game companies whose engines have issues rather than dealing with Wintel.
I've found at least two bugs in Windows related to Ryzen (setting groupsize disables half of Ryzen cores, but acts properly on Intel (Windows 7 - haven't tested with 10, yet) and setting affinity to every other logical core forces workloads to just two cores (Windows 10, about to test on 7)).
looncraz
Senior member
Any guesses as to why?
BTW, found this memory latency scaling graph, wonder if it can get a bit better if they open up access to more timings.Can't quickly find any tests with bclk OC as those could be helpful.
As for M$,maybe they are upset that Ryzen works on Win 7 since forcing AMD to not officially support it wasn't enough.
That's a difference of only 5ns - or ~15 cycles.
I'm seeing differences of 60 cycles on Intel and > 300 cycles on Ryzen.
I'll make charts soon.
Kromaatikse
Member
setting affinity to every other logical core forces workloads to just two cores
Is that with core parking on or off?
lolfail9001
Golden Member
That would work if your threads never had to interact with OS.As I noted earlier, this is about threads which have nothing competing with them for the same core. The optimal strategy in that case, from a cache-miss, branch-predict and context-switch perspective, is always to keep it on that same core.
Their statement clearly implies it is the only reading of temperature from CPU.If it's the only reported temperature directly from the CPU, then yes it is weird. I would expect to see a true reading alongside the "fan reference" tweaked one.
Wait, wait wait, difference between what?That's a difference of only 5ns - or ~15 cycles.
I'm seeing differences of 60 cycles on Intel and > 300 cycles on Ryzen.
I'll make charts soon.
Actually, when I tried testing the split on Ryzen this morning, it did not work as it does with other CPUs. It only ended up disabling the cores after the boundary that should have started an additional NUMA node. Perhaps there is some whitelisting / configuration that needs to be coded into Windows to properly support manual NUMA splitting with Ryzen.
Either way, at least we can put the scheduler rumors to bed now that AMD has released a statement confirming the scheduler is not the issue (in Windows 10 and in Windows 7).
Hi, i took a look at your test suite on Pcper. Assuming your result are correct, there are a few things i still cant catch.
The inter CCX connection for example. It is a fact that because of nature of the data fabric shifting tread from a CCX to another result in a heavy penalty. Also , it's been prooved that, at least in some scenarios, Windows 10 allocate the treads without the precaution to shift CCX as little is possible.
https://www.youtube.com/watch?v=JbryPYcnscA
https://www.youtube.com/watch?v=BORHnYLLgyY
So, why AMD refuse in any means to culprit windows 10?
looncraz
Senior member
Is that with core parking on or off?
Either, always the same results.
TheELF
Diamond Member
Are they windows bugs? Did AMD release any info on SMT yet? If it is like IBM's power it might just join the two smt threads of a core into a super slice which would be proper and logical behaviour. (from the standpoint of someone who has no idea (me) about how power works)I've found at least two bugs in Windows related to Ryzen (setting groupsize disables half of Ryzen cores, but acts properly on Intel (Windows 7 - haven't tested with 10, yet) and setting affinity to every other logical core forces workloads to just two cores (Windows 10, about to test on 7)).
looncraz
Senior member
Wait, wait wait, difference between what?
Intel has 60 cycles latency in random access... Ryzen has > 300cycles in the same test.
Ryzen cache latency performance is simply abysmal. It has a narrow window where it's better than intel for linear accesses thanks to a larger L2 per core.
I'm currently testing with SMT off, results are only slightly better - and only in a very narrow region.
After this series of tests I will disable a CCX and test once again, since these numbers are likely including the CCX penalty.
Then, finally, I will overclocked the memory and test with one CCX, no SMT, and max memory overclock (which is a meager 2667... using DDR4-3200 RAM).
we are waiting for your results!Intel has 60 cycles latency in random access... Ryzen has > 300cycles in the same test.
Ryzen cache latency performance is simply abysmal. It has a narrow window where it's better than intel for linear accesses thanks to a larger L2 per core.
I'm currently testing with SMT off, results are only slightly better - and only in a very narrow region.
After this series of tests I will disable a CCX and test once again, since these numbers are likely including the CCX penalty.
Then, finally, I will overclocked the memory and test with one CCX, no SMT, and max memory overclock (which is a meager 2667... using DDR4-3200 RAM).
Kromaatikse
Member
Are they windows bugs? Did AMD release any info on SMT yet? If it is like IBM's power it might just join the two smt threads of a core into a super slice which would be proper and logical behaviour. (from the standpoint of someone who has no idea (me) about how power works)
Considering that CPU affinity works perfectly on Linux on Ryzen, yes it's a Windows bug.
SMT is simply the ability to share the execution resources of one physical core between two virtual ones. When only one of those virtual cores is actually running, it gets *all* of the physical core's resources. That's the same as on Intel's HT, which is just a brand name for SMT technology.
Elixer
Lifer
Or, AMD's PR arm isn't talking to the engineers...My guess is that Microsoft plainly said: we aren't going to fix it for you, AMD. So AMD decided to stay in Microsoft's good graces, lest Microsoft further help Intel's monopoly.
Or, MS said that will cost millions, and AMD didn't want to pay for the update, so, now, all is fine, brush it under the rug, nothing new here, carry on!
- Status
- Not open for further replies.
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 24K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 24K
-

-
