Rigg
Senior member
- May 6, 2020
- 718
- 1,822
- 136
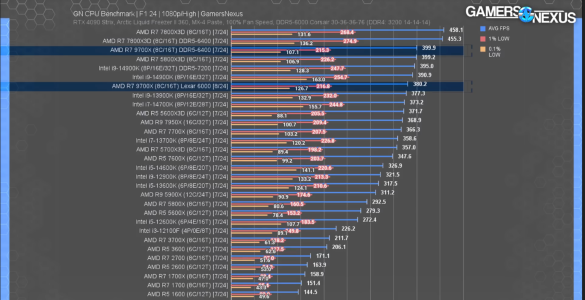
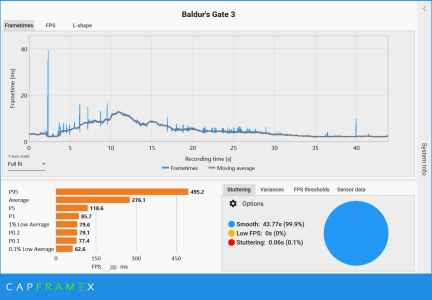
Then post some data of your own, because this seems like a very dismissive post; you don't like the results so the are invalid.
.1% are not anomalous and are the most important part of a PC gaming experience
If I am getting crap .1% lows with the 7800X3D / 7900XT system, something is up.
PUBG is prime example of the benefits of 3D cache and I can very much tell if the .1% lows are arse in an FPS
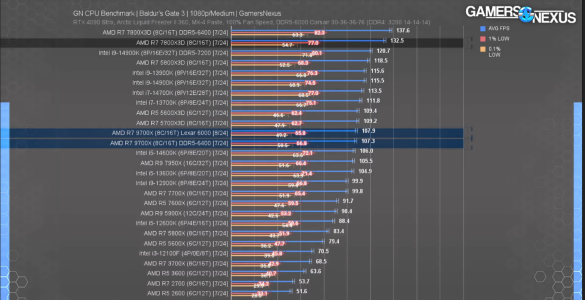
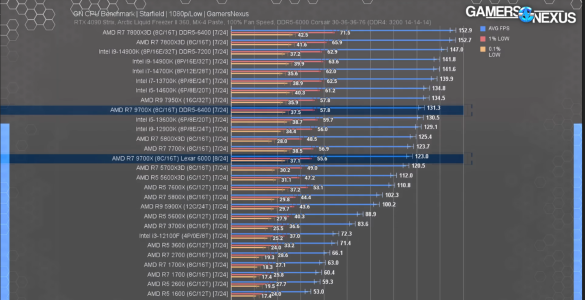
View attachment 104992
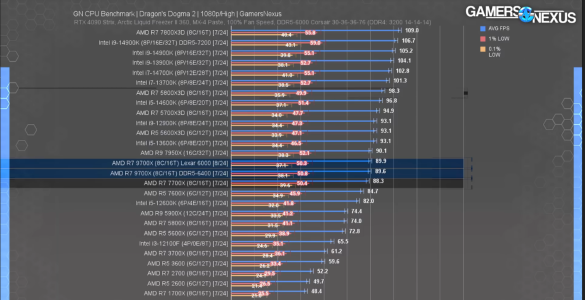
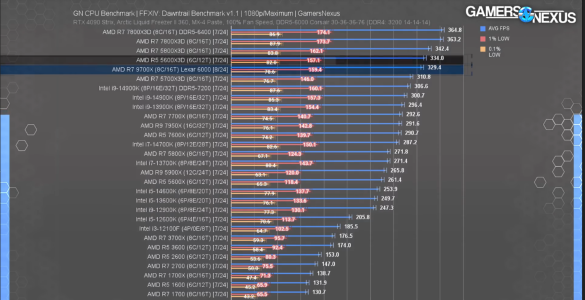
View attachment 104993

Chapter Eleven: If–Then Arguments – A Guide to Good Reasoning: Cultivating Intellectual Virtues
<i>A Guide to Good Reasoning</i> has been described by reviewers as “far superior to any other critical reasoning text.” It shows with both wit and philosophical care how students can become good at everyday reasoning. It starts with attitude—with alertness to judgmental heuristics and with the...
 open.lib.umn.edu
open.lib.umn.edu
You are misrepresenting what i said. I'm not going to engage with you if you can't argue in good faith.
Spamming your post all over the CPU forums without providing any logical analysis of the data doesn't give your argument any weight. Pretty much all 0.1% data should be taken with a grain of salt. Posting your opinion in big bold text doesn't make it any less misguided.
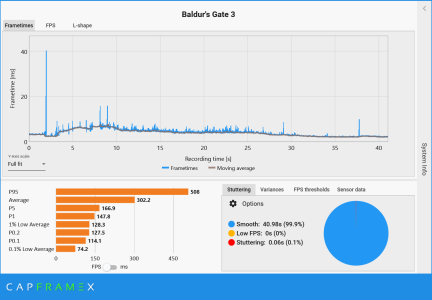
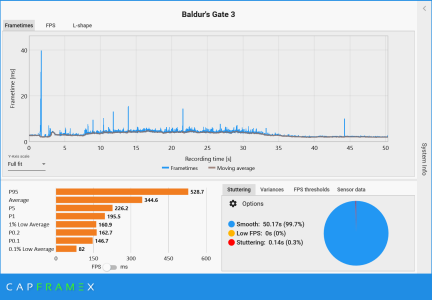
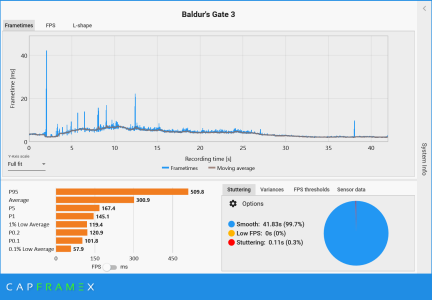
In the absence of details regarding the testing methodology, we have no way to know if any of these results are legitimate. Run to run variance, along with the length of the run, is going to greatly impact the 0.1% average. As myself and others have tried to explain to you, this is why meaningful 0.1% data is difficult (perhaps impossible) to gather and most reviewers don't provide it. Again, time and run to run variance greatly skew the data. It's on you to provide the testing methodology details (if Brian has provided them) so we can decide if this BG3 result is actually a feather in 9600X's cap, or just another useless data point on pretty chart.