Glo.
Diamond Member
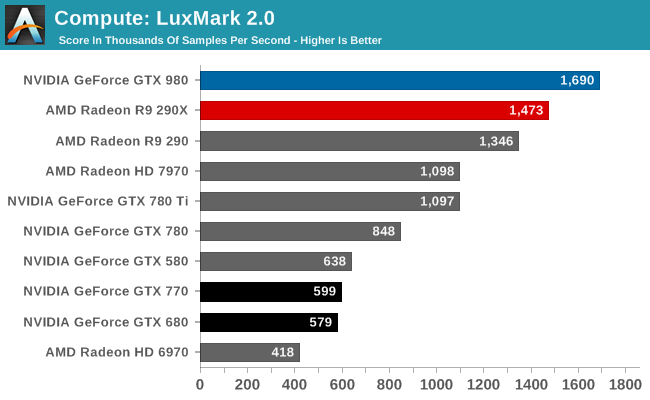
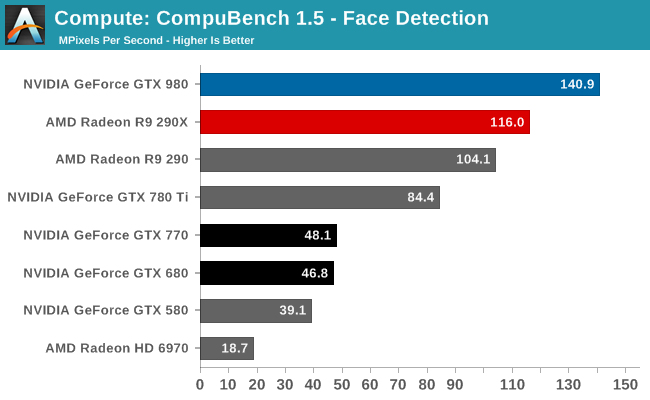
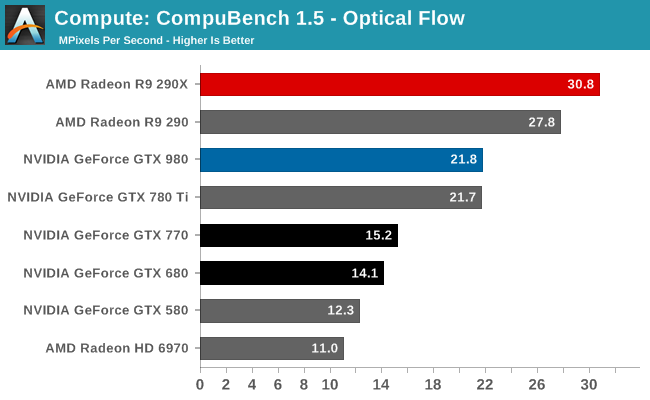
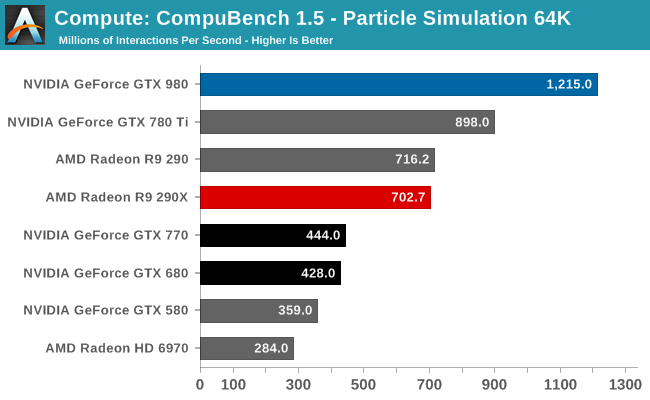
Explain then with why Maxwell GTX 980 with 2048 CUDA cores was faster in compute than GTX 780 Ti, that had 2880 CUDA cores?stop with this register file nonsense.Maxwell doubled Rops, 4x increase cache, brings 40% clock increase, new delta color compression, TB rasterization.This is why it was so much better than kepler.
ROPs will not bring you any meaningful performance uplift. Increased cache size - maybe, if your cores have enough throughput to handle it. Which had happened with Maxwell transition.
Tile Based Rasterization does not increase performance in meaningful way, but increases memory bandwidth efficiency, and overall efficiency of GPU under load.
And lastly. You cannot say that compute performance increase came from 40% higher core clocks. Which is pretty much BS.
GTX 980 has 4.1 TFLOPs of compute power. GTX 780 Ti - 5.5 TFLOPs. And yet, GTX 980 was faster in BOTH: compute and gaming.
So, do I still write nonsense about Register File Sizes, or do they have meaningful impact on performance of the GPU?
Oh, and here is a proof:
http://www.anandtech.com/show/7764/the-nvidia-geforce-gtx-750-ti-and-gtx-750-review-maxwell/3
NVIDIA hasn’t given us hard numbers on SMM power efficiency, but for space efficiency a single 128 CUDA core SMM can deliver 90% of the performance of a 192 CUDA core SMX at a much smaller size.
It is just because of the shift from 192 cores/256 KB RFS to 128 Cores/256 KB RFS. Those 128 Maxwell cores did exactly the same amount of job, as those 192 cores in Kepler. Which meant they have been less starved for work.
With Volta, and shift to 64 cores/256, those 64 cores, will do exactly the same amount of work as 128 cores in Maxwell/Consumer Pascal.
Last edited:



