
Intel Skylake / Kaby Lake
Page 377 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Arachnotronic
Lifer
- Mar 10, 2006
- 11,715
- 2,012
- 126
Eh, multi quote isn't working. Thanks for those who replied. I was afraid it was AVX-512 that was responsible for the large gains. Oh well, I keep hoping that for a surprise leak with SKL-EP (and hence SKL-X).
Well the leak here tells us that SKX doesn't sacrifice frequency potential for the cahce size gains
")
Last edited:
Edrick
Golden Member
- Feb 18, 2010
- 1,939
- 230
- 106
Looks like there is AVX 512 support in Sisoft.
http://www.sisoftware.eu/2016/02/24/future-performance-with-avx512-in-sandra-2016-sp1/
Very interesting read.
Nothingness
Diamond Member
- Jul 3, 2013
- 3,374
- 2,473
- 136
L2 cache size increase would not necessarily require frequency reduction; it could translate into latency increase. But I doubt the media score (fractal generation) is impacted by L2 latencyWell the leak here tells us that SKX doesn't sacrifice frequency potential for the cahce size gains
OTOH I was expecting freq reduction for AVX-512. It might be that Sandra is so short that no significant frequency reduction is needed.
Arachnotronic
Lifer
- Mar 10, 2006
- 11,715
- 2,012
- 126
L2 cache size increase would not necessarily require frequency reduction; it could translate into latency increase. But I doubt the media score (fractal generation) is impacted by L2 latency
That's very true, but what I found interesting was that in moving from Penryn -> Nehalem, Intel slashed L2$/core from 3MB (up to 6MB/core if only a single core was active/in use) -> 256KB (!) and only saw an improvement in latency from 15 cycles to 11 cycles. Then they added an 8MB L3$ which had a much higher latency than the older large L2$ (Anand says 39 cycles for Nehalem, and Kanter says this was reduced to 26-31 cycles in SNB).
I'm not convinced that this was a great trade off for client workloads and I strongly suspect that the reason Intel has kept the L2$ anemic for all of these years has been for cost reasons rather than good performance reasons (I believe L3$ is inclusive of L2$ so making the L2$ bigger with the current cache structure would have meant making the L3$ bigger too).
LTC8K6
Lifer
- Mar 10, 2004
- 28,520
- 1,576
- 126
Driverless cars need good CPUs and lots of fast computing power.Intel just spent $1.2 AMDs worth of money on some random Israeli driverless car company. Yet they cannot be bothered to invest more than a token amount in improving the Skylake core. Shows you where their priorities lie.
DDR4 @ 2631.4 MHz (DDR4-5262.8) with a Core i3-7350K -
New Memory World Record Highest Frequency
Pretty impressive.
New Memory World Record Highest Frequency
Pretty impressive.
VirtualLarry
No Lifer
- Aug 25, 2001
- 56,587
- 10,227
- 126
LN2-cooled RAM???
And even at that RAM speed, the HD630 probably still couldn't play Crysis 3 @ 1080p60.
And even at that RAM speed, the HD630 probably still couldn't play Crysis 3 @ 1080p60.
Arachnotronic
Lifer
- Mar 10, 2006
- 11,715
- 2,012
- 126
LN2-cooled RAM???
And even at that RAM speed, the HD630 probably still couldn't play Crysis 3 @ 1080p60.
Or even 720p60.
LTC8K6
Lifer
- Mar 10, 2004
- 28,520
- 1,576
- 126
Especially with the CPU running at only 1ghz...Or even 720p60.
LOL! And there is still a LN2 block on the CPUEspecially with the CPU running at only 1ghz...
i guess this kind of belongs here...
word out of Israel is, Rony Friedman is leaving Intel after 33 years for Apple. he was product manager for a long list of processors: Banias, Dothan, Yonah, Merom, Penryn, Sandy Bridge, Ivy Bridge, Skylake and Kaby-lake and also involved in future products KabyLake Refresh, Coffeelake, Cannonlake and Icelake.
it's nothing new that Intel engineers/execs leave to go to Apple, i think its a trend that been going on slowly in recent years. perhaps some of the old school at Intel don't like the direction the company is headed and are looking for bigger challenges.
word out of Israel is, Rony Friedman is leaving Intel after 33 years for Apple. he was product manager for a long list of processors: Banias, Dothan, Yonah, Merom, Penryn, Sandy Bridge, Ivy Bridge, Skylake and Kaby-lake and also involved in future products KabyLake Refresh, Coffeelake, Cannonlake and Icelake.
it's nothing new that Intel engineers/execs leave to go to Apple, i think its a trend that been going on slowly in recent years. perhaps some of the old school at Intel don't like the direction the company is headed and are looking for bigger challenges.
IntelUser2000
Elite Member
- Oct 14, 2003
- 8,686
- 3,787
- 136
L2 cache size increase would not necessarily require frequency reduction; it could translate into latency increase.
Not necessarily. When Intel doubled the L2 cache size going from Yonah to Merom, the latency didn't change. But going from Dothan to Yonah did, at the same 2MB size. There must be much more important reasons than size for latency purposes and Yonah had identical latency to Merom because they were based on the same cache structure.
I think of 4-way L2 on Skylake the same way. Preparation for Skylake server caches. Derivatives are used to save costs and time.
I'm not convinced that this was a great trade off for client workloads and I strongly suspect that the reason Intel has kept the L2$ anemic for all of these years has been for cost reasons
That makes little sense from what we know today. The likely reason for small L2 is to balance between latency and size. On Core uarch the gap between L1 and L2 was too large in terms of capacity and latency. The small L2 cache allows it to put something in between. We are seeing caches and buffers slotted into anything, because they want the worst case scenario to not be so horrible. Optane is to bridge the gap between DRAM and storage. L4 eDRAM and eventually package HBM is the same. There's no such thing as a magical solution to everything. Also the middle cache tier works well for multiple cores.
If we take a look at modern Intel core, you'll see the core square includes L2 cache. That tells me the L2 can't be considered separate from the core as Penryn was. If you want to increase the size, you'll have to arrange other parts of the core. It's a significant redesign, not trivial. In Nehalem days 256KB could have been the right balance between size and latency considering technology they had available to them too.
Yet they cannot be bothered to invest more than a token amount in improving the Skylake core
Throwing money won't solve all their problems. They are already by far the company with highest R&D budgets in their field. Spending money on acquisitions allow it to bring patents and ideas, which have more value. Of course it doesn't mean the buyout is always a correct decision.
Last edited:
Another Skylake-SP (ES?) dual-socket submission @ SiSoftware:
2x Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz (24C 48T 3.7GHz, 2.4GHz IMC, 24x 1MB L2, 33MB L3)
- Processor Arithmetic: 865.38GOPS
- Processor Multi-Media: 5049.12Mpix/s
- Processor Multi-Core Efficiency: 148.47GB/s
And the 3 latest games tested by GameGPU:


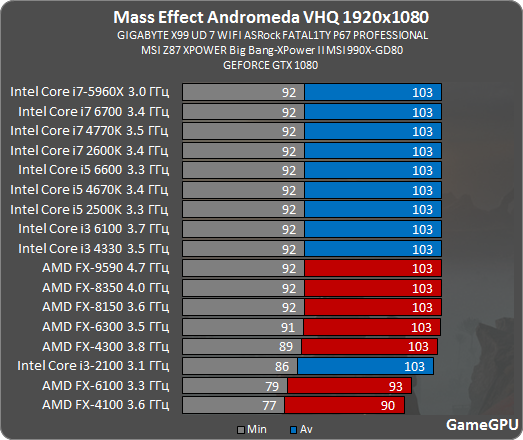
2x Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz (24C 48T 3.7GHz, 2.4GHz IMC, 24x 1MB L2, 33MB L3)
- Processor Arithmetic: 865.38GOPS
- Processor Multi-Media: 5049.12Mpix/s
- Processor Multi-Core Efficiency: 148.47GB/s
And the 3 latest games tested by GameGPU:
I just made quick benchmark in rise of the tomb raider and how fast memory are extremely important for skylake/kaby.Also i downclock 6700k to 3.5Ghz with 3000mhz memory and oc 6700k to 4500Mhz + slow 2133mhz ddr4 and compare performance.And yes 3500Mhz cpu with fast memory is faster...
6700k 4.5ghz memory scaling

Frametimes

6700k 3500mhz+3000Mhz cl14 ddr4 vs 4500mhz+2133mhz cl14 ddr4

Test scene 1920x1080 very high preset dx11(recorded with 4500mhz cpu and 2133mhz ram)
6700k 4.5ghz memory scaling
Frametimes
6700k 3500mhz+3000Mhz cl14 ddr4 vs 4500mhz+2133mhz cl14 ddr4
Test scene 1920x1080 very high preset dx11(recorded with 4500mhz cpu and 2133mhz ram)
Your test doesnt prove anything in regards to the skl arch because the results will probably be similar on eg ivy bridge if you take into account the througput of skl is faster. Thats the data we have seen earlier.
Its a test for skl on this specific game.
Its a test for skl on this specific game.
Not exactly Skylake / Kaby Lake related, but still interesting:
[Various] Overclocker discovers Xeon E5 V3 Errata, Engineers exploit to unlock Turbo
http://www.xtremesystems.org/forums/showthread.php?293290
[Various] Overclocker discovers Xeon E5 V3 Errata, Engineers exploit to unlock Turbo
I was able to recreate and test this mod myself and verify its functionality with breathtaking results
The test system consists of an Asrock EPC612D4I ITX 2011v3 motherboard, and Intel Xeon E5 2683v3 14 core, 16gb of DDR4 sodimm
The Original system without the unlock was able to run Cinebench R15 to the tune of almost 1600 points.
After the Exploit was applied the same system scored a blistering 1903 points in Cinebench R15
To further test I ran Firestrike ultra to retrieve a physics score of 16024 before the exploit was applied
http://www.3dmark.com/fs/11829078
After the exploit the same Firestrike ultra physics score increased to a amazing 19264
http://www.3dmark.com/fs/11978056
benchmarking further only validated the incredible results of the exploit these gentlemen have engineered.
To clalify this Exploit ONLY works with Xeon V3 socket 2011-3 processors. Have fun.
http://www.xtremesystems.org/forums/showthread.php?293290
Increasing all-core Turbo to 1-core frequency is what thread What controls Turbo Core in Xeons? explores.
So some websites are assuming this CPU is based on Skylake-SP:
http://browser.primatelabs.com/v4/cpu/2119144
Cache sizes and family/model name don't match though. Could it be a custom Haswell SKU?
http://browser.primatelabs.com/v4/cpu/2119144
Operating System Linux 4.7.0-0.bpo.1-amd64 x86_64
Model Google Google Compute Engine
Processor Intel Xeon @ 2.30 GHz
1 processor, 32 cores, 64 threads
Processor ID GenuineIntel Family 6 Model 63 Stepping 0
L1 Instruction Cache 32 KB x 32
L1 Data Cache 32 KB x 32
L2 Cache 256 KB x 32
L3 Cache 46080 KB
Motherboard Google Google Compute Engine
BIOS Google Google
Memory 419242 MB
Cache sizes and family/model name don't match though. Could it be a custom Haswell SKU?
Arachnotronic
Lifer
- Mar 10, 2006
- 11,715
- 2,012
- 126
So some websites are assuming this CPU is based on Skylake-SP:
http://browser.primatelabs.com/v4/cpu/2119144
Cache sizes and family/model name don't match though. Could it be a custom Haswell SKU?
Could be a custom Haswell SKU, IMO. It can't be single die because there's not enough room in 22nm to allow for that, but an MCM could work.
Another tested game.Witcher3 moded with 15mods+STLM.It is far more cpu heavy than vanilla game.CPU is same 6700k.3500mhz cpu with fast ram is again faster than 4500Mhz with slow ddr4 2133mhz.Next game will be maybe gta5


And again 3500Mhz cpu + 3000mhz ddr4 vs 4500Mhz cpu with slow 2133mhz ddr4


Test scene(recorded with 3500mhz cpu)
And again 3500Mhz cpu + 3000mhz ddr4 vs 4500Mhz cpu with slow 2133mhz ddr4
Test scene(recorded with 3500mhz cpu)
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 24K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 23K
-

-

AnandTech is part of Future plc, an international media group and leading digital publisher. Visit our corporate site.
© Future Publishing Limited Quay House, The Ambury, Bath BA1 1UA. All rights reserved. England and Wales company registration number 2008885.