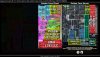
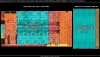
~50 10mm2 cores can be put on a 650 mm2 tile that uses EMIB to connect to another such tile and an ”IO tile”. The extra 150mm2 is for EMIB support and accelerators. And let’s assume 10-15% cores have to be disabled due to defects. That‘s 85-90 functioning cores. Is that enough? In 2024??
Why assume they're limited to two such tiles? One of the graphics shown above includes three. Purely in terms of core count, that should make Intel reasonably competitive.
People here don’t even believe Intel can yield 400 mm2 SPR die on now fairly mature Intel 7. Is full year of yield learning good enough to have such high confidence in yielding ginormous die? There is also plenty of learning Intel 3 has to go through for new features. And not everything is going to be orthogonal there.
I've said it many times now, but those blaming yields for SPR is simply incorrect. No sense in humoring that train of thought further.
As for Intel 3 vs 4, for a compute tile, the new libraries wouldn't make much of a difference, and they clearly thought they could do it on Intel 4 originally. Might even be design compatible.
How does one have a passive interposer/base die with cache on it? Don’t the cache transistors need switching??
If you absolutely require bigger caches to support the large number of cores, what other options does one have, other than stacking? And, what about memory accesses? Doesn’t that need to be low latency?
I should clarify. When I was talking about a passive interposer, I meant just to consider how many raw wafers extra that would require. Intel ships a
lot of server chips. Is that much spare wafer capacity sitting around?
And then if you want an
active interposer, well now you have to find that same capacity on a modern-ish node (depending what you want on there). With the chip shortage in mind, is that possible? And keep in mind that there's a balance here. You could theoretically move the L3 and IO to the base die, but then you would want it to be a modern process to benefit from high SRAM density, high performance for fast IO, etc. A pure SLC/memory-side cache die could be much cheaper, but then you probably need at least the memory controller and L3 on top for performance.
Also, Foveros wouldn't really save memory latency. You'd still want the controller and PHY at the edge, as you would on a monolithic die, but then you also have the overhead of die-die hop.
Falcon Shores etc, being intermediate steps to Zetta scale, are really large designs. Making them 2.5D would make the socket stupendously huge
Yeah, these would be huge designs, but is that a problem? Birch Stream is rumored to be what? 7529 pins? Seems to fit!