Truth is truth.
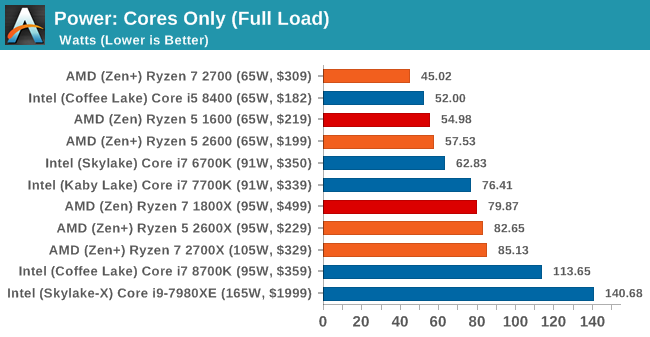
Having an understanding of comp arch allows one to know there is an integer pipeline and a floating point pipeline in a processor (they're essentially two distinct compute units in a core). A floating point pipeline is rarely used. GPUs were designed for this purpose. The floating point pipeline will use substantially more power. For this reason, it isn't referenced in TDP figures. This is yet another gaff/gimmick conducted by popular reviewers. Referencing IPC (Instructions per clock) is another gimmick as no other analysis or detail is often provided and is required tbqh. Time to process a program and speedups therein is sufficient.
The amount of confusion and lack of clear detail on this matter speaks for itself.
No one can defy physics. The higher the clock the less power efficient.
Professional processors used in the enterprise market shoot for lower clocks, lower power utilization, and support for larger system memory foot prints. The idea is to hit the golden middle ground on power/performance where its most efficient as every inefficient watt matters when you begin scaling to 1000s of nodes. The key also is to put as much as you can in system memory because the bottleneck still is data retrieval and a cpu is doing nothing when it is waiting on the data it needs for computation.
Meanwhile, we have the hotrod desktop market where it seems no on cares about power utilization and wants bragging rights for clock speeds. What i hear here is mixed signals. People claim they are doing professional loads that actually max computer resources but then also argue this is only possible on the least professional hardware configuration. Something obviously is awry.
Distributed computing exists and no one is bound to one computer. If the load is serious enough you can distribute it or pony up and get higher core counts for a task that consumes 8+ cores worth of compute. Surprise : Clocks begin to lower with increased core count. At 8 cores, someone is arguably already in enterprise/server market. At 16 cores, you most definitely are. However, no one seems to behave like that's what is under the hood. Trying to hotrod at these levels comes with huge power inefficiency However, lets ignore this like heat/power utilization are not important.
Someone would rather use two processors worth of CPU power to get a couple hundred more clocks. Meanwhile, memory stall count is soaring. This is where the assertion of professional computing becomes laughable. This is where the consumer focused benchmarking becomes laughable. This is where doing power analysis on floating point operations and referencing TDP figures associated with the integer pipeline on a CPU become laughable. The whole thing is a joke. I recognize an enthusiast element but this clearly conflicts with declarations of professionalism.
No one in the professional market is crying over 2.xx - 3.xx clock speeds. There's something called networking/distributed computing that allows you to scale across nodes if you are in such a dire need to get things done in the blink of an eye. Hell, there's cloud computing on demand. Go for gold with 200 cores worth of compute.
So, what we have left is gaming. I get the enthusiast aspect of high fps at resolutions eyes will not perceive in high action scenes. However, this is not a professional market.
1 or 2 cores clocking up to 5GHz is not going to change the world. My life doesn't become exponentially better because chrome opens up a millisecond less than what it used to.This is why I title such things a gimmick. It's a gimmick when AMD does it and its a gimmick when Intel does it. It's marketing as clearly reflected in the thread title. HEADLINE : 8 core Processor hits 5GHz. Reality fine print : Only on two cores. How do memory stalls scale w/ increase CPU clock speed? No reviewer delves into this.