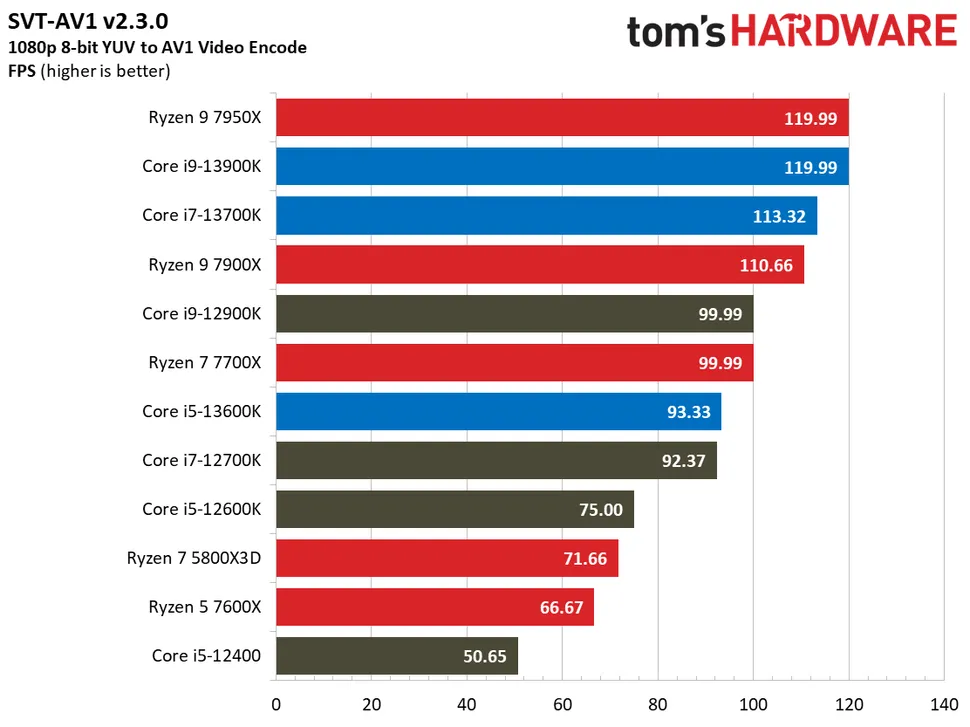
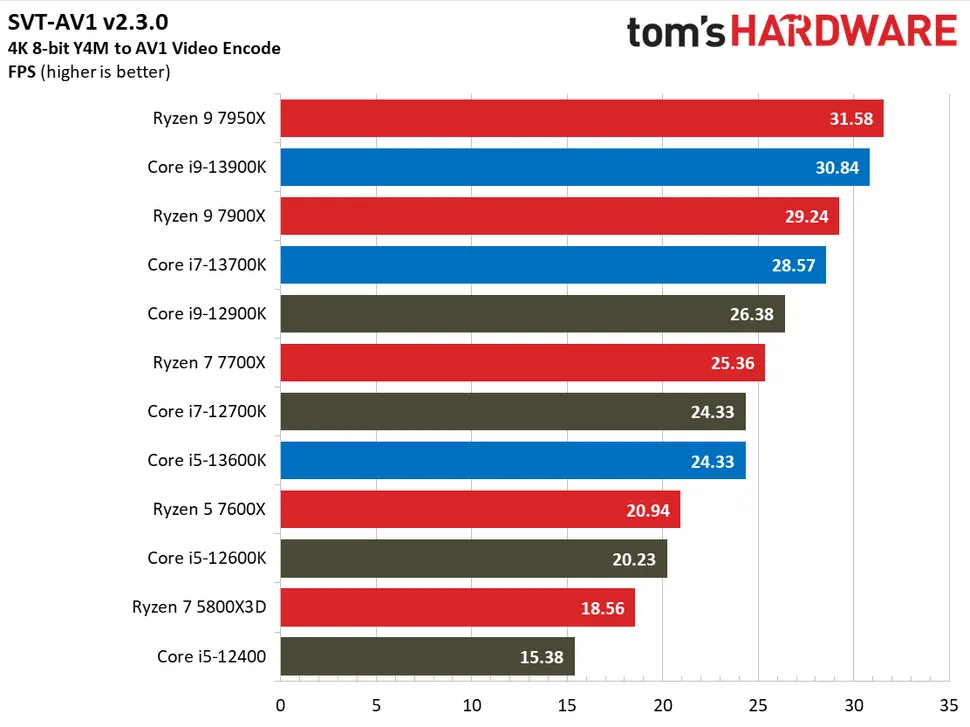
- Oct 9, 2022
- 525
- 179
- 86
I mean the Ryzen 7700X is an 8 core CPU and Ryzen 7600X is a 6 core CPU. And the 7700X is $399 and 7600X is $299.
Intel has the Core i7 13700K priced at $399 and Core i5 13600K priced at $399. And those CPUs have better P cores being 8 and 6 core counterparts with slightly better IPC than Zen 4 and can clock as high or higher with similar power usage. And for those who do not like e-cores (I am one of them, but I love Intel P cores) can disable them and you get better 6 and 8 core CPUs form Intel Raptor Lake than AMD Ryzen. And for those who want e-cores you get then as well for the same price and better P cores of equal core counts.
SO what is AMD thinking and they still have not budged on the prices of the 7600X and 7700X. They are pricing the like their 6 and 8 Zen 4 cores are better than Intel's Raptor Cove cores of equal count even though they are not any better and in fact not as good?? Or is that debatable??
The Ryzen 7900X and 7950X prices make more sense as then you get more than 8 strong cores and AMD has those by the balls who want more than 8 cores and do nit want to go hybrid route. SO yeah 7900X and 7950X prices make sense.
But 7600X and 7700X are almost a ripoff unless you just have not have AMD as they do nothing better than 13600K and 13700K for exact same price and have slightly weaker P cores and no additional e-cores for those that like the e-core options (And for those that do not it is easy peasy to disable and you get the better 6 and 8 core chips for the same price)
Its puzzling to me AMD is behaving as if they are still superior in all ways like they were with Ryzen 5000 from November 2020 to November 2021 when Intel was of no competition on core count nor per core IPC performance which was only for 1 year. I mean AMD is still much smaller and was underdog for years and hard to believe they think they can act they are premium brand in the 6 and 8 core CPU segment when the 7600X and 7700X are worse than Intel counterparts even with the e-cores off.
Your thoughts
Intel has the Core i7 13700K priced at $399 and Core i5 13600K priced at $399. And those CPUs have better P cores being 8 and 6 core counterparts with slightly better IPC than Zen 4 and can clock as high or higher with similar power usage. And for those who do not like e-cores (I am one of them, but I love Intel P cores) can disable them and you get better 6 and 8 core CPUs form Intel Raptor Lake than AMD Ryzen. And for those who want e-cores you get then as well for the same price and better P cores of equal core counts.
SO what is AMD thinking and they still have not budged on the prices of the 7600X and 7700X. They are pricing the like their 6 and 8 Zen 4 cores are better than Intel's Raptor Cove cores of equal count even though they are not any better and in fact not as good?? Or is that debatable??
The Ryzen 7900X and 7950X prices make more sense as then you get more than 8 strong cores and AMD has those by the balls who want more than 8 cores and do nit want to go hybrid route. SO yeah 7900X and 7950X prices make sense.
But 7600X and 7700X are almost a ripoff unless you just have not have AMD as they do nothing better than 13600K and 13700K for exact same price and have slightly weaker P cores and no additional e-cores for those that like the e-core options (And for those that do not it is easy peasy to disable and you get the better 6 and 8 core chips for the same price)
Its puzzling to me AMD is behaving as if they are still superior in all ways like they were with Ryzen 5000 from November 2020 to November 2021 when Intel was of no competition on core count nor per core IPC performance which was only for 1 year. I mean AMD is still much smaller and was underdog for years and hard to believe they think they can act they are premium brand in the 6 and 8 core CPU segment when the 7600X and 7700X are worse than Intel counterparts even with the e-cores off.
Your thoughts