
Fudzilla: Bulldozer performance figures are in
Page 69 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
- Status
- Not open for further replies.
Opteron launched at what? 1.6GHz?
1.4 to 2.2 ghz at a 130nm node, but it did reach 3.2ghz on 90nm....
http://en.wikipedia.org/wiki/Opteron
Last edited:
Dresdenboy
Golden Member
Launch clock frequencies were 1.4 to 1.8 GHzOpteron launched at what? 1.6GHz?
Davidh373
Platinum Member
- Jun 20, 2009
- 2,428
- 0
- 71
http://www.megagames.com/news/amd-benchmarks-bulldozer-against-intel%E2%80%99s-core-i5-and-i7
hmm... so they can barely make it look better in their rigged up press release junkits... yikes
hmm... so they can barely make it look better in their rigged up press release junkits... yikes
NostaSeronx
Diamond Member
- Sep 18, 2011
- 3,811
- 1,290
- 136
http://www.megagames.com/news/amd-benchmarks-bulldozer-against-intel%E2%80%99s-core-i5-and-i7
hmm... so they can barely make it look better in their rigged up press release junkits... yikes
h264 and x264 on "SD" if I assume its 360p the more cores you have the more negative scaling you have
unspecified i5 4 core? with defaults = 4 x 1.5 = 6 threads
Unknown assumed FX 8 core with defaults = 8 x 1.5 = 12 threads
So with the negative scaling with "SD" resolutions it's still faster
In HD workloads we should see the FX 8 cores provide more performance than the i5 4 cores
But that is to be seen
and on the gaming demo I call GPUs and Drivers
Last edited:
The gaming demo is most certainly gpu bottlenecked and the two differing fps ratings likely within the margin of error and statistically insignificant.
You don't benchmark processors with high resolution gpu limited scenarios. Everything above a specific baseline of performance will have almost equal fps values. We all know this.
You don't benchmark processors with high resolution gpu limited scenarios. Everything above a specific baseline of performance will have almost equal fps values. We all know this.
Last edited:
soccerballtux
Lifer
- Dec 30, 2004
- 12,553
- 2
- 76
NostaSeronx
Diamond Member
- Sep 18, 2011
- 3,811
- 1,290
- 136
http://www.ibuypower.com/Info/amd-bulldozer.aspx
Not sure if I should place this in here but oh well
Not sure if I should place this in here but oh well
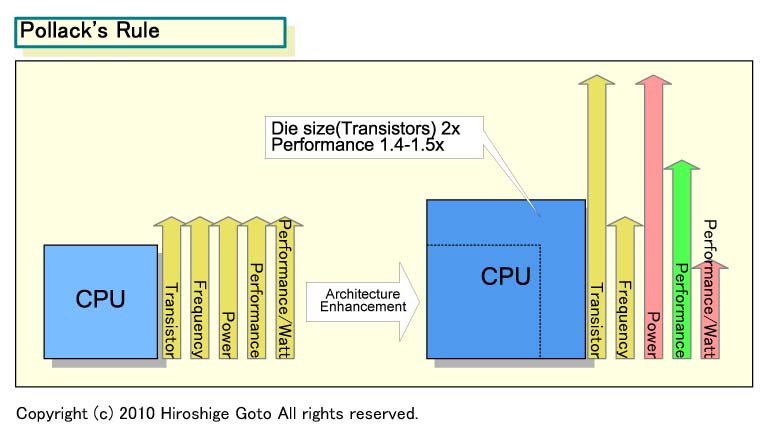
I am doubtful that these 256-bit FPUs are going to magically make the IPC much higher.
There's no magic involved, unless they magically made IPC/Watt increase, but increasing IPC in and of itself by going to 256-bit FPU's would be expected to follow the envelope captured by Pollack's Rule.
videoclone
Golden Member
- Jun 5, 2003
- 1,465
- 0
- 0
This is a shame my hopes were with bulldozer being the new king but..
AMD increased the Instruction pipeline of the NEW Bulldozer cpu much like Intel did with the Pentium 4.
This is the single worst thing they could have done and this is the reason why bulldozer is falling short of expectations, (from leeked benches of ES ) is slower then their 2 years old 6 core CPU's and is also why AMD's CEO got fired for letting this happen.
This longer pipeline nullified the improvements to the CPU much like Intel's Pentium 4, Every Mhz was worth less no amount of cache or improvement to the design could fix that. Until Intel canned the longer stage pipeline for a more efficient Pentium Pro approach with core series processor's and the rest is history.
Just my thoughts.
AMD increased the Instruction pipeline of the NEW Bulldozer cpu much like Intel did with the Pentium 4.
This is the single worst thing they could have done and this is the reason why bulldozer is falling short of expectations, (from leeked benches of ES ) is slower then their 2 years old 6 core CPU's and is also why AMD's CEO got fired for letting this happen.
This longer pipeline nullified the improvements to the CPU much like Intel's Pentium 4, Every Mhz was worth less no amount of cache or improvement to the design could fix that. Until Intel canned the longer stage pipeline for a more efficient Pentium Pro approach with core series processor's and the rest is history.
Just my thoughts.
Last edited:
This is a shame my hopes were with bulldozer being the new king but..
AMD increased the Instruction pipeline of the NEW Bulldozer cpu much like Intel did with the Pentium 4.
This is the single worst thing they could have done and this is the reason why bulldozer is falling short of expectations, (from leeked benches of ES ) is slower then their 2 years old 6 core CPU's and is also why AMD's CEO got fired for letting this happen.
This longer pipeline nullified the improvements to the CPU much like Intel's Pentium 4, Every Mhz was worth less no amount of cache or improvement to the design could fix that. Until Intel canned the longer stage pipeline for a more efficient Pentium Pro approach with core series processor's and the rest is history.
Just my thoughts.
Bulldozer pipeline is alot more to K8 and CoreDuo then it is to P4 prescott.. Alot of thought went into the pipeline design length and experiments have shown what seems to give the best performance... this is how they designed BD. If performance is lacking it would be more due to the things they have left out for the initial design.
(note: about all the bad about p4, northewood was one of the best cpu's for its time...)
Last edited:
Bulldozer pipeline is alot more to K8 and CoreDuo then it is to P4 prescott.. Alot of thought went into the pipeline design length and experiments have shown what seems to give the best performance... this is how they designed BD. If performance is lacking is would be more due to the things they have left out for the initial design.
(note: about all the bad about p4, northewood was one of the best cpu's for its time...)
Indeed , BD has 30% at least more brute computing capability
than a SB 4C/8T , that early "leaks" doesnt say so is just
another story...
Lonbjerg
Diamond Member
- Dec 6, 2009
- 4,419
- 0
- 0
Indeed , BD has 30% at least more brute computing capability
than a SB 4C/8T , that early "leaks" doesnt say so is just
another story...
If you are trying to pass AMD's IGP of as "brute" I have to do a ROFL
ROFL at yourself since your post is a self evidence that youIf you are trying to pass AMD's IGP of as "brute" I have to do a ROFL
dont know what id debated...
Has ever BD included an IGP ??..:biggrin:
Imouto
Golden Member
- Jul 6, 2011
- 1,241
- 2
- 81
Most of x264 benches in hardware reviews are so incredibility retarded that it makes me even laugh. x264 threads must always match CPU threads, be done with HD content and seriously 2nd pass is not needed anymore, going CRF should give a more accurate x264 performance for each piece of hardware.
Also, using retarded programs to transcode isn't giving any clue of real performance, there's a lot of software out in the wild that performs a way better than the used in hardware reviews.
Also, using retarded programs to transcode isn't giving any clue of real performance, there's a lot of software out in the wild that performs a way better than the used in hardware reviews.
Cogman
Lifer
- Sep 19, 2000
- 10,286
- 145
- 106
Most of x264 benches in hardware reviews are so incredibility retarded that it makes me even laugh. x264 threads must always match CPU threads, be done with HD content and seriously 2nd pass is not needed anymore, going CRF should give a more accurate x264 performance for each piece of hardware.
Also, using retarded programs to transcode isn't giving any clue of real performance, there's a lot of software out in the wild that performs a way better than the used in hardware reviews.
1. X264 does not match the number of threads used with the number of cores in a CPU. Last I checked, it was something like 3/2 the number of cores.
2. 2nd pass is used to hit a specific bitrate. This is important when trying to hit a specific size for a transcode.
3. 2nd pass and CRF use essentially the same code path. The only difference being that CRF does slightly more calculations.
4. X264 is THE BEST encoder available. When looking at quality/speed it wins everytime, hands down. It has the ability to compete in speed with most of the faster encoders out there (what do you think all of its settings are for?).
x264 is FAR from a retarded encoder. Using it as a benchmark makes sense, the developers have gone to great measures to make sure it uses the fastest and right instructions for a given platform for a given operation.
Imouto
Golden Member
- Jul 6, 2011
- 1,241
- 2
- 81
1. That's why you should manually input it.
2. Is this needed anymore?
3. Almost 100% of encodes are done in CRF mode.
4. Have I said otherwise?
Learn to read. I was refering to transcoders like MediaShow Expresso and similars not x264. x264 is indeed an awesome encoder.
2. Is this needed anymore?
3. Almost 100% of encodes are done in CRF mode.
4. Have I said otherwise?
Learn to read. I was refering to transcoders like MediaShow Expresso and similars not x264. x264 is indeed an awesome encoder.
Nemesis 1
Lifer
- Dec 30, 2006
- 11,366
- 2
- 0
No one cares about cores vs cores, we care about price vs price. You really cant admit thats fantastic performance given the fact its clocked 600 MHz lower than it normally would be and the fact that it costs the same as the 2600K?
So how is that working for AMD . Did they capture 80% of the market with cheap CPUs . You used the word we, Impling your a majority . Price considerations for me don't enter into the small picture you paint , A couple of hundred dollars means nothing to me at all .
Since this earlier hype has anything changed or are you still hyping an unknown products performance . Time to make more charts for the internet . LOL!
Cogman
Lifer
- Sep 19, 2000
- 10,286
- 145
- 106
No, you shouldn't. The x264 developers actually know what the hell they are doing, but they give you the option to screw things up if you like. They grab the number of threads that yields the highest FPS not the most CPU utilization or some other stupid metric. They are shooting for fastest encoding times possible.1. That's why you should manually input it.
Absolutely it is. People target CDs, DVDs, and other mobile media ALL the time. Hell, when people want to broadcast something over the internet, it is nice to be able to determine, before hand, how much bandwidth your transmission will take.2. Is this needed anymore?
Almost 100% of encodes done by enthusiasts... encodes done by professionals with tight constraints on filesizes, bandwidth requirements, etc will use different modes quite frequently. That is why they are still there. And even then, that doesn't address the fact that, as I said earlier, CRF uses almost exactly the same code path as 2 pass (being only slightly slower).3. Almost 100% of encodes are done in CRF mode.
How was I supposed to know what you are referring to? Your post was about x264, you never mentioned other encoders. In context, what you said looked VERY much like you were trying to put down x264.4. Have I said otherwise?
Learn to read. I was refering to transcoders like MediaShow Expresso and similars not x264. x264 is indeed an awesome encoder.
Imouto
Golden Member
- Jul 6, 2011
- 1,241
- 2
- 81
No, you shouldn't. The x264 developers actually know what the hell they are doing, but they give you the option to screw things up if you like. They grab the number of threads that yields the highest FPS not the most CPU utilization or some other stupid metric. They are shooting for fastest encoding times possible.
They implemented even presets for casual users and that's a way to use it but not the best. Aside that the more threads you add the more quality losses. Again, presets (like going 1.3x threads per logical/phys core) are meant for casual users and the best on average but not when you know what to do. It might be the best for the average out there but not for every single CPU.
Absolutely it is. People target CDs, DVDs, and other mobile media ALL the time. Hell, when people want to broadcast something over the internet, it is nice to be able to determine, before hand, how much bandwidth your transmission will take.
And you get the terrible quality encodes you see every day. Thanks TFSM more and more anime and american shows encoders are going CRF instead of trying to bump x chapters in x media.
Almost 100% of encodes done by enthusiasts... encodes done by professionals with tight constraints on filesizes, bandwidth requirements, etc will use different modes quite frequently. That is why they are still there. And even then, that doesn't address the fact that, as I said earlier, CRF uses almost exactly the same code path as 2 pass (being only slightly slower).
No objection here. Sorry if I was talking while having my encodefag chip turned on.
How was I supposed to know what you are referring to? Your post was about x264, you never mentioned other encoders. In context, what you said looked VERY much like you were trying to put down x264.
It was on a different paragraph, and I refered to transcoders, not encoders. Sorry if I wasn't clear enough.
looncraz
Senior member
- Sep 12, 2011
- 722
- 1,651
- 136
AMD increased the Instruction pipeline of the NEW Bulldozer cpu much like Intel did with the Pentium 4.
I largely agree with you, but we have to consider what Netburst is in comparison to Bulldozer. (or invert that...)
Netburst had up to 31 stages in its pipelines. Bulldozer is believed to be about 18 stages. BIG difference. From the 11/12 stage pipelines now, that is 50% more, still...
Now, however, we have to read into delays on each stage of those pipelines. Certain material I've read has indicated that the integer FO4 stage delays were reduced by 20%, helping to negate the pipeline length costs considerably. Not each stage of the pipeline is equal, and the 20% FO4 reduction is said to keep IPC constant.
So, the pipeline length issue may have been largely negated.
Now, each integer core in Bulldozer can also do 4uops cycle, a 33% improvement over phenom II which could only do 3 uops/cycle.
Now, from that, we have to consider the highly aggressive front-end, which should help to limit stalls by good 20% more than phenom II's and help reduce the costs for missed predictions DRAMATICALLY.
Now, we have to look at the cache:
Starting from an improvement of 33%, mind you...
(module view)
Item: 1 thread / 2 thread's maxed
Shared L1I: 0%/-2%
Small L1D: -1%/+2%
Write-Through: - 2%/-3%
Shared L2: +3%/+5%
(note: higher latency costs in single-thread exec
2MB means the data is most likely there)
Write Coalescing Cache: +1%/+2%
Shared L3: +2%/+3%
EVERYTHING about Bulldozer says.. I'm going FASTER.
However, there is ONE **MAJOR** issue I can see with the module design and the power management features that we've actually already seen in a past AMD design: the original Phenom.
The problem was that of differing clock speeds per core and Windows scheduling. This problem was NEVER resolved. Even today, you can use k10stat to enable per-core CPU clocking and be amused as Windows shuffles fast-thread onto idling, but down-clocked, cores only to then watch as the system delayed in bringing that core's clock back up just before Windows cycled the thread off once again.
Windows does this for a number of good reasons:
1. Load balancing
2. Next-available-core scheduling method is only O(1) complex.
Module overhead further complicates the matter, with performance-mode requiring to put one thread per module until they are loaded, and energy-saver trying to stay on as few modules as possible.
Microsoft/AMD, I'm certain, will be releasing a patch/driver for the issue.
Disabling Cool-n-Quiet and overclocking should resolve the issue SOME, but not entirely as you still have module contention not being considered (20% overhead is something you MUST consider!).
That overhead, BTW, comes mostly from the front-end - something I'm sure will be improved upon with Pile-driver.
Now, one final note:
The shared L1I design and the small L1D (mostly inclusive) indicates to me a desire to use BOTH integer cores to execute a single thread. If not now, then certainly in the future. There is NO other reason I can see for this L1 design except that.. which doesn't mean there isn't another reason...
Just imagine, when one complete module is put to one thread, you have eight integer pipelines, 4x ALUs, 4x AGUs, 32KB L1d, 64KB L1I, 256-bit FPU w/ FMAC capable of doing 8 ops concurrently!! Wait, suddenly we see a symmetry: 8 integer uops and 8 float uops per cycle, halving the L1d cache from phenom II and making it (mostly) inclusive means you can quickly execute an extra thread when called upon to do so.
Damn, AMD, do you see in your hardware what I see?? I'm betting (and hoping) so!! Good times ahead, indeed!
--The loon
podspi
Golden Member
- Jan 11, 2011
- 1,982
- 102
- 106
I don't know about the X4s, but the X6 clocks each core independently as well, and there is no visible lag that I can detect while using the machine.
For things like encoding, etc, any transient lag isn't very important, since the cores are fully utilized and thus are at their highest sustainable p-state.
For things like encoding, etc, any transient lag isn't very important, since the cores are fully utilized and thus are at their highest sustainable p-state.
looncraz
Senior member
- Sep 12, 2011
- 722
- 1,651
- 136
I don't know about the X4s, but the X6 clocks each core independently as well, and there is no visible lag that I can detect while using the machine.
For things like encoding, etc, any transient lag isn't very important, since the cores are fully utilized and thus are at their highest sustainable p-state.
The X6 may turbo boost one core, and the Windows shuffles the thread to another core and minimizes the added performance a bit before the system catches up to boost the correct core. This would be virtually impossible to benchmark.
No, what I'm talking about is a behavior that is not default in phenom II, but was in phenom I. Some cores at 800mhz, active core at full-speed. A ~2GHz+ difference can have a huge effect on average performance.
The WinNT kernel is a pre-emptive multi-threaded SMP kernel that employs lazy load balancing(good), is socket aware(good), and supports process affinity(good).
The bad comes from the SMP part: Windows ASSUMES all cores are equal, and treats them that way.
When the kernel preempts a thread, there is no guarantee that thread will execute on the same core next time around. In most modern kernels, there will be some time delta at which we assume the CPU will no longer retain an data pertinent to the resuming thread and thus there will be no cost to schedule that thread to the least active core (for lazy load balancing). The problem comes from the delay of taking an idle core and putting its speed into full swing after a thread is scheduled to that core. On phenom, this takes about 500ms!! That is the time threshold of execution beyond a certain percentage of clocks prior to boosting to the next P-state. This is full-trip time, BTW (from idle to full-speed/turbo).
The P-state change itself is incredibly fast. k10stat can modify the thresholds and can actively monitor usage and set them to whatever you desire.
The phenom II clocks the whole CPU to the same P-state by default to remedy this issue. Turbo mode likely has faster reaction times, and the difference is smaller.
On Bulldozer, the issue is not just with the large turbo boost (big differences again...but probably very low threshold) and Cool-n-Quiet, but also with the overhead in each module.
Now, Windows will be shuffling threads around onto the least-used core which may be in the same module as the most-used core resulting in a 10% downgrade in performance for BOTH cores - and possibly an extra "penalty" from the loss of thermal efficiency and, thereby, turbo-boost.
This could easily cost 20% performance loss from the ideal. One certain issue will be the iterative nature of thread scheduling:
Normal:
Thread 1->core 0
Thread 2->core 1
Thread 3->core 2
Thread 4->core 3
Best On Bulldozer:
Thread 1->core 0/1
Thread 2->core 2/2
Thread 3->core 4/5
Thread 4->core 6/7
Indeed, it would be best if Windows was aware of the least loaded module and used that one instead of the least loaded core, but that would have a much lesser effect and the added scheduling complexity may mean it is not worthwhile.
Losing 20% or so in performance simply due to this is easily understandable - which is why Microsoft decided that CPUs needed drivers too - and likely why AMD's/Microsoft's software team may be holding up release and holding back performance...
--The loon
- Status
- Not open for further replies.
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 22K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 23K
-

-
 News NVIDIA and Intel to Develop AI Infrastructure and Personal Computing Products
News NVIDIA and Intel to Develop AI Infrastructure and Personal Computing Products- Started by poke01
- Replies: 411
AnandTech is part of Future plc, an international media group and leading digital publisher. Visit our corporate site.
© Future Publishing Limited Quay House, The Ambury, Bath BA1 1UA. All rights reserved. England and Wales company registration number 2008885.