Intel and nVidia can force the order from threads generated by the rasterizer, guaranteeing the triangle-order from the rasterizer, and then having a sort of ‘critical section’ inside a pixel-shader to make sure that the per-pixel operations of each triangle are performed in-order as well.
If the rasterizer does not ‘know’ about ROV, then it may try to be smart and triangles might ‘overtake’ eachother. For example, say triangles 0-4 are queued on one cluster, where triangles 5-8 are queued on another… or if triangles 0, 2, 4 etc are queued on one cluster and triangles 1, 3, 5 etc are queued on another, and triangles 0, 2, 4 take longer to render than 1, 3, 5… many kinds of scenarios where triangle order can not be solved by just a critical section inside the shader.
If this is possible with GCN/Mantle, I’d like to have some detailed code explaining how to set up both the rasterizer and the pixel shaders for that. And then we can see how efficient that will be. The most naive solution would just serialize all triangles, making it extremely slow. The critical section part is what makes it very efficient, since it only slows down when there is actual overlap of pixels.
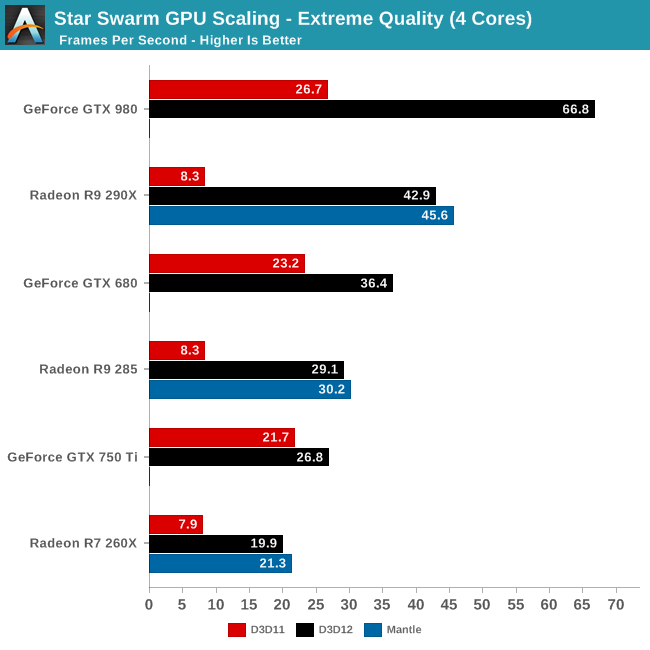
First test:

")