Gideon
Platinum Member
With all the upcoming ARM servers (Let's not forget Nuvia, etc) it probably makes sense to have 1 thread from them all, instead of creating new ones for each announcement (if Not, I will rename it).
However:
Anandtech: Marwell Announces 3rd Gen Arm Server Thunder X3: 96 Cores/384 threads
ServeTheHome: Marvell ThunderX3 Arm Server CPU with 768 Threads in 2020
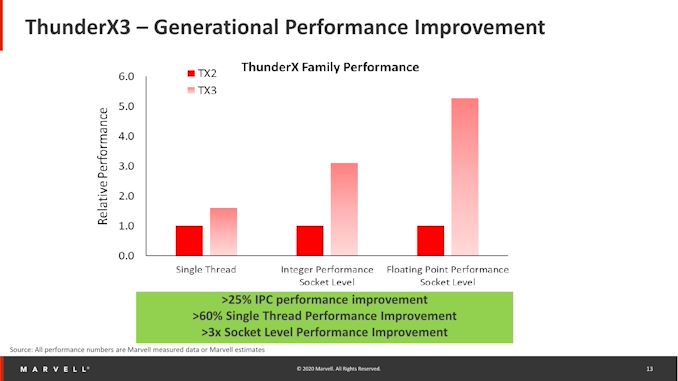
Could be pretty impressive, though 25% Single Threaded performance gain seems a bit meh, compared to X2, which @2.5Ghz was ~50% slower than Xeon @ 3.8Ghz
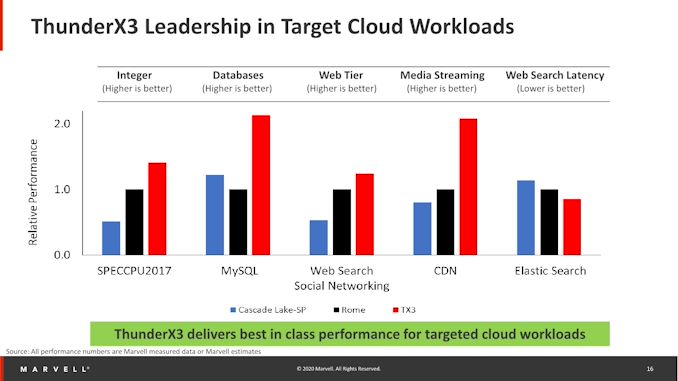
But Their marketing slides sure show potential:
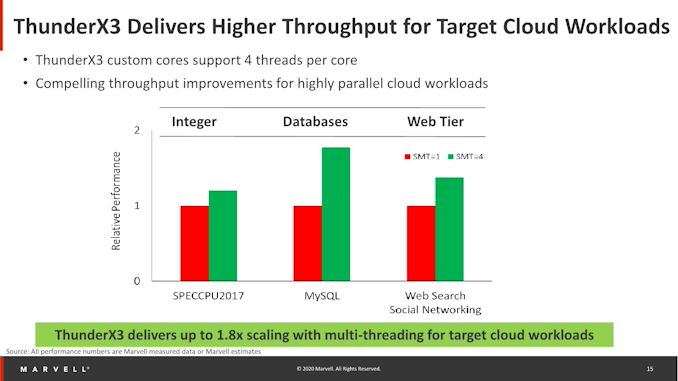
However:
Anandtech: Marwell Announces 3rd Gen Arm Server Thunder X3: 96 Cores/384 threads
ServeTheHome: Marvell ThunderX3 Arm Server CPU with 768 Threads in 2020
Could be pretty impressive, though 25% Single Threaded performance gain seems a bit meh, compared to X2, which @2.5Ghz was ~50% slower than Xeon @ 3.8Ghz
But Their marketing slides sure show potential:
Last edited: