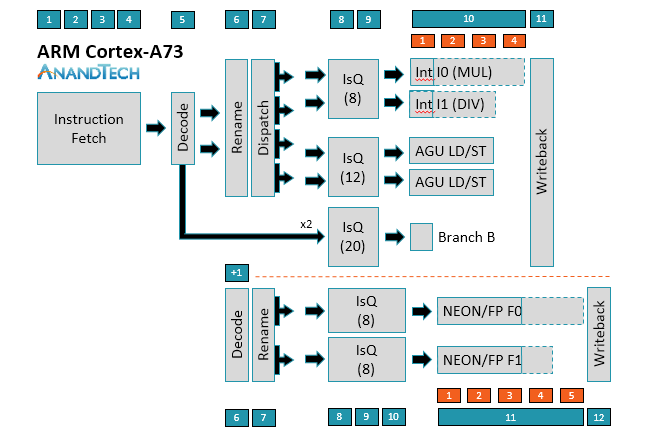
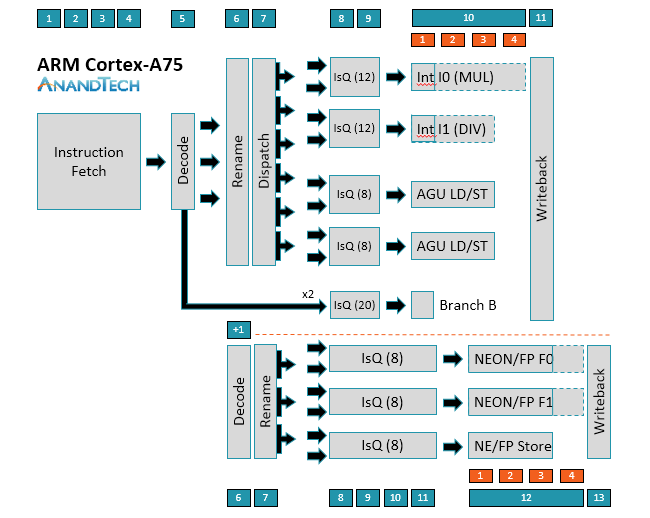
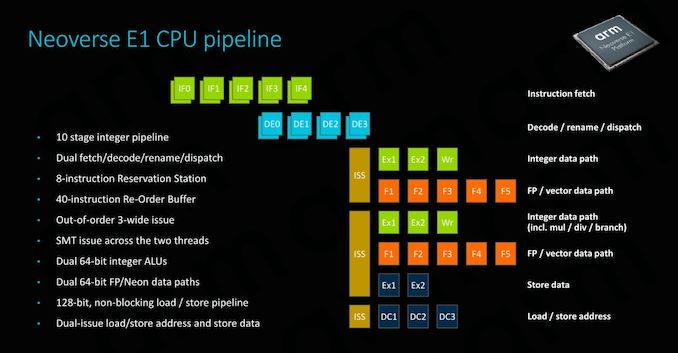
Oh I didn't know Apple made that chip.
. . .
heh.
In all seriousness though, can you even buy time on a Graviton2 instance yet? I thought they were doing test runs by invitation only.
The point was to demonstrate the vapidity of the claim "What nobody seems to get, or understand, is that Apple and ARM AT THE MOMENT seems to be very strong in single core, non IO dependent benchmarks."
(a) ARM is in that claim. ARM of course provides the cores for Graviton (and most of the other ARMv8 server SoC's)...
(b) Just like EVERY DAMN STEP OF THIS PROCESS, the x86 crowd keep insisting that there's some magic ingredient in x86 cores that no-one else can reproduce. At first it was IPC, till Apple beat that. Then it was absolute performance, till Apple matched that. Then it was total throughput/memory bandwidth/IO, till Graviton 2 has matched that.
When will you get it through your heads that there is no magic there?!? The only core competency of x86 SoCs is executing x86 code. If Amazon or Marvell are capable of creating a SoC with many attached memory controllers, lots of PCIe lanes, and plenty of cores, believe me, Apple is capable of doing the exact same thing -- IF they have a reason to do so.
For some of you the game might be "x86 uber alles", but for the rest of us, we're just sick of seeing the forums polluted by the massive ignorance. You have people who don't have a clue about Marvell (high thread count), don't have a clue about Ampere (dual socket support), don't have a clue about Apple (extremely high IPC), don't have a clue about Amazon (commercial performance/dollar advantage) making these grand statements about a world of which they know not a damn thing.
I mean, christ, how can you be making claims about how "ARM has lousy support for large SoCs running substantial IO and memory footprints" if you're not even following what AWS is doing? WTF are you basing your claims on if you refuse to even track the single most obvious (but not the only) example of ARM being used for precisely those tasks???
There ARE true, negative, statements about ARM that can be made -- like, right now, there are some fundamental libraries (eg bignum or crypto) that have not had nearly the optimization put into them that x86 has seen. How about in future we stick to claims like that that rather than wild fantasies about "I have no idea how one might design a SoC with a high PCIe lane count, therefore, obviously, Apple similarly has no idea"?