- May 15, 2014
- 559
- 293
- 136
How much is the Samsung 7nm EUV process expected to provide in terms of gains?
How will the RTX components be scaled/developed?
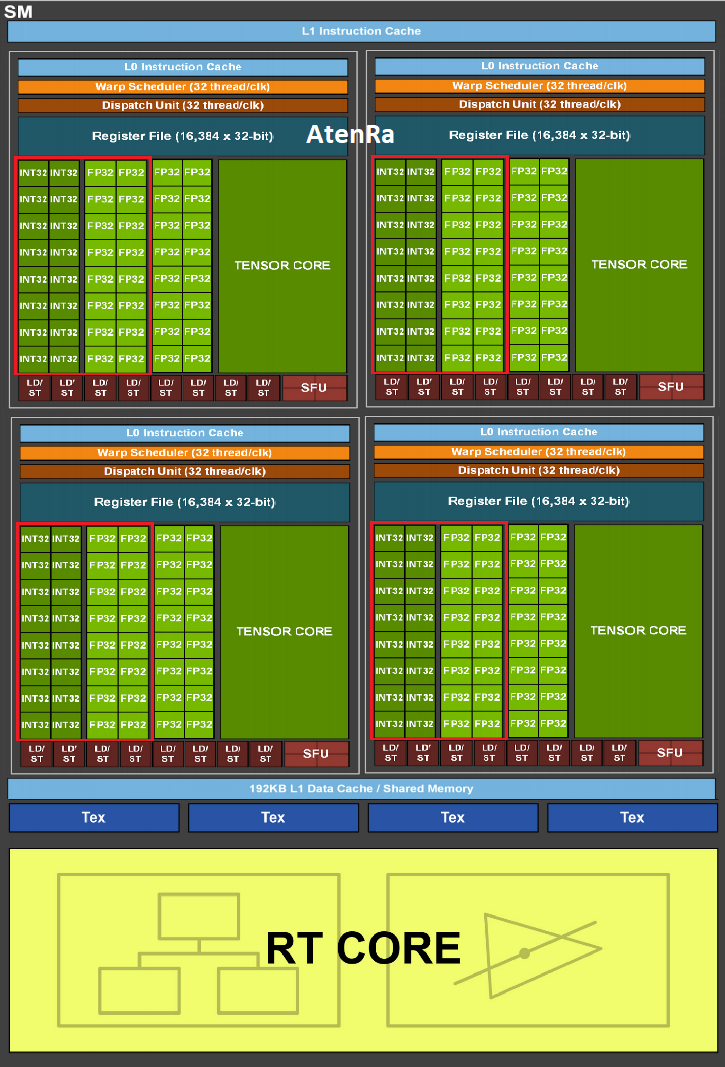
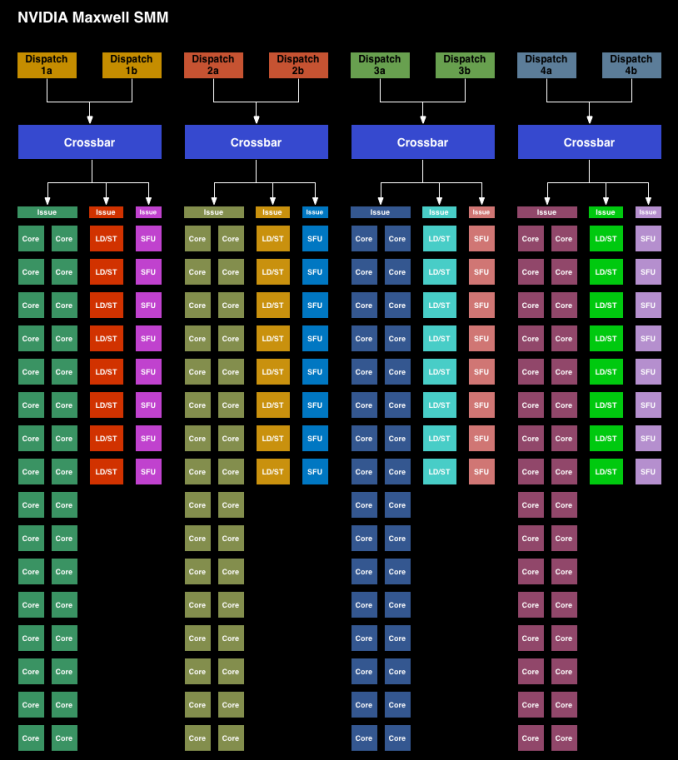
Any major architectural enhancements expected?
Will VRAM be bumped to 16/12/12 for the top three?
Will there be further fragmentation in the lineup? (Keeping turing at cheaper prices, while offering 'beefed up RTX' options at the top?)
Will the top card be capable of >4K60, at least 90?
Would Nvidia ever consider an HBM implementation in the gaming lineup?
Will Nvidia introduce new proprietary technologies again?
Sorry if imprudent/uncalled for, just interested in the forum member's thoughts.
How will the RTX components be scaled/developed?
Any major architectural enhancements expected?
Will VRAM be bumped to 16/12/12 for the top three?
Will there be further fragmentation in the lineup? (Keeping turing at cheaper prices, while offering 'beefed up RTX' options at the top?)
Will the top card be capable of >4K60, at least 90?
Would Nvidia ever consider an HBM implementation in the gaming lineup?
Will Nvidia introduce new proprietary technologies again?
Sorry if imprudent/uncalled for, just interested in the forum member's thoughts.