The way I see it code with SMT yields higher than 50% would be poorly optimized loads. Theoretically if you have a thread that's so well optimized which never stalls on a given core it would keep that core 100% busy. In other words another hyper-thread may never get a chance to run on it. We can examine some code which has 0% SMT scaling to learn what kind of load that is. Likely highly repetitive code with no branch prediction or cache misses.
The theoretical limit for HT/SMT-2 scaling is 100% as no more than 2 threads (200% of # of threads) can run on Hyperthreading machines. This might be a fun exercise to produce such code. ^^
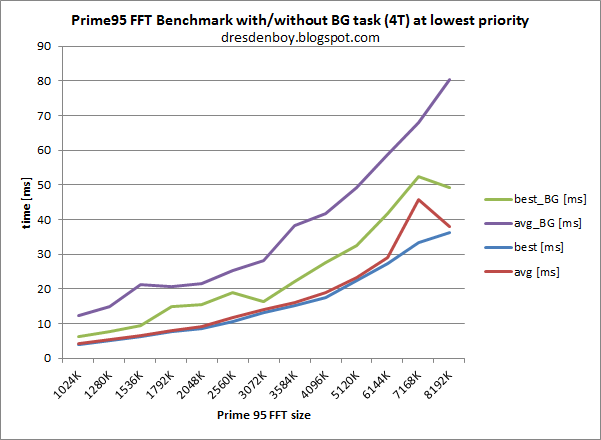
The other extreme you cite is a power virus - or close to that: Prime95, which I used. It got slowed down by nearly 50% thanks to the less prioritized threads sitting in the same core and occupying available resources. That's the thing with missing prioritization of Hyperthreads/logical cores. ATM I don't know , where this equalization happens, maybe already during fetch (in alternating cycles?). This is also, what BD did in the shared front end units. But this part is not SMT, but fine grained MT. So if instructions of the second thread enter the OoO section, the first thread can do nothing against it. Even not occupying the whole core (impossible) or just the AGUs for example wouldn't help, because this thread wouldn't get enough supply of instructions to continue playing this game.
"only one thread can execute at the same time with shared resources" What I mean by that is that while red boxes are for instance all competitively shared, given the nature of identical workloads in other threads they will all overlap on same instructions. Meaning they will be bottle necked in a same way. So either one thread can run or the other.. not two at the same time. They are competing for the time on the red boxes. So for both threads to get an equal share of execution there at least need to be 50% of time when one thread stalls, to give another thread an opportunity to run. And that would result in near 100% SMT scaling.
I see what you mean. But amongst the millions of instructions executed during one thread's timeslice, there are so many different types (simple ALU, IMUL, IDIV, AGU, loads, stores, FP SIMD, Int SIMD, FMUL, FADD, shuffle, etc.), that there always will be some room for other instructions. Especially with 8 or more execution units.
Ultimately in regards to Ryzen's single thread performance, I see Ryzen perhaps having 50% scaling as the worst case scenario. And of course in the best case scenario it could even have less than 40% scaling which would mean at least in Blender type workloads it could have a better single thread performance than Broadwell-E.
Agreed. The realistic range for SMT scaling is more like that. As often said, there will be ST code (like Blender with 1T), which might have even higher IPC on Zen, and there will be other code with lower IPC. That's natural for the wide variety of instruction mixes. 256b AVX will be enough to show a difference.
Higher clocks could increase the scaling. Because by OCing the CPU.. you're effectively increasing the mem fetch latency. Producing more opportunity for hyperthreading.
You are right. Increased mem fetch latency due to OC'ing is another factor.