Phynaz
Lifer
I originally did this vs the Ryzen baseline when it showed up, but decided to run some extra numbers.
Snip
Props dude, really nice!
I originally did this vs the Ryzen baseline when it showed up, but decided to run some extra numbers.
Snip
Interesting results here! The HT effect might be related to cache thrashing, partitioned core resources, fighting for sparse resources (which incl. cache and mem channels of course). Just fighting for an IDIV unit alone (if used at all) wouldn't cause such a significant drop.
Someone wondered about the string sorting. That test's lower mem dependency could come from cache blocking or easier to detect access patterns for prefetching, or both.
OTOH Passmark has a history of fiddling with IDIV. It's past CPU benchmark result measured the runtimes of loops with special instructions, one being IDIV. But it ran the same amount of instructions (IIRC) and created the score from the whole runtime. Now imagine 1 IDIV loop contributing maybe 80% of a benchmarks runtime if there is no HW divider. This way the per patch deactivated Llano HW divider got some attention.
http://www.passmark.com/forum/performancetest/3705-amd-llano-a-series-benchmark-and-cpu-bug
One problem here is, that those threads do exactly the same thing and need the same resources. This might simply end up in equal sharing.This could tell us that Ryzen's SMT doesn't do as good a job at managing the resources between the two threads.
Makes sense, Intel's years and years of work on SMT basically amounted to minimizing the performance regressions in certain cases.
They might have used better code/compilers for PT9. While browsing PM results I saw a significant drop in PN when going from Win32 to Win64.While the thread confirms that PN score is IDIV based, but should the Integer results not have poor results too? At least this thread seems to suggest it. And if it an error on AMD 12h CPUs, should it now have been fixed by now?
Branching should be fine on final silicon. The leaked "fake" CB screenshot might also be real, as the new leak suggests a similar result. AMD might kindly have asked the moderators to call it "fake". 😉 Or why would someone delete a photoshopped pic? 😎But I agree with you on the string sorting and the fight for cache. I also think it might be due to poor branching performance, like we saw in Flitz Chess
Then what was the aim of your post exactly? That if you ask for a mod operation and don't optimize you'll get a div instruction?My assembly code was from Intel compiler using MS disassembler. No optimization, as the code is too simple and the optimization will lead to constant as the results donot change with time.
Again the Atkin sieve does a mod by a compile-time know value, so it will be optimized.If you want you can use cin to let the user set the values and it should generate the assembly you want even with optimization.
Yeah I read the rest of the thread after answering you, and edited my post 🙂 Passmark looks like a very dumb and poorly implemented benchmark...^^ to find out if the compiler uses IDIV or some other fancy instruction? It seems Passmark confirmed it as well 🙂

Any specific workloads (must be available for Windows) you would like to see, besides the current ones?
Preferably open source, but that's not mandatory if the workload can otherwise be justified.
sm625 has gone missing. He unintentionally fuelled the hype train, trolled himself and set us all for a journey to infinity... and beyond 😀
i7 5820K @ 4.25GHz - No Turbo
DDR4 @ 3GHz Dual Channel

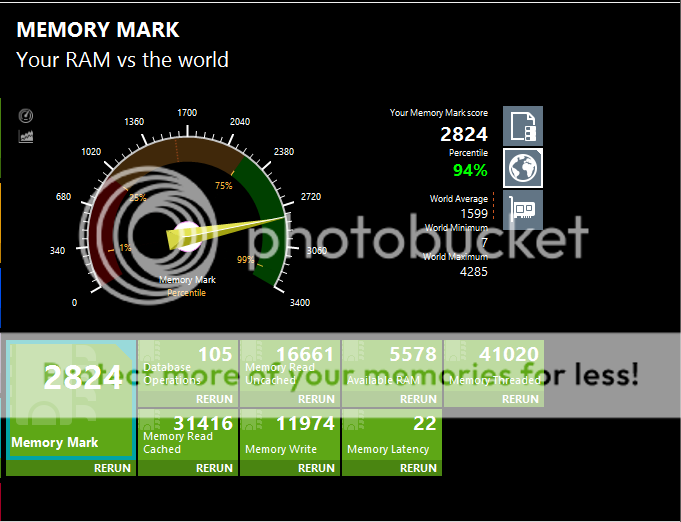
This is what is scary about Ryzen. Going from 4 channels to 2 channels drops your score from 3300 to 2800. So going to 1 channel would probably drop your score to .... 2200? Still higher than Ryzen. I dont suppose you'd be willing to test that?
How did they achieve to make Atkin sieve limited by modulo operations?!?
I'd like to see the FPS your CPUs get in NVidia's instancing benchmark, with instancing disabled. See this thread: https://forums.anandtech.com/threads/measuring-cpu-draw-call-performance.2498467/
Download link: http://developer.download.nvidia.com/SDK/9.5/Samples/DEMOS/Direct3D9/HLSL_Instancing.zip

I'd like to see the FPS your CPUs get in NVidia's instancing benchmark, with instancing disabled. See this thread: https://forums.anandtech.com/threads/measuring-cpu-draw-call-performance.2498467/
Download link: http://developer.download.nvidia.com/SDK/9.5/Samples/DEMOS/Direct3D9/HLSL_Instancing.zip
If dinos is saying this, the performance must be good. I'm a believer

Sent from HTC 10
(Opinions are own)
Who is Dino!? And like the commend underneath him.. I think many of us on 4c/4t Intel builds (2500K) from the last several years will be a prime target for a Ryzen upgrade.
Who is Dino!? And like the commend underneath him.. I think many of us on 4c/4t Intel builds (2500K) from the last several years will be a prime target for a Ryzen upgrade.
Ah ok so that makes sense that he may have some insight into Ryzen I suppose?He's a marketing guy at GIGABYTE.
Yea extreme OC since 2005 days on XS, but someone I personally have known... Even in the Phenom/Bulldozer extreme hype days, he was repeatedly attacked for calling them crap, pre-release. Doesn't mince his words.
Not saying its a SKL killer but it can't be bad with his comment.
Sent from HTC 10
(Opinions are own)
Ah ok so that makes sense that he may have some insight into Ryzen I suppose?
