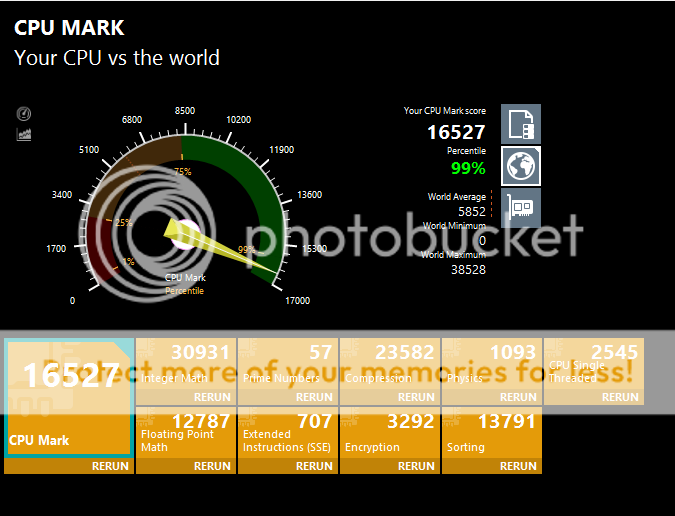
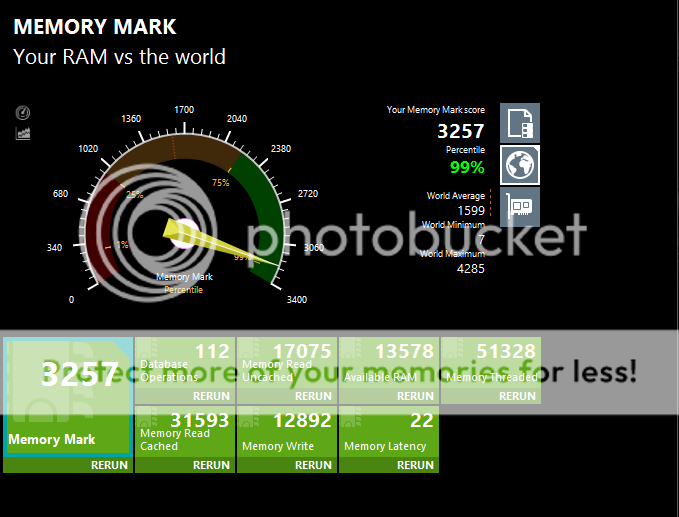
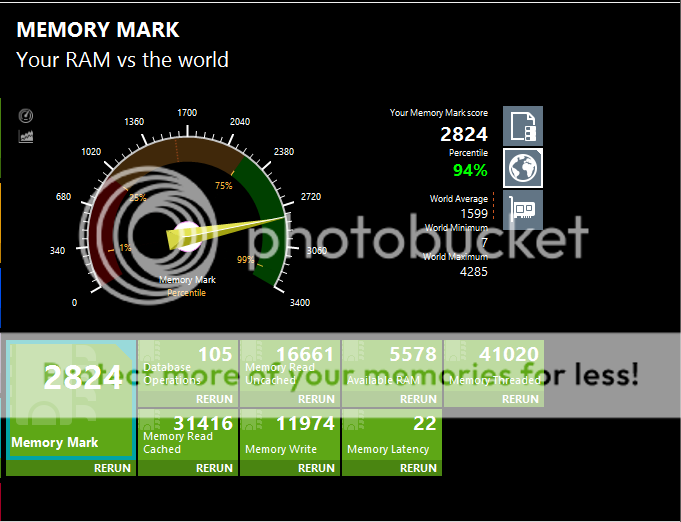
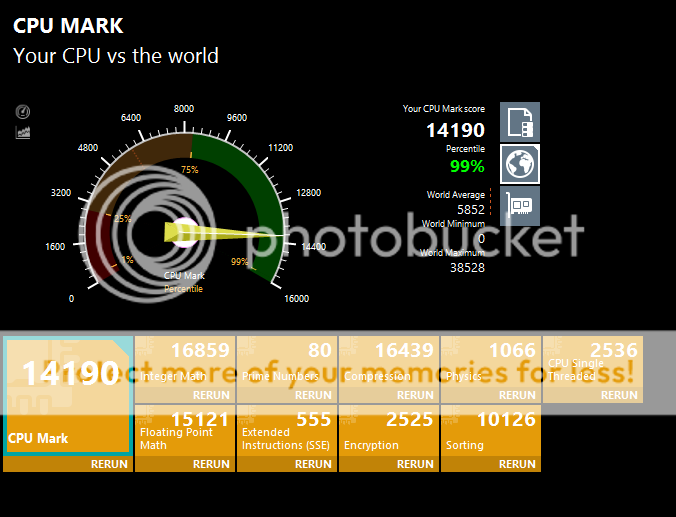
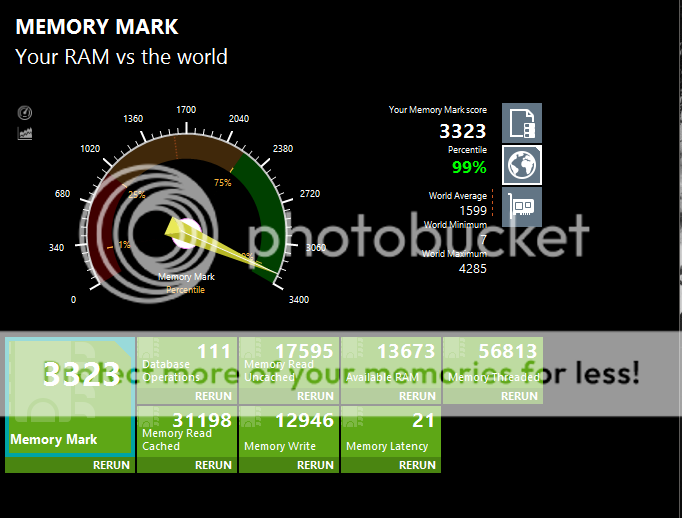
Looking at these, it becomes more and more obvious, how insanely good the Integer and Floating Point Math scores of Zen are @3.4/3.8

Even If we normalize them to per Ghz and core count,Ryzen is still:
Zen: (39672 / 3.4 / 8 = 1458.53; 14807 / 3.4 / 8 = 544.37)
HW: (30931 / 4.25 / 6 = 1212.98; 12787 / 4.25 / 6 = 501.45)
~=
16.8% faster in Integer performance per core vs Haswell
~=
7.9% faster in Floating Point performance vs Haswell
in
Highly Multithreaded scenarios.
Yet it still loses out in
Single Threaded performance:
Zen: 2046/3.8 ~=
538.42 (turbo working, as per the video)
HW: 2542/4.25 ~=
598.12 (no turbo presume?)
So it seems it's per-core scaling, at least in some applications, is better than any Intel product. I wonder what causes that?
Disclaimer: I know, it's only a single (and not that good to begin with) benchmark, but still
... CHOO CHOO!
😀