Fjodor2001
Diamond Member
Now you’re begging. 😉You can model it.
Now you’re begging. 😉You can model it.
I wish, already did the boring math eons ago.Now you’re begging. 😉
I already did it 2x eons ago.I wish, already did the boring math eons ago.
Now do the needful, kiddo.
Depends how many cores....there are many more numbers for cores for typical socket power consumption where this isn't true than where it is true..For MT and power constrained, better to have many cores at low frequency than few cores at high frequency. Optimal points on v/f curve and all that.
Moar cores are only good as long as the workload scales (obviously), and as long as your fabric overhead stays in check...Depends how many cores....there are many more numbers for cores for typical socket power consumption where this isn't true than where it is true..
It was a silly comment. Try to squeeze 1000 cores into the same power envelopes as above and the static power will kill the parallelismMoar cores are only good as long as the workload scales (obviously), and as long as your fabric overhead stays in check...
Timed Linux Kernel Compilation 6.8, allmodconfig
Core Ultra 9 285K (24c/24t, TSMC 3nm) + DDR5-8000: 581 s • 227 W = 132 kJ
Core Ultra 9 285K (24c/24t, TSMC 3nm) + DDR5-6400: 587 s • 224 W = 132 kJ
Core Ultra 5 245K (14c/14t, TSMC 3nm): 932 s (source; haven't found power figures)
Ryzen 9 9950X (16c/32t, TSMC 4nm) + DDR5-6000: 586 s • 193 W = 113 kJ
Ryzen 9 9900X (12c/24t, TSMC 4nm) + DDR5-6000: 741 s • 158 W = 117 kJ
Ryzen 7 9700X (8c/16t, TSMC 4nm) + DDR5-6000: 1178 s • 87 W = 102 kJ
Timed Linux Kernel Compilation 6.8, defconfig
Core Ultra 9 285K (24c/24t, TSMC 3nm) + DDR5-8000: 48 s • 157 W = 7.5 kJ
Core Ultra 9 285K (24c/24t, TSMC 3nm) + DDR5-6400: 48 s • 156 W = 7.5 kJ
Core Ultra 5 245K (14c/14t, TSMC 3nm) + DDR5-8000: 75 s • 94 W = 7.0 kJ
Core Ultra 5 245K (14c/14t, TSMC 3nm) + DDR5-6400: 74 s • 93 W = 6.9 kJ
Ryzen 9 9950X (16c/32t, TSMC 4nm) + DDR5-6000: 47 s • 155 W = 7.3 kJ
Ryzen 9 9900X (12c/24t, TSMC 4nm) + DDR5-6000: 58 s • 132 W = 7.7 kJ
Ryzen 7 9700X (8c/16t, TSMC 4nm) + DDR5-6000: 88 s • 79 W = 7.0 kJ
In other words, parallelism has got a task energy price tag attached. Still, time is money, therefore it's alright to spend that extra energy in reasonably parallelizable jobs, like this example = code compilation of a bigger source base.
(PS: Fabric overhead should show up less in Olympic Ridge.)
Nobody is talking about 1000 cores. It’s 52 cores max for next gen on regular DT.It was a silly comment. Try to squeeze 1000 cores into the same power envelopes as above and the static power will kill the parallelism
48 but Intel IP sucks.Nobody is talking about 1000 cores. It’s 54 cores max for next gen on regular DT.
What does that have to do with the 1000 cores comment?48 but Intel IP sucks.
Point being is core count is irrelevant when your IP sucks.What does that have to do with the 1000 cores comment?
So you missed post #7,874 on the previous page.Point being is core count is irrelevant when your IP sucks.
Bulldozer was 8 cores and that didn't quite do well.
It says Intel IP sucks? Yeah.So you missed post #7,874 on the previous page.
It says 285K has better perf/watt than 9950X in the ”available power per core” range we likely can expect for Zen6 and NVL-S top SKUs. So with that as base it’s likely the latter will have an MT perf advantage since the CPUs will be power contrainted.It says Intel IP sucks? Yeah.
What a waste of N3 and 2.5D slabs.
N3 vs N4p, organic carrier vs 2.5d slab.It says 285K has better perf/watt than 9950X in the ”available power per core” range
Wrong because Z6 gets a new 2.5D -LSI slab, mobile power mgmt and two nodes worth of juice.So with that as base it’s likely the latter will have an MT perf advantage since the CPUs will be power contrainted.
Come on man. I was responding to your statement that more cores is always more efficient for multi thread. I pointed out that actually that's not true, past a certain amount of cores static power gets in the way and you can barely do anything. A technical correction, sure. But clearly jovial. Come on, keep up 🙂Nobody is talking about 1000 cores. It’s 52 cores max for next gen on regular DT.
Not everyone remembers the slow progress of the 90's when Intel dominated because they weren't old enough to follow such things.So what is AMD to do with all those good CCD's? Only put them in 12C chips? There will be enough to go around for 24C chips to make that halo product.
Also you've said it before and here it is again. You're not the only one whose been around awhile. There are plenty of people here with a wealth of experience.
He did.Wait, I thought you kept saying that Zen 6 was N2P until you were blue in the face. Eating those words now?
... and it's just so easy (and fast) to change from one process to another mid product launch. Why even validate?See there's a majick trick being done here.
N2 and N2p are fully design rule compatible so early adopters like AMD tape out A0 on N2 and write the final stepping mask set on N2p.
Indeed.Optical shrink nodes are always design rule compatible. Why didn't everyone who designed on N3E do the same to get N3P wafers?
See belowNot going to happen. They will be pretty close in terms of performance.
The AMD cores will clock much higher than the Intel ones. Remember , the E cores aren’t designed to clock high to begin with, and the P cores aren’t designed power hungry.
AMD effectively has twice the amount of power per core available, SMT, and they have a more efficient core design.
Agree.For MT and power constrained, better to have many cores at low frequency than few cores at high frequency. Optimal points on v/f curve and all that.
That's a fair statement. Games will very likely be dominated by AMD with Zen 6 X3D, but why are we discussing games in the context of high core count processors?Again:
What kind of "MT" are we even talking about?
Mass-encoding/decoding videos?
CPU-crypto-mining by kids whose oblivious parents are footing the (power) bills?
Semi-professional workloads by people who would otherwise get a workstation CPU?
Games almost never have more than 6-12 heavy threads, and virtually all other consumer-relevant workloads usually aren't this demanding in the first place.
All that Intel will accomplish with NVL-52c will be to cannibalize some of AMD's (and their own) low-end workstation SKUs, and perhaps give a small demography of richer Intel shills an excuse to return to Intel because they're "first" in something again, no matter useless that something is for them 99.8% of the time.
That's about it.
100%. This is how I have it calculated as well.It says 285K has better perf/watt than 9950X in the ”available power per core” range we likely can expect for Zen6 and NVL-S top SKUs. So with that as base it’s likely the latter will have an MT perf advantage since the CPUs will be power contrainted.
Sure, perhaps it was phrased a bit too general, and of course there are limits to it like you said, so you are correct in that. The context was roughly the core count that was being discussed though. No worries, let’s move on. 🙂Come on man. I was responding to your statement that more cores is always more efficient for multi thread. I pointed out that actually that's not true, past a certain amount of cores static power gets in the way and you can barely do anything. A technical correction, sure. But clearly jovial. Come on, keep up 🙂
Yeah.... and it's just so easy (and fast) to change from one process to another mid product launch
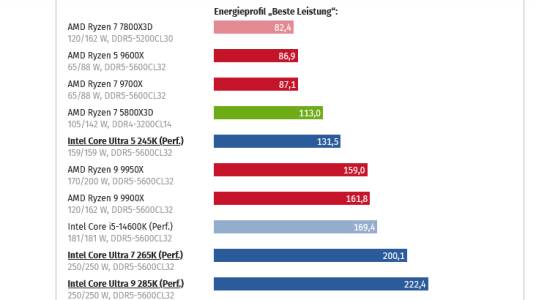
No, that's not what this post says. This post shows "TDP scaling (Cinebench 2024 MC)", plotted by Computerbase.[post #7,874 on the previous page] says 285K has better perf/watt than 9950X in the ”available power per core” range we likely can expect [...]
I have been wondering lately whether or not AMD will bother to improve their pipeline for old-school scalar FP in Zen 6 vs. Zen 5. Maybe they won't care about something like this, given all the Zen 6 goodies outside of microarchitectural updates (clocks, cache etc. pp.).I wish we could pin this article, because the thread is going in circles.
Cinebench is scalar SSE/scalar AVX spam, it cares little for vector execution, which is the weak point of Zen 5.
- All formerly 1-cycle latency SIMD instructions now have 2-cycle latency. Applies to all widths - including scalar.
It's the only TDP scaling MT benchmark test I've seen for 285K vs 9950X. If you know of any other TDP scaling tests for those CPUs but that uses other MT benchmark test suites please share.No, that's not what this post says. This post shows "TDP scaling (Cinebench 2024 MC)", plotted by Computerbase.
C i n e b e n c h
It's something quite special. Better not make general statements based on data like that.
Take Z6 dense, lobotomize caches, build it around 2-1 finpop and leakage-optimized floorplan and you get Z6LP.Are we expecting 2 or 4 of them, and what core type (e.g. down-clocked Zen 6C, with or without SMT)?
It's a shame how poorly journalists tend to treat the topic of performance-per-power even at default power levels, not to mention non-default ones. That said, perf/W at default power level is known well enough in a variety of workloads to know that Computerbase chose something unfortunately special for their plot.If you know of any other TDP scaling tests for those CPUs but that uses other MT benchmark test suites please share.
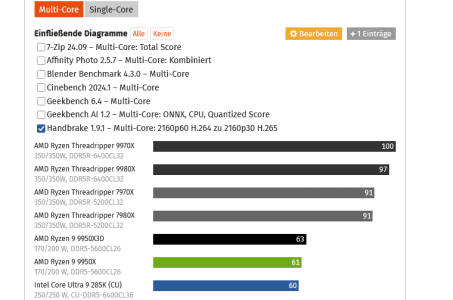
It the only one advertised because it s the exception that make Intel look good, at Computerbase they measured the 9950X Handbrake perf as being 2% better despite 28% lower power usage.Just wondering if anything is known about the Zen6 LPE cores?
Are we expecting 2 or 4 of them, and what core type (e.g. down-clocked Zen 6C, with or without SMT)?
Not sure if you responded to the correct post, because that does not seem to have anything to do with LPE cores.It the only one advertised because it s the exception that make Intel look good, at Computerbase they measured the 9950X Handbrake perf as being 2% better despite 28% lower power usage.