-
We’re currently investigating an issue related to the forum theme and styling that is impacting page layout and visual formatting. The problem has been identified, and we are actively working on a resolution. There is no impact to user data or functionality, this is strictly a front-end display issue. We’ll post an update once the fix has been deployed. Thanks for your patience while we get this sorted.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Question Zen 6 Speculation Thread
Page 263 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
okoroezenwa
Member
Pedantry Inc.Jeez, what these speculations threads are turning into
(moar cores per socket vs. memory capacity)
Let's undertake a thought experiment: We are a cloud service provider, i.e. our business is to rent out access to virtual machines. We are about to add 102,400 cores to our datacenter. How do we plan to do that? Will we add 400 sockets with 256 cores each, each of them with local memory attached? Or will we rather add 200 sockets with 512 cores and another 200 sockets with 0 cores (all of them with memory attached)?
I imagine that in this business, CXL attached memory will become attractive once it becomes possible at low price and low power consumption to attach memory nodes to more than a single computer. Also, an ability to boot up and shut down these expanders on demand may be desirable.
I am probably not entirely up to date, but the CXL memory expanders which I have seen so far were only for local use within one machine, not to be shared between machines.
CXL memory extenders are CPUs without cores.Whatever happened to CXL attached RAM? 5th Gen EPYC fully supports the technology and has even partnered with Micron for compatible modules. There's really not a "limit" for total system RAM imposed by the 12-16 channel shoreline limitation, just that you have to pay a smallish price in latency and bandwidth (still massively faster than SSD) for the CXL ram...
Let's undertake a thought experiment: We are a cloud service provider, i.e. our business is to rent out access to virtual machines. We are about to add 102,400 cores to our datacenter. How do we plan to do that? Will we add 400 sockets with 256 cores each, each of them with local memory attached? Or will we rather add 200 sockets with 512 cores and another 200 sockets with 0 cores (all of them with memory attached)?
I imagine that in this business, CXL attached memory will become attractive once it becomes possible at low price and low power consumption to attach memory nodes to more than a single computer. Also, an ability to boot up and shut down these expanders on demand may be desirable.
I am probably not entirely up to date, but the CXL memory expanders which I have seen so far were only for local use within one machine, not to be shared between machines.
igor_kavinski
Lifer
Not an issue if they really want resources shared. We have an old Dell VRTX where blades are inserted into a "mother" chassis and anything plugged into that chassis can be accessed by any of the blade servers. But it's like Nehalem era.I am probably not entirely up to date, but the CXL memory expanders which I have seen so far were only for local use within one machine, not to be shared between machines.
adroc_thurston
Diamond Member
Because memory pooling is a 2.0 thing (3.0, really, 2.0 mempools never quite worked right).I am probably not entirely up to date, but the CXL memory expanders which I have seen so far were only for local use within one machine, not to be shared between machines.
LightningZ71
Platinum Member
The spec doesn't prevent vertical cards or daughter boards with the CXL expanders on them. It doesn't have to be an empty CPU package.(moar cores per socket vs. memory capacity)
CXL memory extenders are CPUs without cores.
Let's undertake a thought experiment: We are a cloud service provider, i.e. our business is to rent out access to virtual machines. We are about to add 102,400 cores to our datacenter. How do we plan to do that? Will we add 400 sockets with 256 cores each, each of them with local memory attached? Or will we rather add 200 sockets with 512 cores and another 200 sockets with 0 cores (all of them with memory attached)?
I imagine that in this business, CXL attached memory will become attractive once it becomes possible at low price and low power consumption to attach memory nodes to more than a single computer. Also, an ability to boot up and shut down these expanders on demand may be desirable.
I am probably not entirely up to date, but the CXL memory expanders which I have seen so far were only for local use within one machine, not to be shared between machines.
Here’s a rule I’ll follow from on, I don’t watch or read the content of anyone who comes on MILD YouTube channel.
Those people are just promoting that grifter. Seriously, I miss Anandtech. 🙁
People like HUB, Kit, level1tech, are just promoting him and his way of conducting business. You’ve seen that’s guys influence already on these stupid tech sites that publish anything
You seem to have unhealthy obsession about MLID. I think he provides valuable service.
poke01
Diamond Member
Unhealthy? I don’t even speak about him or his channel that regularly.You seem to have unhealthy obsession about MLID. I think he provides valuable service.
Speculation, especially with some reason that is explicitly stated by the poster is particularly interesting from my POV. It gets people to think about the art of the possible 😉.
Lots of good thoughts here IMO. Memory bandwidth per core. Core arrangements, L3 pool arrangement, Interconnect freedom, etc, etc. All of these make for great speculation.
As for cores, 256 for Venice D. Seems like there isn't much discussion against this.
Venice Classic? 92 vs 128. I am still betting on 128 simply because I can't fathom AMD moving backwards from Turin.
Where Zen 7 could significantly raise core counts, is by moving to a larger socket with more memory channels, having higher bandwidth memory (not so hard to believe for 2028->2029 timeframe).
I think it more likely that Zen 7 will increase core counts through more CCD's per socket vs more cores per CCD. As you pointed out, it is likely that the added 10% transistor budget will be used to improve IPC, not to increase core count.
Lots of good thoughts here IMO. Memory bandwidth per core. Core arrangements, L3 pool arrangement, Interconnect freedom, etc, etc. All of these make for great speculation.
As for cores, 256 for Venice D. Seems like there isn't much discussion against this.
Venice Classic? 92 vs 128. I am still betting on 128 simply because I can't fathom AMD moving backwards from Turin.
I could buy that. I completely agree that A14 isn't going to be giving huge transistor density improvements. Therefore, it stands to reason that we won't be seeing significant core count increases either (at least not within a CCD).Rumors so far suggest 264 cores, instead of Venice-D's 256, which seems believable to me precisely because the figure is so modest.
In my opinion, that points to a layout change of the dense server CCD, from 2 rows of 16 cores to a 3x11 layout.
Since there's also rumors that the L3 is wandering outside the CCD, that's not so far-fetched.
Architecturally, Zen7 is allegedly the next proper tock, with rumored 15-25% IPC uplift, which would require a substantial of additional logic transistors, probably eating up most or all the power- and transistor budget freed up by the A14 shrink, so a tiny core count bump makes sense in that regard, too.
Where Zen 7 could significantly raise core counts, is by moving to a larger socket with more memory channels, having higher bandwidth memory (not so hard to believe for 2028->2029 timeframe).
I think it more likely that Zen 7 will increase core counts through more CCD's per socket vs more cores per CCD. As you pointed out, it is likely that the added 10% transistor budget will be used to improve IPC, not to increase core count.
adroc_thurston
Diamond Member
there is no discussion, SP8 tops out a 96c.Venice Classic? 92 vs 128.
They didn't move 'backwards'.I am still betting on 128 simply because I can't fathom AMD moving backwards from Turin.
Classic big socket met Nothingness.
What did Nothingness do? 😅Classic big socket met Nothingness.
It's quite simple. It's not 3x11 because it's not anything. No logic was broken in this statement.
For mesh it doesn't make sense but neither does 2x16. For tweaked ringbus which doesn't have actual routing mesh but only one or two clients per ring stop three clients could also be manageable configuration if they change their L3 topology from pure cache to mix that 3rd core into L3 region.
adroc_thurston
Diamond Member
it is a real(tm) mesh and no, it's one core per one stop for the foreseeable future since any cache perf regression is like, extra haram.For tweaked ringbus which doesn't have actual routing mesh but only one or two clients per ring stop three clients could also be manageable configuration if they change their L3 topology from pure cache to mix that 3rd core into L3 region.
it is a real(tm) mesh and no, it's one core per one stop for the foreseeable future since any cache perf regression is like, extra haram.
I consider mesh as data routing point. Mesh point can route any packet to any stop with preferred route from routing tables and is so is pretty much freely configurable. Ring bus instead route data only to one direction and stops just harvest data coming to that stop. Because that design difference ring bus can operate at much higher frequencies at moderate power consumption. AMD designs does not have real mesh-configuration, and reason is just that they don't want give away L3 performance. And because that real mesh disadvantage Intel isn't either bringing mesh to their client product but instead will increase core count with same approach - share ring stop with multiple cores.
adroc_thurston
Diamond Member
uh, no?Mesh point can route any packet to any stop with preferred route from routing tables and is so is pretty much freely configurable
Your average Intel mesh is dimension order routed. With very-very strict rules and I/O caps having double-rows.
yeah they do.AMD designs does not have real mesh-configuration, and reason is just that they don't want give away L3 performance
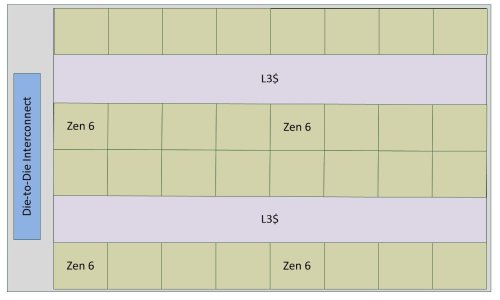
It's a mesh, and venice-D one is 4x8.
well no, it's because Intel interconnects suck.And because that real mesh disadvantage Intel isn't either bringing mesh to their client product but instead will increase core count with same approach - share ring stop with multiple cores.
Like iso CC in power-sensitive env like mobile their ring ain't clocking well anymore. too bad.
uh, no?
Your average Intel mesh is dimension order routed. With very-very strict rules and I/O caps having double-rows.
Of course they are hardware connected and optimized - but any mesh points still have three paths to solve as mesh point can route data to different paths. Ringbus doesn't need, it brings data to next stop if current stop ain't target. Ladder optimization to ringbus is trivial, instead nowadays implementation of two counterclocking rings upward and downward data paths are separated so ring ends doesn't need to go around but instead ring crossing is done at data send. We'll see if AMD goes to real mesh with Venice - and if they do how much performance they lose.
Form factor wasn't really what I had in mind, but computer topology.The spec doesn't prevent vertical cards or daughter boards with the CXL expanders on them. It doesn't have to be an empty CPU package.
(E.g. quantified by average distance between cores and memory controllers. <- edited)
Last edited:
So we are talking four rows of 8C or eight rows with 4C (latter probably looks like 4x 8C CCDs of today stitched together)?It's a mesh, and venice-D one is 4x8.
Attachments
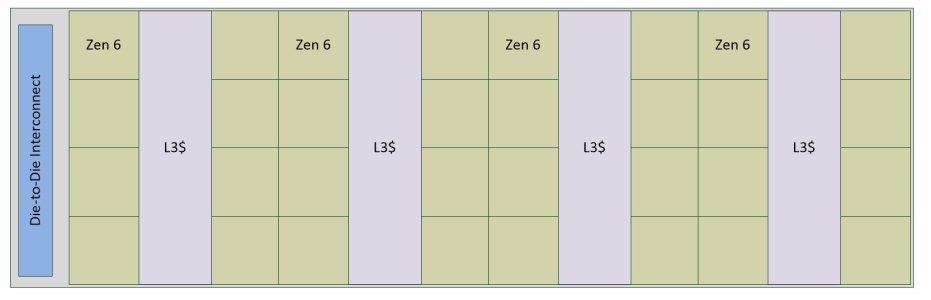
SP8 doesn't have a core limit AFAIK. It has bandwidth limitations, and PCI lane limitations. Still, what prevents AMD from producing Zen 6 classic on SP7?there is no discussion, SP8 tops out a 96c.
... and there is a discussion if I chose to have one.
Yes they did. There is simply no way to consider 96c down from 128c anything less than moving backwards.They didn't move 'backwards'.
Classic big socket met Nothingness.
adroc_thurston
Diamond Member
yeah it does.SP8 doesn't have a core limit AFAIK.
No, it has more PCIe than SP7 lmao.It has bandwidth limitations, and PCI lane limitations.
Market demand.Still, what prevents AMD from producing Zen 6 classic on SP7?
Big socket is CSP favela territory, and CSPs want dense.
Nope.Yes they did
It's 0c down from 128c.There is simply no way to consider 96c down from 128c anything less than moving backwards.
Classic big socket ceased to exist, never to re-emerge again. too bad!
Unhealthy? I don’t even speak about him or his channel that regularly.
Seems you are calling for "secondary sanctions", stop watching YouTubers who show up on MLID channel, yes, you would call it unhealthy. 🙂
CouncilorIrissa
Senior member
Backwards how? A hypothetical 128c Venice-D would likely be able to match the Turin classic in the clock speed department (considering that Turin Dense already clocks only like ~400 MHz lower, 3.7 GHz vs 4.1) while having higher PPC.Yes they did. There is simply no way to consider 96c down from 128c anything less than moving backwards.
A full cache Zen 5 exists today with 128 cores. It only makes sense for there to be a Full cache Zen 6 with at least 128 cores.Backwards how? A hypothetical 128c Venice-D would likely be able to match the Turin classic in the clock speed department (considering that Turin Dense already clocks only like ~400 MHz lower, 3.7 GHz vs 4.1) while having higher PPC.
There are loads where full cache versions of Zen will perform better than Zen c versions will. This is the reason that AMD had Venice full in the first place. Dense serves different computing needs.
Should AMD only offer 96c for Zen 6 full cache version, that would indeed be a step backwards from a full cache Zen5 with 128 cores.
Saying that Zen 6c may be as potent as Zen 5 full doesn't change things either. Zen 6 full will exist and there will be customers with loads that would do better on more cores of Zen 6 full than 96. In fact, it may well be that the 128c Turin might best the 96c Zen 6 full in quite a number of benchmarks and applications. Hard to see that as anything but a step back ..... which is also the reason I believe AMD wont be doing that. There will be (IMO) a 128c Zen 6 full cache version.
Time will tell.
branch_suggestion
Senior member
You're getting full cache Z6 with 256 cores.A full cache Zen 5 exists today with 128 cores. It only makes sense for there to be a Full cache Zen 6 with at least 128 cores.
TRENDING THREADS
-
 Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)
Discussion Zen 5 Speculation (EPYC Turin and Strix Point/Granite Ridge - Ryzen 9000)- Started by DisEnchantment
- Replies: 25K
-
Discussion Intel Meteor, Arrow, Lunar & Panther Lakes + WCL Discussion Threads
- Started by Tigerick
- Replies: 25K
-
 Discussion Intel current and future Lakes & Rapids thread
Discussion Intel current and future Lakes & Rapids thread- Started by TheF34RChannel
- Replies: 24K
-

-
