Nosta your reply is a little too far in the weeds for me to understand your meaning. Can you dumb it down a little?
It only gets to be more complex I think.

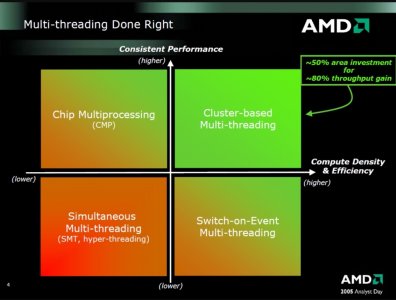
As example, Alpha 21164 has a single Ebox. Where 21264 has two Eboxes. Optimizing for Cluster-based Multithreading can allow a single core CMT2-tuned 21264 to replace a dual-core 21164. Cluster-based Multithreading is just Simultaneous Multithreading but for clusters rather than monolithic units.
Dual-core = 2x area increase for 1.7x performance increase from second thread.
CMT2 (Clustered execution core) = 1.5x area increase for 1.8x performance increase from second thread. Speed-up is from less components duplicated and lower distance overhead for MT.
Application of Cluster-based Multithreading can be switched to single-thread as a Clustered Microarchitecure w/o Multithreading.
Application of Chip-level Multithreading can not be reserved to a single-thread as it is separate units. This thus leans more into Dual-core in area and performance. As it has more components duplicated and has more distance overhead for MT.
~~~~
~~~~
Zen lineage has been transitioning over to being Bulldozer-like given the 2005 cluster-based multithreading and 2007 bulldozer slides. Which were not in the 2009+ Bulldozer design as it switched away from Cluster-based Multithreading to Chip-level Multithreading.
Zen3~5 core has flipped the clustered components from integer to floating point. Where the Integer component is shared and the FPU is clustered.
Bulldozer released (Chip-level Multithreading);
2x Retire
2x Integer Scheduler
2x Integer/Memory Execution
with a shared monolithic SMT2 FPU unit.
Bulldozer unreleased (Cluster-based Multithreading);
1x Retire
3x 2Integer/1Memory Scheduler
2x Integer Execution
1x Memory Execution
with a shared monolithic SMT2 FPU unit.
Zen5 released;
1x FP Retire
3x FP Schedulers
2x FP/SIMD Execution
1x Store/Convert Execution
with a shared monolithic SMT2 Integer unit.
// Front-end for Zen5 is basically a continuation of the front-end of Bulldozer ~ Steamroller. Where there is two fetches to two picks to two decodes.
~~~~
////\\\\
It was likely that Bulldozer Gen3 would have returned to being a cluster-based multithreading processor. By how the units were being smooshed together from BD Gen1 to BD Gen2.

There is also Zen5 having the correct integer scheduler layout for clustering.

1x Integer Execution Scheduler to 6 ALU (1x PRF 240-entry) to
2x Integer Execution Scheduler to 4 ALUs (2x PRF >128-entry) with shared memory unit AGU/LSU.
As they did the front-end, the floating point unit, it is likely to be the integer part next to be clustered.
It is purely AMD-sided that let Bulldozer launch as a chip-level multithreading part. Rather than keeping to the cluster-based multithreading part.