- Oct 9, 1999
- 5,422
- 4,151
- 136
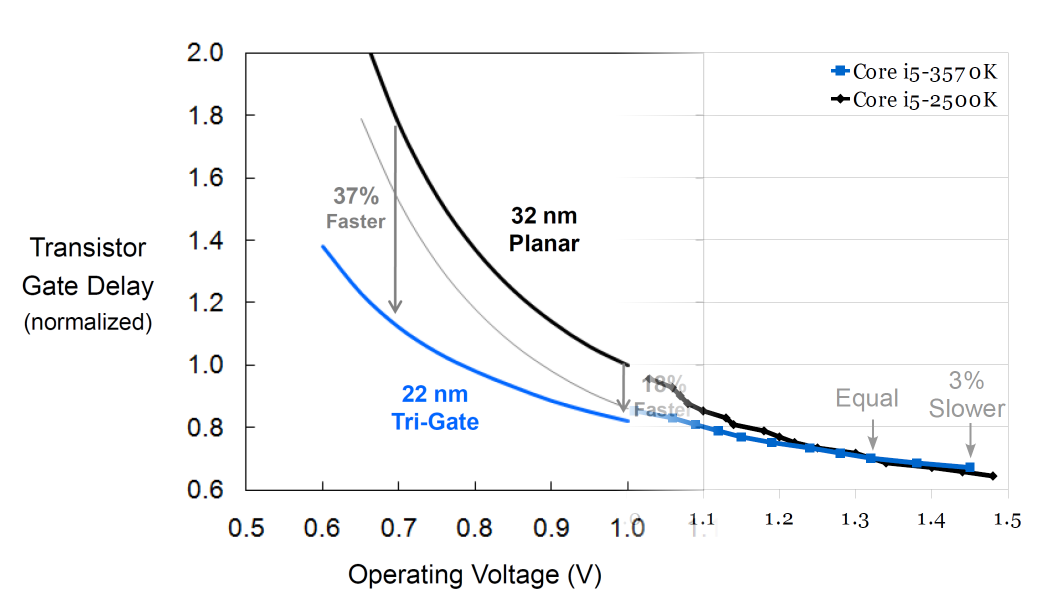
Looking at various Intel slides which show transistor switching speed and leakage it appears as though leakage has decreased with every process generation from 65>45>32>22>14nm and transistor switching speed has increased. Why have we pretty much been stalled at 4GHz or even 5GHz if you include overclocking through all of these process generations?
The only think I can think of and it's not my field is that the smaller dimensions of the parts have made it more difficult to remove heat, that is the heat generated by the part is concentrated in a very small area, so if heat transfer coefficients remain the same, even though there is less heat with each generation there is also less area to transfer it away from the die so the end result is that the parts are thermally constrained?
If this was the case then super cooled parts should be getting faster with each process shrink right? I'm thinking this because the temperature delta in this case allows for very high heat transfer.
Also, if Intel were to make a financially and power unconstrained processor, which process size would lead to the fastest part? Of the recent ones they gone though?
For example, would a 45nm Haswell part be faster or slower than a 22nm Haswell part? Assuming best yields for each process?
The only think I can think of and it's not my field is that the smaller dimensions of the parts have made it more difficult to remove heat, that is the heat generated by the part is concentrated in a very small area, so if heat transfer coefficients remain the same, even though there is less heat with each generation there is also less area to transfer it away from the die so the end result is that the parts are thermally constrained?
If this was the case then super cooled parts should be getting faster with each process shrink right? I'm thinking this because the temperature delta in this case allows for very high heat transfer.
Also, if Intel were to make a financially and power unconstrained processor, which process size would lead to the fastest part? Of the recent ones they gone though?
For example, would a 45nm Haswell part be faster or slower than a 22nm Haswell part? Assuming best yields for each process?